Gráficos y visualización de datos en Python#
La visualización es una de las mejores herramientas disponibles en el análisis de datos, ya que es la mejor forma de resumen y representación de los datos para interpretarlos y conocer la relación que guardan entre ellos.
Python dispone de diferentes librerías de visualización. Lo importante es hacer uso de aquellos gráficos que representen el cruce de datos de la mejor forma. Esto permitirá que se entienda bien el análisis que se realiza.
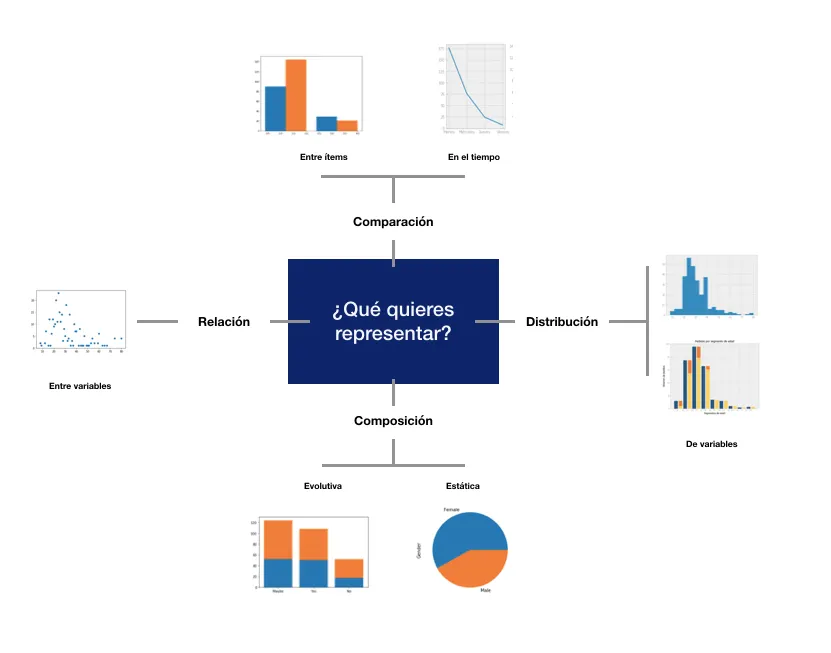
Veamos las librerías más potentes y útiles para realizar gráficos en Python
Matplotlib#
# Vamos a instalar la librería (En Colab ya se encuentra instalada por defecto)
!pip install matplotlib
import matplotlib.pyplot as plt # El módulo pyplot es el que contiene muchos
# de los comandos importantes para graficar.
import numpy as np # Numpy es la librería para trabajar con números facilmente
%matplotlib inline
# Esta linea es para que en los notebooks, las imaágenes se
# muestren en el mismo lugar dentro del notebook
Plot#
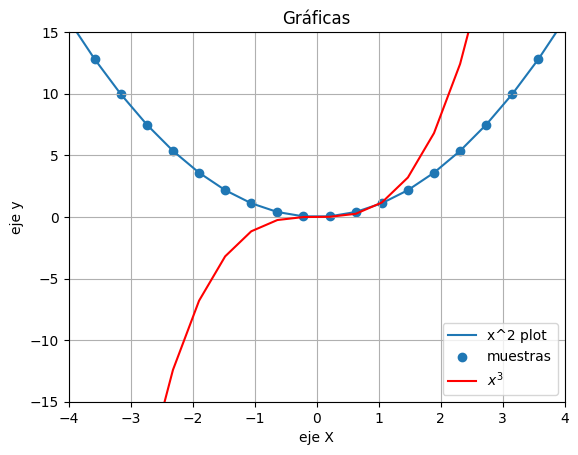
Este es el comando básico para graficar cualquier linea de puntos continua.
x = np.linspace(-4,4,20)# Creemos un vector de 20 elementos linealmente
# distribuidos desde -4 hasta 4
y=x**2 # Elevamos cada elemento del vector x al cuadrado
z=x**3 # Elevamos cada elemento del vector x al cubo
plt.plot(x, y, label="x^2 plot") # Graficamos el vector x contra el vector y
plt.scatter(x, y, label="muestras") # Graficamos el vector x contra el vector y
plt.plot(x, z, label="$x^3$", color="red") # graficamos x vs z
plt.xlim([-4,4]) # Establece límites del eje X solo se muestra desde -4 hasta 4
plt.ylim([-15, 15]) # Límites del eje y
plt.legend() # Muestra la leyenda
plt.grid(True) # Muestra una cuadrícula
plt.xlabel('eje X') # Añade el título al eje X
plt.ylabel('eje y') # Añade el título al eje Y
plt.title('Gráficas') # Añade el título al gráfico
plt.show() # Muestra el gráfico
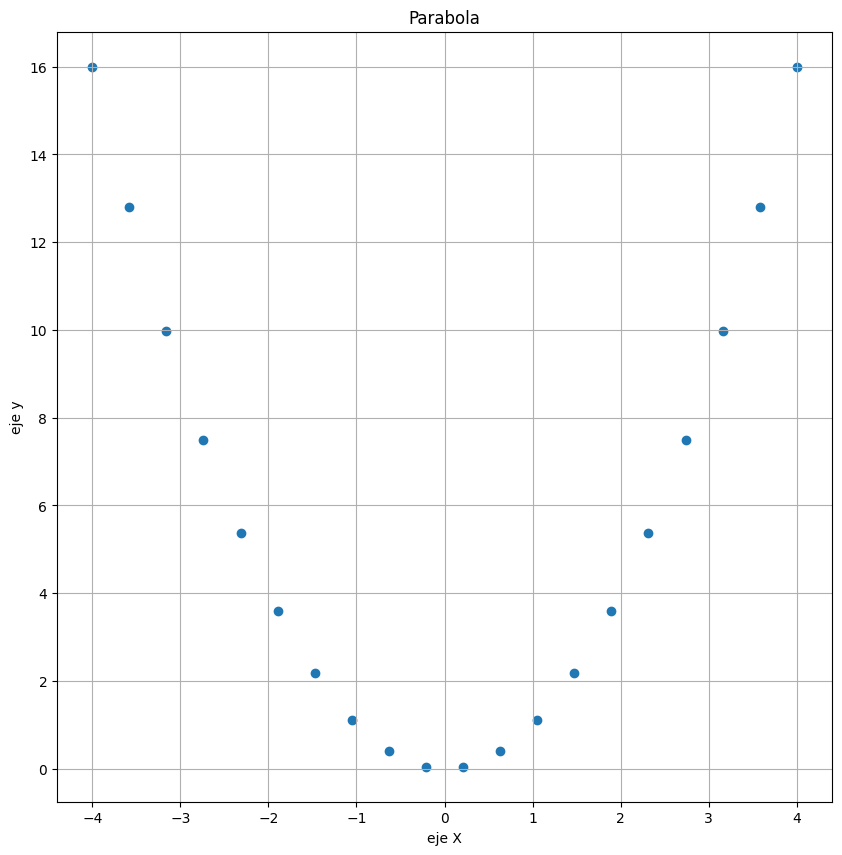
Scatter#
Este permite ver cada uno de los puntos de una serie o arreglo individualmente
x = np.linspace(-4,4,20)
y=x**2
plt.figure(figsize=(10,10)) # Este parámetro permite crear lienzos diferentes
# con un tamaño fijo para separar los gráficos.
plt.scatter(x, y)
plt.grid(True)
plt.xlabel('eje X')
plt.ylabel('eje y')
plt.title('Parabola')
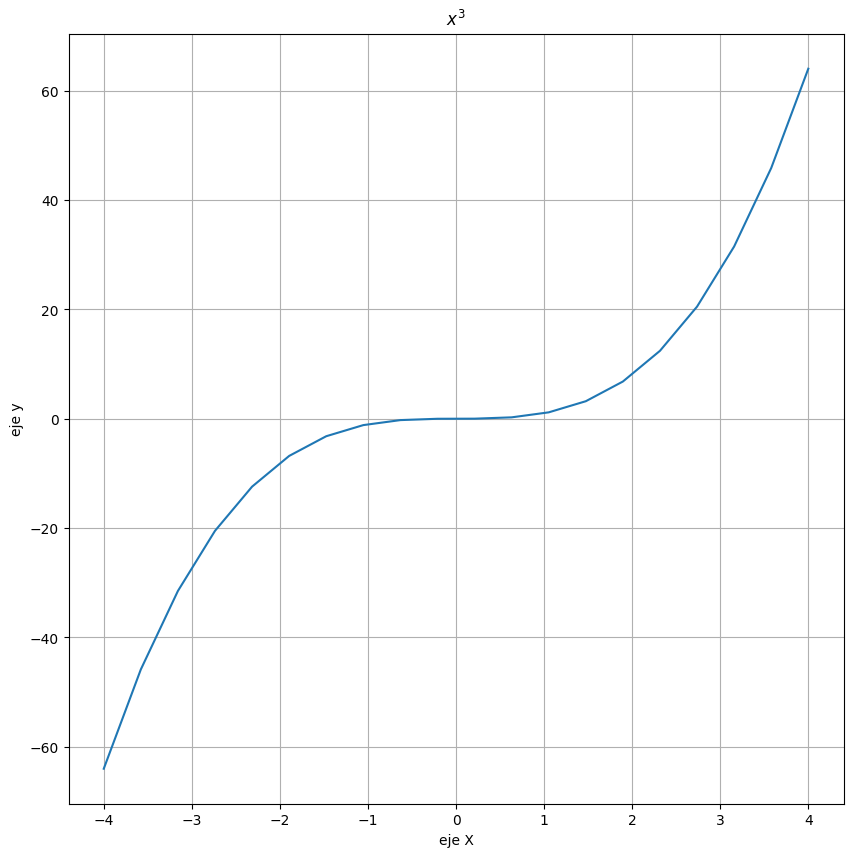
plt.figure(figsize=(10,10)) # Esto crea un nuevo lienzo y todo lo que se le de
# plot en adelante se genera en un nuevo espacio.
plt.plot(x, x**3)
plt.grid(True)
plt.xlabel('eje X')
plt.ylabel('eje y')
plt.title('$x^3$')
Text(0.5, 1.0, '$x^3$')
## Veamos algunos parámetros para modificar nuestros gráficos
import matplotlib.pyplot as plt
import numpy as np
%matplotlib inline
plt.figure(figsize=(10,10))
x = np.linspace(-4,4,10)
plt.plot(x, x**2, color="black", linewidth=6)
plt.scatter(x, x**2, c="green", s=1000)
x_r = np.linspace(-4,4,100)
x_ruido = x_r**2 + (np.random.random(x_r.shape)-0.5)*4
plt.scatter(x_r,x_ruido, c="red", alpha=0.3)
plt.grid(True)
plt.xlabel('eje X')
plt.ylabel('eje y')
plt.title('Parabola')
Text(0.5, 1.0, 'Parabola')
Color/c = permite seleccionar el color de la linea o de los puntos que se están graficando
Linewidth = Este permite modificar el grueso de la linea
s = Tamaño de los puntos que se grafican con scatter
alpha = Este parámetro me permite modificar la opacidad de los puntos
label = este es el nombre de cada linea dentro del gráfico, sirve para identificar cada trazo cuando se coloca un cuadro de leyenda.
Subplots#
Los subplots permiten en una misma figura, dividir el lienzo en secciones y a cada sección asignarle un gráfico diferente.
x=np.linspace(-4,4,100)
y=x
z=x**2
w=x**3
#plt.figure()
plt.subplot(1,3,1)
plt.plot(x,y)
plt.xlabel('ejex')
plt.ylabel('ejey')
plt.title('recta')
plt.grid()
#plt.figure()
plt.subplot(1,3,2)
plt.plot(x,z)
plt.xlabel('ejex')
plt.ylabel('ejey')
plt.title('parabola')
plt.grid()
#plt.figure()
plt.subplot(1,3,3)
plt.plot(x,w)
plt.xlabel('ejex')
plt.ylabel('ejey')
plt.title('cúbica')
plt.grid()
Ejercicio#
Realiza el gráfico de los datos que se presentan a continuación. Asigna un título a la gráfica, a los ejes, y muestra el legend para los trazos
x = np.linspace(-2*np.pi,2*np.pi,100)
y = np.sin(x)
z = np.cos(x)
# Tu código va aquí
Pandas#
Pandas proporciona dentro de su librería componentes para realizar gráficos rápidos directamente de los DataFrames. Es una herramienta potente para el análisis y visualización de los datos que estemos manipulando.
También Colab tiene una opción de gráficos recomendados, puedes explorar algunas cosas directamente allí.
# Vamos a cargar algunos datos
import pandas as pd
df = pd.read_csv("https://raw.githubusercontent.com/BioAITeamLearning/IntroPython_2024_01_UAI/main/Data/Food_Preference.csv")
df.head()
| Timestamp | Participant_ID | Gender | Nationality | Age | Food | Juice | Dessert | |
|---|---|---|---|---|---|---|---|---|
| 0 | 2019/05/07 2:59:13 PM GMT+8 | FPS001 | Male | Indian | 24 | Traditional food | Fresh Juice | Maybe |
| 1 | 2019/05/07 2:59:45 PM GMT+8 | FPS002 | Female | Indian | 22 | Western Food | Carbonated drinks | Yes |
| 2 | 2019/05/07 3:00:05 PM GMT+8 | FPS003 | Male | Indian | 31 | Western Food | Fresh Juice | Maybe |
| 3 | 2019/05/07 3:00:11 PM GMT+8 | FPS004 | Female | Indian | 25 | Traditional food | Fresh Juice | Maybe |
| 4 | 2019/05/07 3:02:50 PM GMT+8 | FPS005 | Male | Indian | 27 | Traditional food | Fresh Juice | Maybe |
Pie (Gráfico de torta)#
Vamos a revisar algunos datos importantes, por ejemplo, la distribución de edad de las personas.
# Normalmente en pandas lo hariamos así:
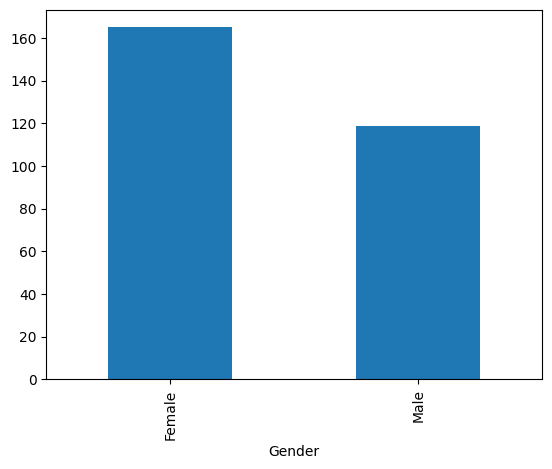
df['Gender'].value_counts()
Gender
Female 165
Male 119
Name: count, dtype: int64
# Pero si queremos realizar un informe, esta opción no es las mejor...
# veamos como hacerlo con dos simples métodos de python
df['Gender'].value_counts().plot.pie(autopct='%1.1f%%')
# El parametro, autopct agrega el porcentaje automático de cada clase
<Axes: ylabel='count'>
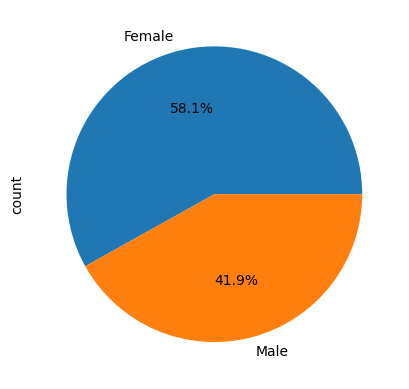
Gráfico de barras#
df['Gender'].value_counts().plot.bar() # Con solo encadenar un método de plot.
<Axes: xlabel='Gender'>
# Veamos la distribución de la columna nacionalidad en el dataset
df['Nationality'].value_counts().plot.bar()
<Axes: xlabel='Nationality'>
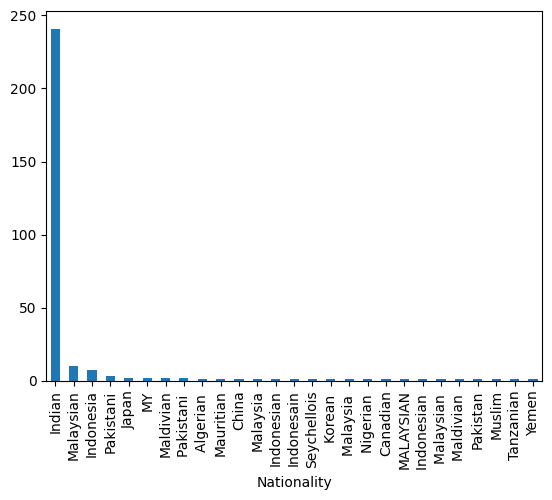
Visualizaciones combinadas pandas/matplotlib: Caso data Analytics#
# Importemos las librerías que necesitaremos
import pandas as pd
import matplotlib.pyplot as plt
Craga Preprocesamiento de la data#
df = pd.read_csv('https://raw.githubusercontent.com/BioAITeamLearning/IntroPython_2024_01_UAI/main/Data/Food_Preference.csv')
df = df.dropna() # Eliminamos los valores nulos
df.head()
| Timestamp | Participant_ID | Gender | Nationality | Age | Food | Juice | Dessert | |
|---|---|---|---|---|---|---|---|---|
| 0 | 2019/05/07 2:59:13 PM GMT+8 | FPS001 | Male | Indian | 24 | Traditional food | Fresh Juice | Maybe |
| 1 | 2019/05/07 2:59:45 PM GMT+8 | FPS002 | Female | Indian | 22 | Western Food | Carbonated drinks | Yes |
| 2 | 2019/05/07 3:00:05 PM GMT+8 | FPS003 | Male | Indian | 31 | Western Food | Fresh Juice | Maybe |
| 3 | 2019/05/07 3:00:11 PM GMT+8 | FPS004 | Female | Indian | 25 | Traditional food | Fresh Juice | Maybe |
| 4 | 2019/05/07 3:02:50 PM GMT+8 | FPS005 | Male | Indian | 27 | Traditional food | Fresh Juice | Maybe |
Manipulación de fechas#
Esta columna de Timestamp tiene un formato de fechas, pero no está casteado en tipo fecha, por lo que debemos decirle a pandas que lo trate como fechas para poder luego hacer algunas operaciones especiales para este tipo de datos.
df['Date'] = pd.to_datetime(df['Timestamp'])
<ipython-input-35-d0a3a53dbc13>:1: UserWarning: Could not infer format, so each element will be parsed individually, falling back to `dateutil`. To ensure parsing is consistent and as-expected, please specify a format.
df['Date'] = pd.to_datetime(df['Timestamp'])
df['Day'] = df.Date.dt.day
df.head()
| Timestamp | Participant_ID | Gender | Nationality | Age | Food | Juice | Dessert | Date | Day | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2019/05/07 2:59:13 PM GMT+8 | FPS001 | Male | Indian | 24 | Traditional food | Fresh Juice | Maybe | 2019-05-07 14:59:13-08:00 | 7 |
| 1 | 2019/05/07 2:59:45 PM GMT+8 | FPS002 | Female | Indian | 22 | Western Food | Carbonated drinks | Yes | 2019-05-07 14:59:45-08:00 | 7 |
| 2 | 2019/05/07 3:00:05 PM GMT+8 | FPS003 | Male | Indian | 31 | Western Food | Fresh Juice | Maybe | 2019-05-07 15:00:05-08:00 | 7 |
| 3 | 2019/05/07 3:00:11 PM GMT+8 | FPS004 | Female | Indian | 25 | Traditional food | Fresh Juice | Maybe | 2019-05-07 15:00:11-08:00 | 7 |
| 4 | 2019/05/07 3:02:50 PM GMT+8 | FPS005 | Male | Indian | 27 | Traditional food | Fresh Juice | Maybe | 2019-05-07 15:02:50-08:00 | 7 |
Vamos a realizar gráficas con matplotlib.#
# Vamos a cambiar el estilo plano de nuestras gráficas
# En el siguiente enlace encuentras más estilos
# https://matplotlib.org/stable/gallery/style_sheets/style_sheets_reference.html
plt.style.use('ggplot')
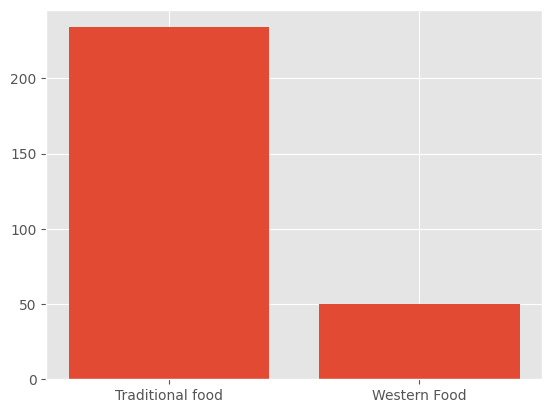
Tipos de comida#
vamos a revisar como hacer un gráfico de barras para esta columna pero con matplotlib.
x_values = df['Food'].unique()
y_values = df['Food'].value_counts().tolist()
x_values
array(['Traditional food', 'Western Food'], dtype=object)
y_values
[234, 50]
plt.bar(x_values, y_values)
plt.show()
plt.close('all')
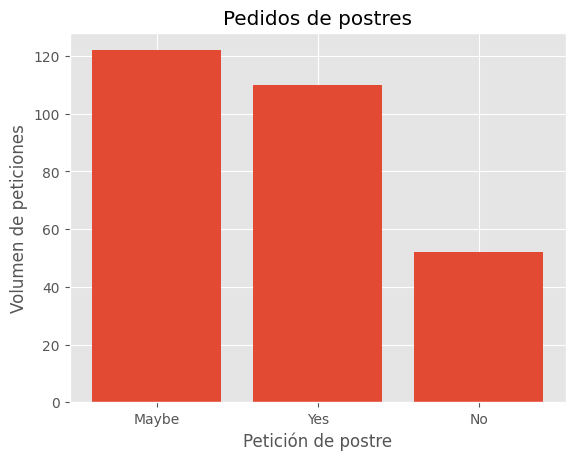
Tipos de postre#
Veamos cómo modificar algunos parámetros de la imágen
x_values = df.Dessert.unique()
y_values = df.Dessert.value_counts().tolist()
plt.figure() #Figura. Puede incluirse el tamaño con figsize
plt.bar(x_values, y_values) #El gráfico
plt.title('Pedidos de postres') #El título
ax = plt.subplot() #Axis
ax.set_xticks(x_values) #Eje x
ax.set_xticklabels(x_values) #Etiquetas del eje x
ax.set_xlabel('Petición de postre') #Nombre del eje x
ax.set_ylabel('Volumen de peticiones') #Nombre del eje y
plt.show()
plt.close('all')
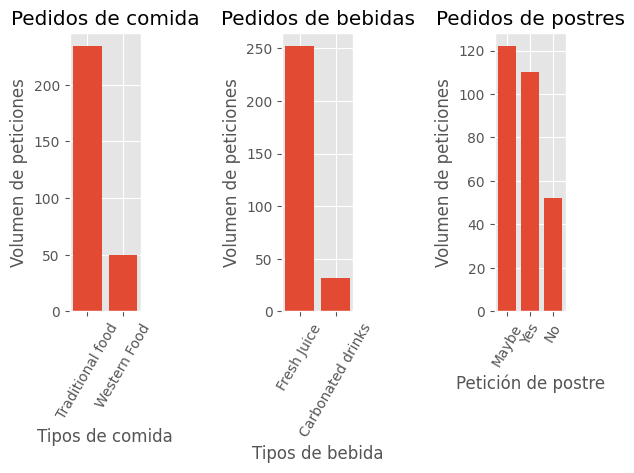
Comida, Bebidas y postres#
Veamos como colocar varios gráficos en una sola imágen
plt.figure() #Figura. Puede incluirse el tamaño con figsize
x_values1 = df.Food.unique()
y_values1 = df.Food.value_counts().tolist()
ax = plt.subplot(1, 3, 1) #Axis
plt.bar(x_values1, y_values1) #El gráfico
plt.title('Pedidos de comida') #El título
ax.set_xticks(x_values1) #Eje x
ax.set_xticklabels(x_values1, rotation=60) #Etiquetas del eje x
ax.set_xlabel('Tipos de comida') #Nombre del eje x
ax.set_ylabel('Volumen de peticiones') #Nombre del eje y
x_values2 = df.Juice.unique()
y_values2 = df.Juice.value_counts().tolist()
ax = plt.subplot(1, 3, 2) #Axis
plt.bar(x_values2, y_values2) #El gráfico
plt.title('Pedidos de bebidas') #El título
ax.set_xticks(x_values2) #Eje x
ax.set_xticklabels(x_values2, rotation=60) #Etiquetas del eje x
ax.set_xlabel('Tipos de bebida') #Nombre del eje x
ax.set_ylabel('Volumen de peticiones') #Nombre del eje y
x_values3 = df.Dessert.unique()
y_values3 = df.Dessert.value_counts().tolist()
ax = plt.subplot(1, 3, 3) #Axis
plt.bar(x_values3, y_values3) #El gráfico
plt.title('Pedidos de postres') #El título
ax.set_xticks(x_values3) #Eje x
ax.set_xticklabels(x_values3, rotation=60) #Etiquetas del eje x
ax.set_xlabel('Petición de postre') #Nombre del eje x
ax.set_ylabel('Volumen de peticiones') #Nombre del eje y
plt.subplots_adjust(wspace=2, bottom=0.3) # Ajuste de el espacio entre cada plot
plt.show()
plt.close('all')
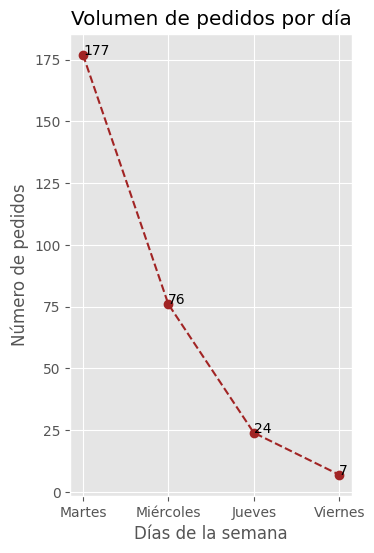
Ordenes por día#
Vamos a revisar como agrupar los datos del dataframe por la columna días y graficar información.
x_values5 = ['Martes', 'Miércoles', 'Jueves', 'Viernes']
y_values5 = df['Day'].value_counts().tolist()
x_values5
['Martes', 'Miércoles', 'Jueves', 'Viernes']
y_values5
[177, 76, 24, 7]
plt.figure(figsize=(8, 6))
ax = plt.subplot(1, 2, 1)
plt.plot(x_values5, y_values5, color='#a12424', linestyle='--', marker='o')
plt.title('Volumen de pedidos por día')
ax.set_xlabel('Días de la semana') #Nombre del eje x
ax.set_ylabel('Número de pedidos') #Nombre del eje y
for i, txt in enumerate(y_values5): # Con esto podemos agregarle los valores especificos en el gráfico al lado de cada punto
ax.annotate(txt, (x_values5[i], y_values5[i]))
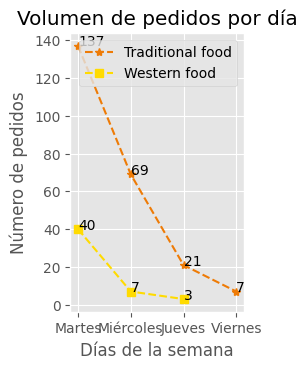
y_values6 = df[(df['Food'] == 'Traditional food')]['Day'].value_counts().tolist()
y_values7 = df[(df['Food'] == 'Western Food')]['Day'].value_counts().tolist()
y_values6
[137, 69, 21, 7]
y_values7
[40, 7, 3]
ax = plt.subplot(1, 2, 2)
plt.plot(x_values5, y_values6, color='#ee7b06', linestyle='--', marker='*')
plt.plot(y_values7, color='#ffdb00', linestyle='--', marker='s')
plt.title('Volumen de pedidos por día')
plt.legend(['Traditional food', 'Western food'], loc=1)
ax.set_xlabel('Días de la semana') #Nombre del eje x
ax.set_ylabel('Número de pedidos') #Nombre del eje y
for i, txt in enumerate(y_values6):
ax.annotate(txt, (x_values5[i], y_values6[i]))
for i, txt in enumerate(y_values7):
ax.annotate(txt, (x_values5[i], y_values7[i]))
plt.subplots_adjust(wspace=0.85, bottom=0.3)
plt.show()
plt.close('all')
plt.figure()
plt.subplot(1, 2, 1)
plt.plot(x_values5, y_values5)
plt.subplot(1, 2, 2)
plt.plot(x_values5, y_values6)
plt.plot(y_values7)
[<matplotlib.lines.Line2D at 0x79e7bd919fc0>]
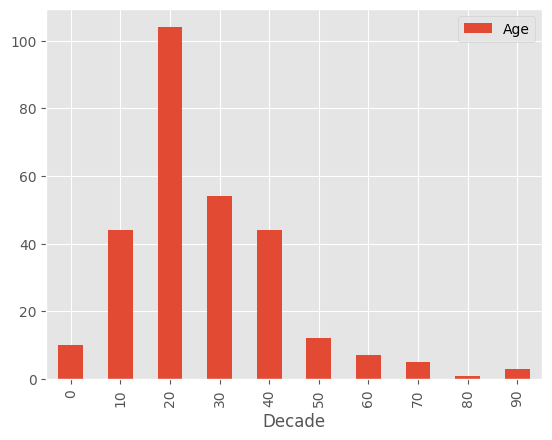
Edades#
Revisemos la distribución de edades, como la edad es continua, debemos encontrar una forma de agrupar la información.
df["Decade"] = pd.cut(df.Age, 10, labels=range(0,100,10)) # Permite cortar los datos de una serie y agruparlos por partes discretas
df.head()
| Timestamp | Participant_ID | Gender | Nationality | Age | Food | Juice | Dessert | Date | Day | Decade | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2019/05/07 2:59:13 PM GMT+8 | FPS001 | Male | Indian | 24 | Traditional food | Fresh Juice | Maybe | 2019-05-07 14:59:13-08:00 | 7 | 20 |
| 1 | 2019/05/07 2:59:45 PM GMT+8 | FPS002 | Female | Indian | 22 | Western Food | Carbonated drinks | Yes | 2019-05-07 14:59:45-08:00 | 7 | 10 |
| 2 | 2019/05/07 3:00:05 PM GMT+8 | FPS003 | Male | Indian | 31 | Western Food | Fresh Juice | Maybe | 2019-05-07 15:00:05-08:00 | 7 | 30 |
| 3 | 2019/05/07 3:00:11 PM GMT+8 | FPS004 | Female | Indian | 25 | Traditional food | Fresh Juice | Maybe | 2019-05-07 15:00:11-08:00 | 7 | 20 |
| 4 | 2019/05/07 3:02:50 PM GMT+8 | FPS005 | Male | Indian | 27 | Traditional food | Fresh Juice | Maybe | 2019-05-07 15:02:50-08:00 | 7 | 20 |
df.groupby("Decade").agg({"Age": "count"}).plot.bar()
<Axes: xlabel='Decade'>
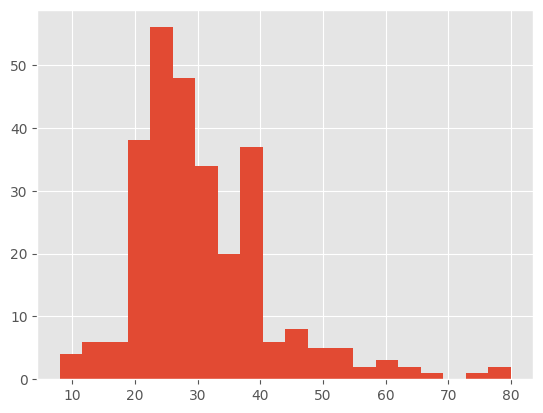
plt.hist(df.Age, bins=20) # Similar, pero sin tener que realizar tantos filtros
(array([ 4., 6., 6., 38., 56., 48., 34., 20., 37., 6., 8., 5., 5.,
2., 3., 2., 1., 0., 1., 2.]),
array([ 8. , 11.6, 15.2, 18.8, 22.4, 26. , 29.6, 33.2, 36.8, 40.4, 44. ,
47.6, 51.2, 54.8, 58.4, 62. , 65.6, 69.2, 72.8, 76.4, 80. ]),
<BarContainer object of 20 artists>)
Seaborn#
Seaborn es otra libreria de visualización que se integra con pandas para crear visualizaciones más intuitivas que matplotlib
Veamos algunas visualizaciones para el mismo set de datos
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns # Esta es la librería,en adelante tendrá el "apodo" de sns
# Tratamiento de datos que hicimos antes
df = pd.read_csv('https://raw.githubusercontent.com/BioAITeamLearning/IntroPython_2024_01_UAI/main/Data/Food_Preference.csv')
df = df.dropna() # Eliminamos los valores nulos
df.head()
| Timestamp | Participant_ID | Gender | Nationality | Age | Food | Juice | Dessert | |
|---|---|---|---|---|---|---|---|---|
| 0 | 2019/05/07 2:59:13 PM GMT+8 | FPS001 | Male | Indian | 24 | Traditional food | Fresh Juice | Maybe |
| 1 | 2019/05/07 2:59:45 PM GMT+8 | FPS002 | Female | Indian | 22 | Western Food | Carbonated drinks | Yes |
| 2 | 2019/05/07 3:00:05 PM GMT+8 | FPS003 | Male | Indian | 31 | Western Food | Fresh Juice | Maybe |
| 3 | 2019/05/07 3:00:11 PM GMT+8 | FPS004 | Female | Indian | 25 | Traditional food | Fresh Juice | Maybe |
| 4 | 2019/05/07 3:02:50 PM GMT+8 | FPS005 | Male | Indian | 27 | Traditional food | Fresh Juice | Maybe |
df['Date'] = pd.to_datetime(df['Timestamp'])
df['Day'] = df.Date.dt.day
df.head()
<ipython-input-77-ad6862c4cc05>:1: UserWarning: Could not infer format, so each element will be parsed individually, falling back to `dateutil`. To ensure parsing is consistent and as-expected, please specify a format.
df['Date'] = pd.to_datetime(df['Timestamp'])
| Timestamp | Participant_ID | Gender | Nationality | Age | Food | Juice | Dessert | Date | Day | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2019/05/07 2:59:13 PM GMT+8 | FPS001 | Male | Indian | 24 | Traditional food | Fresh Juice | Maybe | 2019-05-07 14:59:13-08:00 | 7 |
| 1 | 2019/05/07 2:59:45 PM GMT+8 | FPS002 | Female | Indian | 22 | Western Food | Carbonated drinks | Yes | 2019-05-07 14:59:45-08:00 | 7 |
| 2 | 2019/05/07 3:00:05 PM GMT+8 | FPS003 | Male | Indian | 31 | Western Food | Fresh Juice | Maybe | 2019-05-07 15:00:05-08:00 | 7 |
| 3 | 2019/05/07 3:00:11 PM GMT+8 | FPS004 | Female | Indian | 25 | Traditional food | Fresh Juice | Maybe | 2019-05-07 15:00:11-08:00 | 7 |
| 4 | 2019/05/07 3:02:50 PM GMT+8 | FPS005 | Male | Indian | 27 | Traditional food | Fresh Juice | Maybe | 2019-05-07 15:02:50-08:00 | 7 |
sns.set_style("darkgrid") # Seleccionamos un estilo
# Más estilos en: https://interactivechaos.com/es/manual/tutorial-de-seaborn/estilos-disponibles
sns.set_context("paper") # El contexto es para que la gráfica mejore la presentación y calidad dependiendo de donde la asignemos finalmente
#otras opciones: notebook, talk, poster
sns.set_palette("deep") # Seleccionamos la paleta de colores
# Más opciones en: https://seaborn.pydata.org/tutorial/color_palettes.html
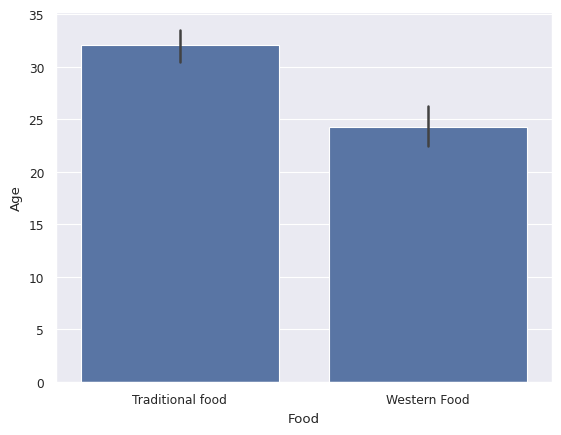
# Gráfico de barras simple para edad vs edad
sns.barplot(x='Food', y='Age', data=df)
<Axes: xlabel='Food', ylabel='Age'>
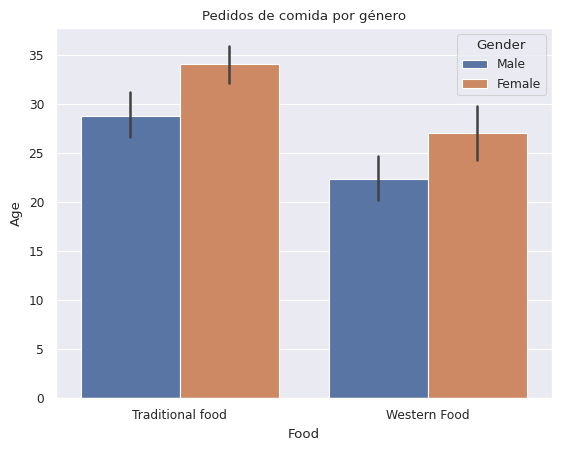
# Usando hue para agregar por género y ci podría cambiarse de mean a sd
ax = sns.barplot(x='Food', y='Age', hue='Gender', data=df)
plt.title('Pedidos de comida por género')
Text(0.5, 1.0, 'Pedidos de comida por género')
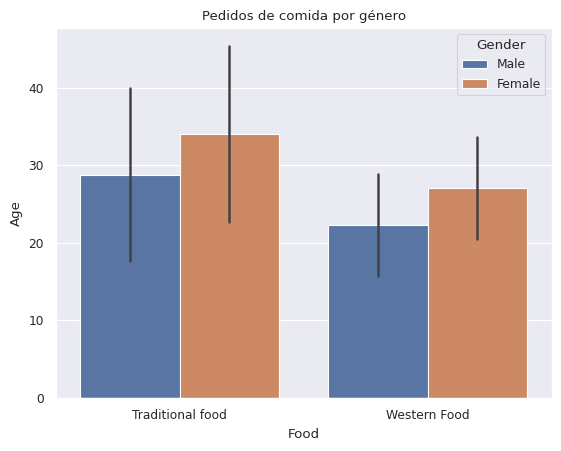
# las barras verticales son las medidas de dispersión de las columnas y se
# pueden cambiar de mean que es por defecto a desv. std
ax = sns.barplot(x='Food', y='Age', hue='Gender', data=df, ci='sd')
plt.title('Pedidos de comida por género')
plt.show()
<ipython-input-99-6bc0bfea6118>:3: FutureWarning:
The `ci` parameter is deprecated. Use `errorbar='sd'` for the same effect.
ax = sns.barplot(x='Food', y='Age', hue='Gender', data=df, ci='sd')
# Histogramas
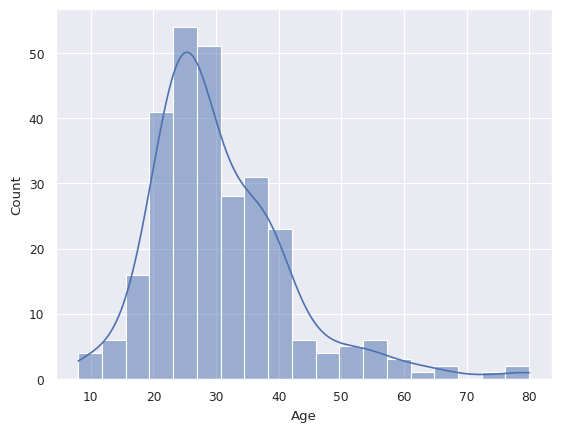
sns.histplot(df['Age'],kde=True)
## Kde añade la estimación de densidad del histograma
<Axes: xlabel='Age', ylabel='Count'>
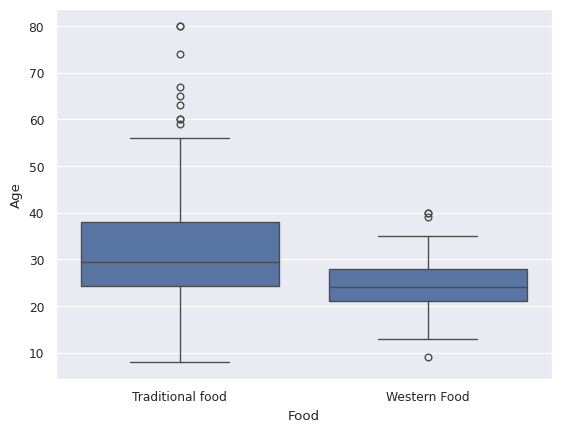
# Boxplot
sns.boxplot(x='Food', y='Age', data=df)
<Axes: xlabel='Food', ylabel='Age'>
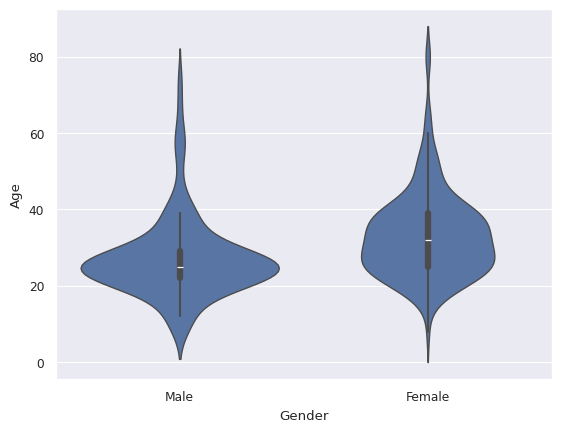
#Violinplot
sns.violinplot(data=df, x='Gender', y='Age')
<Axes: xlabel='Gender', ylabel='Age'>
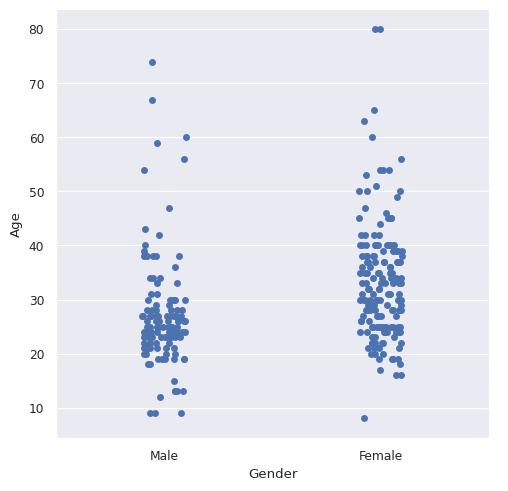
# Graficos de datos categoricos
sns.catplot(x='Gender', y='Age', data=df, kind='strip')
<seaborn.axisgrid.FacetGrid at 0x79e7b750ef20>
# Agregando una caracterización del color de los puntos
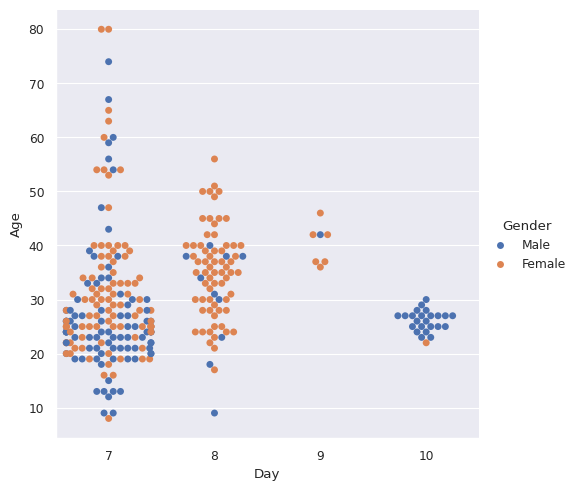
sns.catplot(x='Day', y='Age', hue='Gender', kind="swarm", data=df)
/usr/local/lib/python3.10/dist-packages/seaborn/categorical.py:3398: UserWarning: 13.0% of the points cannot be placed; you may want to decrease the size of the markers or use stripplot.
warnings.warn(msg, UserWarning)
/usr/local/lib/python3.10/dist-packages/seaborn/categorical.py:3398: UserWarning: 18.6% of the points cannot be placed; you may want to decrease the size of the markers or use stripplot.
warnings.warn(msg, UserWarning)
<seaborn.axisgrid.FacetGrid at 0x79e7b73ed3f0>
Gráficas linea o de series de tiempo#
Los gráficos de líneas muestran cambios a lo largo del tiempo para una entidad. Con nuestro conjunto de datos, un gráfico de líneas podría usarse para mostrar la tendencia de despidos durante el último año o dos. Esto depende de lo que estés tratando de comunicar, pero trabajaremos con un análisis de un año.
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
df = pd.read_csv("https://raw.githubusercontent.com/fivethirtyeight/data/master/college-majors/recent-grads.csv")
df.head()
| Rank | Major_code | Major | Total | Men | Women | Major_category | ShareWomen | Sample_size | Employed | ... | Part_time | Full_time_year_round | Unemployed | Unemployment_rate | Median | P25th | P75th | College_jobs | Non_college_jobs | Low_wage_jobs | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2419 | PETROLEUM ENGINEERING | 2339.0 | 2057.0 | 282.0 | Engineering | 0.120564 | 36 | 1976 | ... | 270 | 1207 | 37 | 0.018381 | 110000 | 95000 | 125000 | 1534 | 364 | 193 |
| 1 | 2 | 2416 | MINING AND MINERAL ENGINEERING | 756.0 | 679.0 | 77.0 | Engineering | 0.101852 | 7 | 640 | ... | 170 | 388 | 85 | 0.117241 | 75000 | 55000 | 90000 | 350 | 257 | 50 |
| 2 | 3 | 2415 | METALLURGICAL ENGINEERING | 856.0 | 725.0 | 131.0 | Engineering | 0.153037 | 3 | 648 | ... | 133 | 340 | 16 | 0.024096 | 73000 | 50000 | 105000 | 456 | 176 | 0 |
| 3 | 4 | 2417 | NAVAL ARCHITECTURE AND MARINE ENGINEERING | 1258.0 | 1123.0 | 135.0 | Engineering | 0.107313 | 16 | 758 | ... | 150 | 692 | 40 | 0.050125 | 70000 | 43000 | 80000 | 529 | 102 | 0 |
| 4 | 5 | 2405 | CHEMICAL ENGINEERING | 32260.0 | 21239.0 | 11021.0 | Engineering | 0.341631 | 289 | 25694 | ... | 5180 | 16697 | 1672 | 0.061098 | 65000 | 50000 | 75000 | 18314 | 4440 | 972 |
5 rows × 21 columns
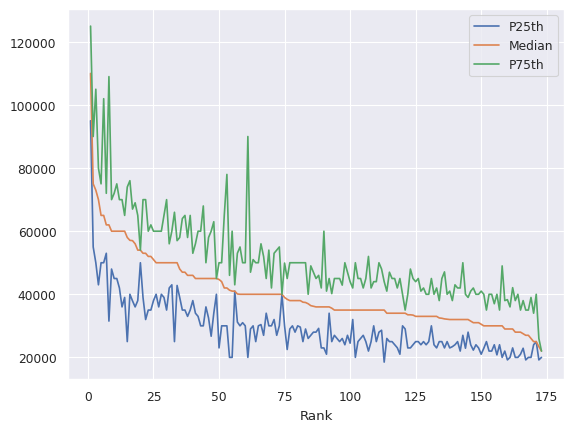
df.plot(x="Rank", y=["P25th", "Median", "P75th"]) # Esta es la forma más fácil de visualizar datos en series de tiempo.
<Axes: xlabel='Rank'>
Manejo de series de tiempo#
Manipulación del DF para ajustar fechas#
# Podrás cargar distintos dataset en nuevas variables
d = pd.read_csv("https://raw.githubusercontent.com/BioAITeamLearning/IntroPython_2024_01_UAI/main/Data/comptagevelo2009.csv")
d.head(18)
| Date | Unnamed: 1 | Berri1 | Maisonneuve_1 | Maisonneuve_2 | Brébeuf | |
|---|---|---|---|---|---|---|
| 0 | 01/01/2009 | 00:00 | 29 | 20 | 35 | NaN |
| 1 | 02/01/2009 | 00:00 | 19 | 3 | 22 | NaN |
| 2 | 03/01/2009 | 00:00 | 24 | 12 | 22 | NaN |
| 3 | 04/01/2009 | 00:00 | 24 | 8 | 15 | NaN |
| 4 | 05/01/2009 | 00:00 | 120 | 111 | 141 | NaN |
| 5 | 06/01/2009 | 00:00 | 261 | 146 | 236 | NaN |
| 6 | 07/01/2009 | 00:00 | 60 | 33 | 80 | NaN |
| 7 | 08/01/2009 | 00:00 | 24 | 14 | 14 | NaN |
| 8 | 09/01/2009 | 00:00 | 35 | 20 | 32 | NaN |
| 9 | 10/01/2009 | 00:00 | 81 | 45 | 79 | NaN |
| 10 | 11/01/2009 | 00:00 | 318 | 160 | 306 | NaN |
| 11 | 12/01/2009 | 00:00 | 105 | 99 | 170 | NaN |
| 12 | 13/01/2009 | 00:00 | 168 | 94 | 172 | NaN |
| 13 | 14/01/2009 | 00:00 | 145 | 87 | 175 | NaN |
| 14 | 15/01/2009 | 00:00 | 131 | 90 | 172 | NaN |
| 15 | 16/01/2009 | 00:00 | 93 | 49 | 97 | NaN |
| 16 | 17/01/2009 | 00:00 | 25 | 13 | 20 | NaN |
| 17 | 18/01/2009 | 00:00 | 52 | 22 | 55 | NaN |
# Convertir la columna Date, como los índices del dataframe
d.index = pd.to_datetime(d.Date, format="%d/%m/%Y")
d.index
DatetimeIndex(['2009-01-01', '2009-01-02', '2009-01-03', '2009-01-04',
'2009-01-05', '2009-01-06', '2009-01-07', '2009-01-08',
'2009-01-09', '2009-01-10',
...
'2009-12-22', '2009-12-23', '2009-12-24', '2009-12-25',
'2009-12-26', '2009-12-27', '2009-12-28', '2009-12-29',
'2009-12-30', '2009-12-31'],
dtype='datetime64[ns]', name='Date', length=365, freq=None)
del(d['Date']) # Eliminamos la columna Date
del(d["Unnamed: 1"]) # Eliminamos la columna Unnamed: 1
d.head()
| Berri1 | Maisonneuve_1 | Maisonneuve_2 | Brébeuf | |
|---|---|---|---|---|
| Date | ||||
| 2009-01-01 | 29 | 20 | 35 | NaN |
| 2009-01-02 | 19 | 3 | 22 | NaN |
| 2009-01-03 | 24 | 12 | 22 | NaN |
| 2009-01-04 | 24 | 8 | 15 | NaN |
| 2009-01-05 | 120 | 111 | 141 | NaN |
# Renombrar todas las columnas
d.columns=["Berri", "Mneuve1", "Mneuve2", "Brebeuf"]
d.head()
| Berri | Mneuve1 | Mneuve2 | Brebeuf | |
|---|---|---|---|---|
| Date | ||||
| 2009-01-01 | 29 | 20 | 35 | NaN |
| 2009-01-02 | 19 | 3 | 22 | NaN |
| 2009-01-03 | 24 | 12 | 22 | NaN |
| 2009-01-04 | 24 | 8 | 15 | NaN |
| 2009-01-05 | 120 | 111 | 141 | NaN |
for col in d.columns:
print(col, np.sum(pd.isnull(d[col])))
Berri 0
Mneuve1 0
Mneuve2 0
Brebeuf 187
# Rellenar los valores de las columnas con la media
d.Brebeuf.fillna(d.Brebeuf.mean(), inplace=True)
# Reorganizar el dataframe, organizandolo por orden de fechas
d.sort_index(inplace=True)
d.head(20)
| Berri | Mneuve1 | Mneuve2 | Brebeuf | |
|---|---|---|---|---|
| Date | ||||
| 2009-01-01 | 29 | 20 | 35 | 2576.359551 |
| 2009-01-02 | 19 | 3 | 22 | 2576.359551 |
| 2009-01-03 | 24 | 12 | 22 | 2576.359551 |
| 2009-01-04 | 24 | 8 | 15 | 2576.359551 |
| 2009-01-05 | 120 | 111 | 141 | 2576.359551 |
| 2009-01-06 | 261 | 146 | 236 | 2576.359551 |
| 2009-01-07 | 60 | 33 | 80 | 2576.359551 |
| 2009-01-08 | 24 | 14 | 14 | 2576.359551 |
| 2009-01-09 | 35 | 20 | 32 | 2576.359551 |
| 2009-01-10 | 81 | 45 | 79 | 2576.359551 |
| 2009-01-11 | 318 | 160 | 306 | 2576.359551 |
| 2009-01-12 | 105 | 99 | 170 | 2576.359551 |
| 2009-01-13 | 168 | 94 | 172 | 2576.359551 |
| 2009-01-14 | 145 | 87 | 175 | 2576.359551 |
| 2009-01-15 | 131 | 90 | 172 | 2576.359551 |
| 2009-01-16 | 93 | 49 | 97 | 2576.359551 |
| 2009-01-17 | 25 | 13 | 20 | 2576.359551 |
| 2009-01-18 | 52 | 22 | 55 | 2576.359551 |
| 2009-01-19 | 136 | 127 | 202 | 2576.359551 |
| 2009-01-20 | 147 | 85 | 176 | 2576.359551 |
# Visualizar la cantidad de elementos, ahora que ya se rellenó con la media, se tienen todos los 365 valores
d.count()
Berri 365
Mneuve1 365
Mneuve2 365
Brebeuf 365
dtype: int64
# Seleccionar datos para un rango de fechas
d.loc["2009-10-01":"2009-10-10"]
| Berri | Mneuve1 | Mneuve2 | Brebeuf | |
|---|---|---|---|---|
| Date | ||||
| 2009-10-01 | 2643 | 22 | 3528 | 1588.0 |
| 2009-10-02 | 2865 | 36 | 3735 | 1906.0 |
| 2009-10-03 | 993 | 7 | 1362 | 705.0 |
| 2009-10-04 | 1336 | 0 | 1620 | 1116.0 |
| 2009-10-05 | 2935 | 308 | 3801 | 1773.0 |
| 2009-10-06 | 3852 | 7 | 4610 | 2211.0 |
| 2009-10-07 | 2115 | 3 | 2825 | 984.0 |
| 2009-10-08 | 3336 | 9 | 4146 | 1967.0 |
| 2009-10-09 | 1302 | 482 | 1686 | 663.0 |
| 2009-10-10 | 1407 | 725 | 1443 | 1003.0 |
# Organizar los datos según la columna Berri de menor a mayor
d.sort_values(by="Berri").head(100)
| Berri | Mneuve1 | Mneuve2 | Brebeuf | |
|---|---|---|---|---|
| Date | ||||
| 2009-04-11 | 0 | 0 | 0 | 2576.359551 |
| 2009-03-31 | 0 | 0 | 0 | 2576.359551 |
| 2009-04-04 | 0 | 0 | 0 | 2576.359551 |
| 2009-04-05 | 0 | 0 | 0 | 2576.359551 |
| 2009-04-06 | 0 | 0 | 0 | 2576.359551 |
| ... | ... | ... | ... | ... |
| 2009-12-22 | 207 | 107 | 353 | 0.000000 |
| 2009-01-27 | 209 | 119 | 221 | 2576.359551 |
| 2009-02-13 | 209 | 127 | 222 | 2576.359551 |
| 2009-12-18 | 214 | 119 | 373 | 0.000000 |
| 2009-12-10 | 219 | 110 | 363 | 0.000000 |
100 rows × 4 columns
# Organizar los datos según la columna Berri de mayor a menor (parámetro ascending=False), y localidar sólo en rango fechas
d.sort_values(by="Berri",ascending=False).loc["2009-10-01":"2009-10-10"]
| Berri | Mneuve1 | Mneuve2 | Brebeuf | |
|---|---|---|---|---|
| Date | ||||
| 2009-10-06 | 3852 | 7 | 4610 | 2211.0 |
| 2009-10-08 | 3336 | 9 | 4146 | 1967.0 |
| 2009-10-05 | 2935 | 308 | 3801 | 1773.0 |
| 2009-10-02 | 2865 | 36 | 3735 | 1906.0 |
| 2009-10-01 | 2643 | 22 | 3528 | 1588.0 |
| 2009-10-07 | 2115 | 3 | 2825 | 984.0 |
| 2009-10-10 | 1407 | 725 | 1443 | 1003.0 |
| 2009-10-04 | 1336 | 0 | 1620 | 1116.0 |
| 2009-10-09 | 1302 | 482 | 1686 | 663.0 |
| 2009-10-03 | 993 | 7 | 1362 | 705.0 |
Métodos básicos de series de tiempo#
d.head(10)
| Berri | Mneuve1 | Mneuve2 | Brebeuf | |
|---|---|---|---|---|
| Date | ||||
| 2009-01-01 | 29 | 20 | 35 | 2576.359551 |
| 2009-01-02 | 19 | 3 | 22 | 2576.359551 |
| 2009-01-03 | 24 | 12 | 22 | 2576.359551 |
| 2009-01-04 | 24 | 8 | 15 | 2576.359551 |
| 2009-01-05 | 120 | 111 | 141 | 2576.359551 |
| 2009-01-06 | 261 | 146 | 236 | 2576.359551 |
| 2009-01-07 | 60 | 33 | 80 | 2576.359551 |
| 2009-01-08 | 24 | 14 | 14 | 2576.359551 |
| 2009-01-09 | 35 | 20 | 32 | 2576.359551 |
| 2009-01-10 | 81 | 45 | 79 | 2576.359551 |
# El metodo rolling nos proporciona una ventana móvil para operaciones matemáticas. En este caso la media por los 10 primeros meses
d.rolling(2).mean().head(10)
| Berri | Mneuve1 | Mneuve2 | Brebeuf | |
|---|---|---|---|---|
| Date | ||||
| 2009-01-01 | NaN | NaN | NaN | NaN |
| 2009-01-02 | 24.0 | 11.5 | 28.5 | 2576.359551 |
| 2009-01-03 | 21.5 | 7.5 | 22.0 | 2576.359551 |
| 2009-01-04 | 24.0 | 10.0 | 18.5 | 2576.359551 |
| 2009-01-05 | 72.0 | 59.5 | 78.0 | 2576.359551 |
| 2009-01-06 | 190.5 | 128.5 | 188.5 | 2576.359551 |
| 2009-01-07 | 160.5 | 89.5 | 158.0 | 2576.359551 |
| 2009-01-08 | 42.0 | 23.5 | 47.0 | 2576.359551 |
| 2009-01-09 | 29.5 | 17.0 | 23.0 | 2576.359551 |
| 2009-01-10 | 58.0 | 32.5 | 55.5 | 2576.359551 |
# Asigna un valor una marca temporal al index
d.index = d.index + pd.Timedelta("5m")
d.head()
| Berri | Mneuve1 | Mneuve2 | Brebeuf | |
|---|---|---|---|---|
| Date | ||||
| 2009-01-01 00:05:00 | 29 | 20 | 35 | 2576.359551 |
| 2009-01-02 00:05:00 | 19 | 3 | 22 | 2576.359551 |
| 2009-01-03 00:05:00 | 24 | 12 | 22 | 2576.359551 |
| 2009-01-04 00:05:00 | 24 | 8 | 15 | 2576.359551 |
| 2009-01-05 00:05:00 | 120 | 111 | 141 | 2576.359551 |
#Visualizamos el mismo rango de tiempo pero esta vez con el metodo .shift observamos este rango un año despues
d.shift(freq=pd.Timedelta(days=365)).head()
| Berri | Mneuve1 | Mneuve2 | Brebeuf | |
|---|---|---|---|---|
| Date | ||||
| 2010-01-01 00:05:00 | 29 | 20 | 35 | 2576.359551 |
| 2010-01-02 00:05:00 | 19 | 3 | 22 | 2576.359551 |
| 2010-01-03 00:05:00 | 24 | 12 | 22 | 2576.359551 |
| 2010-01-04 00:05:00 | 24 | 8 | 15 | 2576.359551 |
| 2010-01-05 00:05:00 | 120 | 111 | 141 | 2576.359551 |
Downsampling#
La reducción de muestreo, implica reducir el número de instancias en la clase mayoritaria. Esto se hace eliminando aleatoriamente las instancias de la clase mayoritaria hasta que la distribución de la clase esté más equilibrada.
#Visualizamos el primer mes con saltos temporales de 2 días y los primeros valores de esa fecha
d.resample(pd.Timedelta("2d")).first().head()
| Berri | Mneuve1 | Mneuve2 | Brebeuf | |
|---|---|---|---|---|
| Date | ||||
| 2009-01-01 | 29 | 20 | 35 | 2576.359551 |
| 2009-01-03 | 24 | 12 | 22 | 2576.359551 |
| 2009-01-05 | 120 | 111 | 141 | 2576.359551 |
| 2009-01-07 | 60 | 33 | 80 | 2576.359551 |
| 2009-01-09 | 35 | 20 | 32 | 2576.359551 |
# Por otro lado utilizando .mean() podemos observar el valor promedio obtenido entre los datos pero con la particularidad de que estos han sido realizados con el valor del día siguiente
d.resample(pd.Timedelta("2d")).mean().head()
| Berri | Mneuve1 | Mneuve2 | Brebeuf | |
|---|---|---|---|---|
| Date | ||||
| 2009-01-01 | 24.0 | 11.5 | 28.5 | 2576.359551 |
| 2009-01-03 | 24.0 | 10.0 | 18.5 | 2576.359551 |
| 2009-01-05 | 190.5 | 128.5 | 188.5 | 2576.359551 |
| 2009-01-07 | 42.0 | 23.5 | 47.0 | 2576.359551 |
| 2009-01-09 | 58.0 | 32.5 | 55.5 | 2576.359551 |
UpSampling#
El sobremuestreo implica aumentar el número de instancias de la clase minoritaria para equilibrar el conjunto de datos. Por lo general, esto se hace replicando aleatoriamente instancias de la clase minoritaria o generando muestras sintéticas utilizando técnicas como SMOTE (Técnica de sobremuestreo de minorías sintéticas). o como en este caso usando en metodo pad de .fillna que permite rellenar los valores faltantes tipo Nan
#Usamos resample para generar un intervalo de 12 horas en las misma fecha, duplicando así la cantidad de datos, sin embargo encontramos que estan vacios
d.resample(pd.Timedelta("12h")).first().head()
| Berri | Mneuve1 | Mneuve2 | Brebeuf | |
|---|---|---|---|---|
| Date | ||||
| 2009-01-01 00:00:00 | 29.0 | 20.0 | 35.0 | 2576.359551 |
| 2009-01-01 12:00:00 | NaN | NaN | NaN | NaN |
| 2009-01-02 00:00:00 | 19.0 | 3.0 | 22.0 | 2576.359551 |
| 2009-01-02 12:00:00 | NaN | NaN | NaN | NaN |
| 2009-01-03 00:00:00 | 24.0 | 12.0 | 22.0 | 2576.359551 |
#Para generar el duplicado de los datos con el intervalo de tiempo, sin que haya una ausencia de los datos, realizamos un rellenado con de estas con el metodo fillna
#fillna cuenta con un parametro llamado method que nos permite establecer el metodo de llenado, en este caso usamos 'pad' de Padding, se rellenan los valores faltantes utilizando el último valor válido conocido
d.resample(pd.Timedelta("12h")).first().fillna(method="pad").head()
| Berri | Mneuve1 | Mneuve2 | Brebeuf | |
|---|---|---|---|---|
| Date | ||||
| 2009-01-01 00:00:00 | 29.0 | 20.0 | 35.0 | 2576.359551 |
| 2009-01-01 12:00:00 | 29.0 | 20.0 | 35.0 | 2576.359551 |
| 2009-01-02 00:00:00 | 19.0 | 3.0 | 22.0 | 2576.359551 |
| 2009-01-02 12:00:00 | 19.0 | 3.0 | 22.0 | 2576.359551 |
| 2009-01-03 00:00:00 | 24.0 | 12.0 | 22.0 | 2576.359551 |
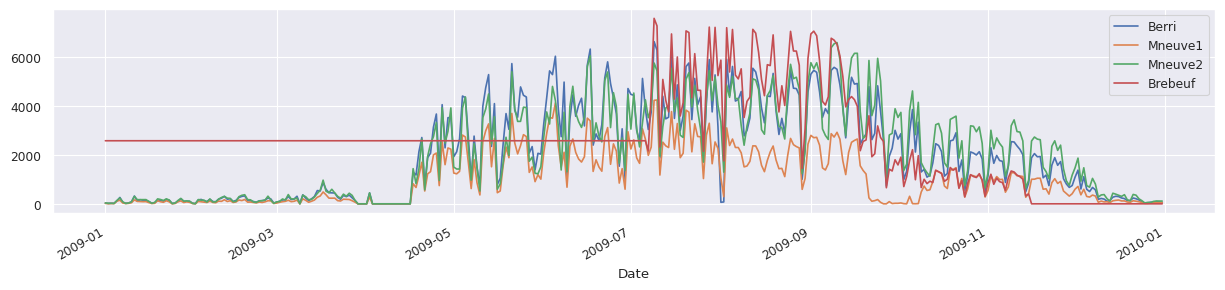
Visualización#
# Graficar usando plot, se grafican las variables numéricas, donde el eje X corresponde al índice con las fechas
d.plot(figsize=(15,3))
<Axes: xlabel='Date'>
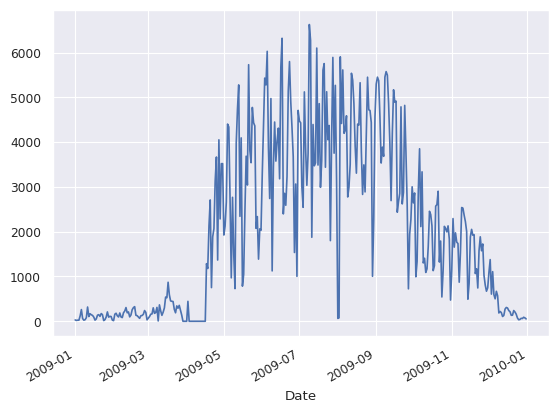
# Graficas sólo una columna (Berri)
d.Berri.plot()
<Axes: xlabel='Date'>
# Graficas la columna Berri de forma suma acumulada
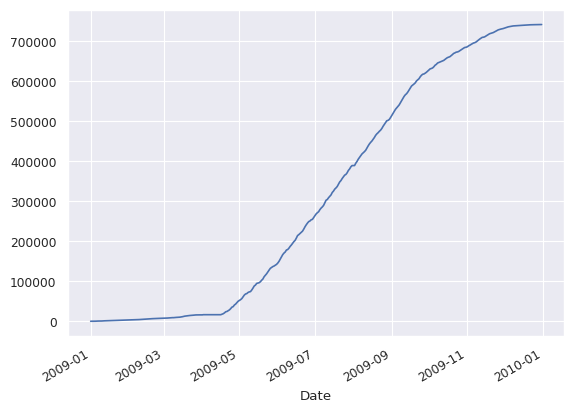
d.Berri.cumsum().plot()
<Axes: xlabel='Date'>
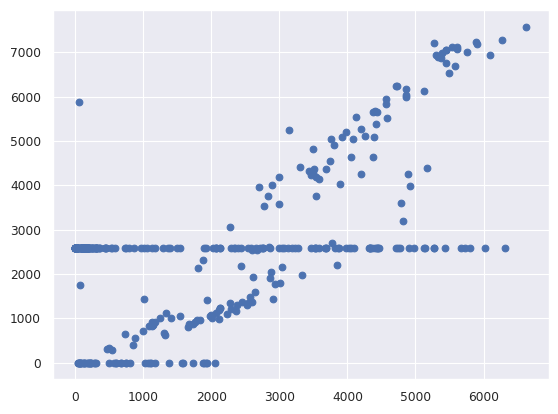
# Graficar puntos para datos de dos columnas
plt.scatter(d.Berri, d.Brebeuf)
<matplotlib.collections.PathCollection at 0x79e7b68a7c10>
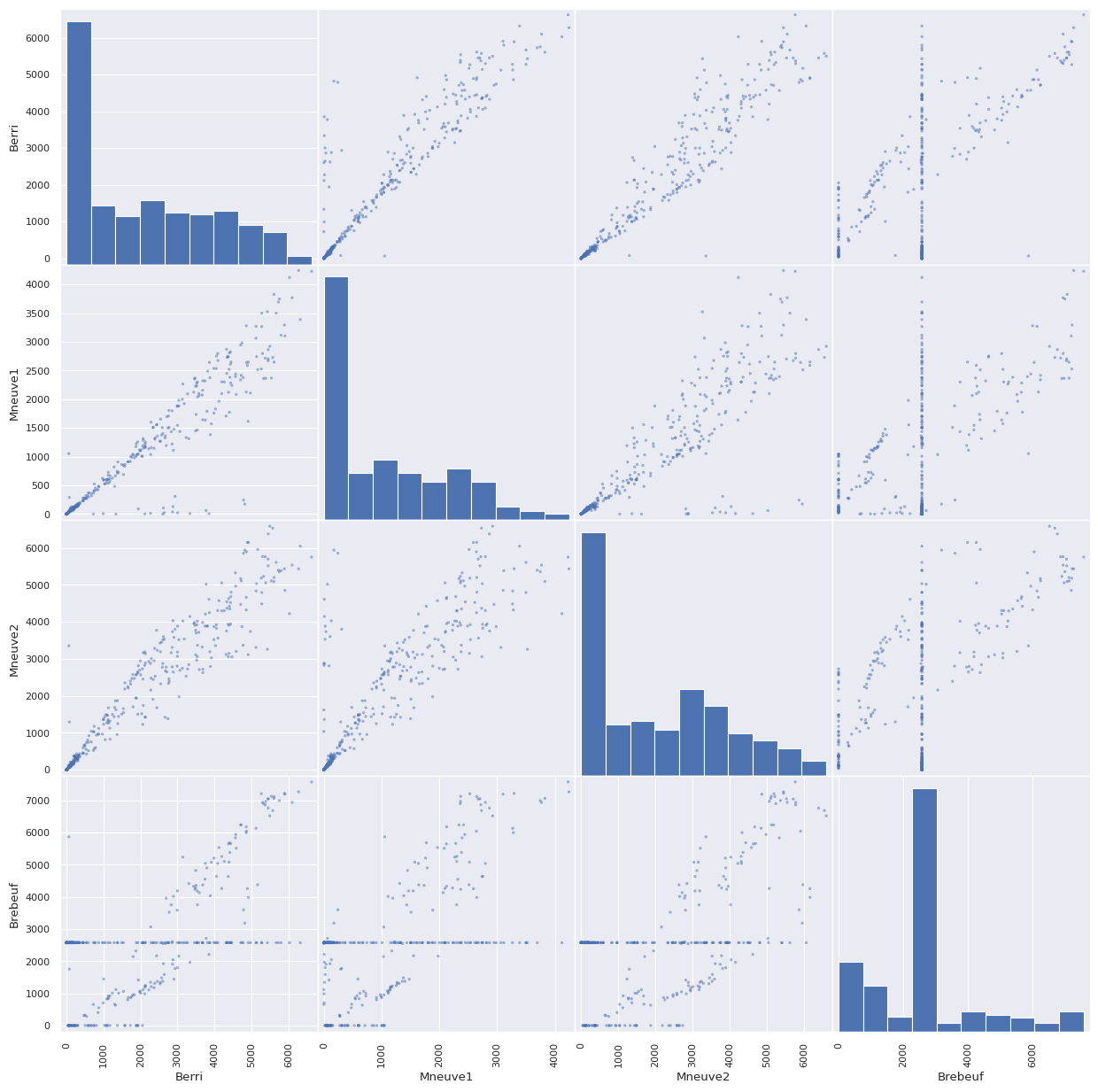
# Graficar puntos todas las columnas contra todas, la diagonal principal corresponde al histograma
pd.plotting.scatter_matrix(d, figsize=(15,15))
array([[<Axes: xlabel='Berri', ylabel='Berri'>,
<Axes: xlabel='Mneuve1', ylabel='Berri'>,
<Axes: xlabel='Mneuve2', ylabel='Berri'>,
<Axes: xlabel='Brebeuf', ylabel='Berri'>],
[<Axes: xlabel='Berri', ylabel='Mneuve1'>,
<Axes: xlabel='Mneuve1', ylabel='Mneuve1'>,
<Axes: xlabel='Mneuve2', ylabel='Mneuve1'>,
<Axes: xlabel='Brebeuf', ylabel='Mneuve1'>],
[<Axes: xlabel='Berri', ylabel='Mneuve2'>,
<Axes: xlabel='Mneuve1', ylabel='Mneuve2'>,
<Axes: xlabel='Mneuve2', ylabel='Mneuve2'>,
<Axes: xlabel='Brebeuf', ylabel='Mneuve2'>],
[<Axes: xlabel='Berri', ylabel='Brebeuf'>,
<Axes: xlabel='Mneuve1', ylabel='Brebeuf'>,
<Axes: xlabel='Mneuve2', ylabel='Brebeuf'>,
<Axes: xlabel='Brebeuf', ylabel='Brebeuf'>]], dtype=object)
Reto:#
Como un ejemplo más detallado de trabajo con datos de series temporales, echemos un vistazo a los conteos de bicicletas en el Puente Fremont de Seattle. Estos datos provienen de un contador automático de bicicletas instalado a finales de 2012, que tiene sensores inductivos en las aceras este y oeste del puente. Los conteos horarios de bicicletas se pueden descargar desde http://data.seattle.gov; el conjunto de datos del Contador de Bicicletas del Puente Fremont está disponible en la categoría de Transporte.
Vamos a realizar algunas operaciones con los datos ..
data = pd.read_csv('https://raw.githubusercontent.com/jakevdp/bicycle-data/main/FremontBridge.csv', index_col='Date', parse_dates=True)
data.columns = ['Total', 'East', 'West']
data.head()
<ipython-input-144-220a674f8aa6>:1: UserWarning: Could not infer format, so each element will be parsed individually, falling back to `dateutil`. To ensure parsing is consistent and as-expected, please specify a format.
data = pd.read_csv('https://raw.githubusercontent.com/jakevdp/bicycle-data/main/FremontBridge.csv', index_col='Date', parse_dates=True)
| Total | East | West | |
|---|---|---|---|
| Date | |||
| 2019-11-01 00:00:00 | 12.0 | 7.0 | 5.0 |
| 2019-11-01 01:00:00 | 7.0 | 0.0 | 7.0 |
| 2019-11-01 02:00:00 | 1.0 | 0.0 | 1.0 |
| 2019-11-01 03:00:00 | 6.0 | 6.0 | 0.0 |
| 2019-11-01 04:00:00 | 6.0 | 5.0 | 1.0 |
data.dropna().describe()
| Total | East | West | |
|---|---|---|---|
| count | 147255.000000 | 147255.000000 | 147255.000000 |
| mean | 110.341462 | 50.077763 | 60.263699 |
| std | 140.422051 | 64.634038 | 87.252147 |
| min | 0.000000 | 0.000000 | 0.000000 |
| 25% | 14.000000 | 6.000000 | 7.000000 |
| 50% | 60.000000 | 28.000000 | 30.000000 |
| 75% | 145.000000 | 68.000000 | 74.000000 |
| max | 1097.000000 | 698.000000 | 850.000000 |
Grafica los datos en bruto del conteo de bicicletas. Asegúrate de etiquetar el eje Y con ‘Conteo de Bicicletas por Hora’.
# Tu codigo va acá
Los datos horarios son demasiado densos. Remuestrea los datos a una cuadrícula semanal y grafica los conteos semanales. Usa estilos de línea diferentes para cada serie.
# Tu codigo va acá
Remuestrea los datos a una cuadrícula diaria y grafica la suma diaria de los conteos de bicicletas. Asegúrate de etiquetar el eje Y con ‘Conteo de Bicicletas por Hora Promedio’.
# Tu codigo va acá
Calcula y grafica la media móvil de 50 días de los datos de bicicletas utilizando una ventana gaussiana con un ancho de 10 días. Usa diferentes estilos de línea para cada serie.
# Tu codigo va acá
Agrupa los datos por tiempo del día y grafica el tráfico promedio de bicicletas. Utiliza groupby y mean, y asegúrate de configurar las marcas de tiempo en el eje X.
# Tu codigo va acá
Agrupa los datos por día de la semana y grafica el tráfico promedio de bicicletas para cada día. Ajusta las etiquetas del índice para representar los días de la semana.
# Tu codigo va acá
Agrupa los datos para diferenciar entre días de semana y fines de semana, y luego calcula la media horaria de los conteos de bicicletas. Usa groupby y mean.
# Tu codigo va acá
Utiliza Matplotlib para crear dos gráficos en paralelo que muestren los conteos horarios de bicicletas durante los días de semana y los fines de semana. Usa subplots y asegúrate de etiquetar los gráficos adecuadamente.
# Tu codigo va acá