Manejo de ficheros#
El manejo de ficheros es una habilidad esencial en Python, especialmente cuando se trabaja con datos almacenados en archivos de texto, CSV, JSON y otros formatos. En esta clase, aprenderemos a leer y escribir archivos, así como a procesar y analizar los datos contenidos en ellos.
En diferentes aplicaciones es fundamental realizar manejo de archivos, tanto para el almacenamiento de información como para la carga de información de la aplicación general. Python ofrece un conjunto de funciones que hacen parte de la librería estándar y permiten la manipulación de archivos de texto plano. A continuación veremos el uso de las principales funciones.
Para abrir un archivo:
filepath = 'ruta_del_archivo'
file = open('filepath/filename.txt','modo')
Como se puede observar un archivo puede abrirse en diferentes modos:
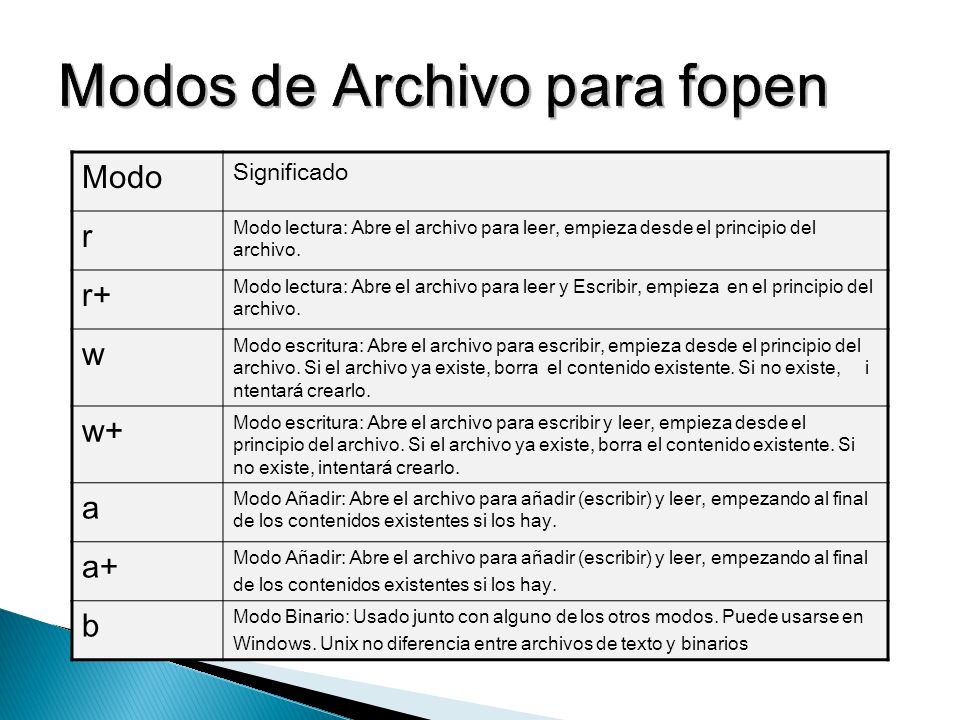
Para usar esta librería, en primer lugar crearemos un archivo desde cero, esto se puede hacer con los modos (x) o (w). Verifique cual es la diferencia entre ambos

# Descarguemos un archivo de prueba
!wget https://raw.githubusercontent.com/BioAITeamLearning/IntroPython_2024_01_UAI/main/Data/archivo.txt
--2024-06-12 20:52:10-- https://raw.githubusercontent.com/BioAITeamLearning/IntroPython_2024_01_UAI/main/Data/archivo.txt
Resolving raw.githubusercontent.com (raw.githubusercontent.com)... 185.199.108.133, 185.199.109.133, 185.199.110.133, ...
Connecting to raw.githubusercontent.com (raw.githubusercontent.com)|185.199.108.133|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 41 [text/plain]
Saving to: ‘archivo.txt’
archivo.txt 0%[ ] 0 --.-KB/s
archivo.txt 100%[===================>] 41 --.-KB/s in 0s
2024-06-12 20:52:10 (525 KB/s) - ‘archivo.txt’ saved [41/41]
# Abrir y leer un archivo de texto
with open("archivo.txt", "r") as archivo:
contenido = archivo.read()
print(contenido)
Hola, este es el contenido de un archivo.
# Crear un archivo
folder='sample_data'
fileName = 'miArchivo'
fileExtension= 'txt'
filePath = folder + '/' + fileName + '.' + fileExtension
open(filePath,'x')
<_io.TextIOWrapper name='sample_data/miArchivo.txt' mode='x' encoding='UTF-8'>
Podrá verificar que después de ejecutar las líneas anteriores se crea un archivo en la carpeta sample_data. A continuación abriremos el archivo en módulo (w) para escribir algo en él.
file = open(filePath,'w')
Ahora con el archivo abierto, podemos escribir la información que se contenga en otra estructura, por ejemplo una lista.
miLista = [‘Hola’,’mundo’]
miLista = ['Hola','mundo']
for i in range(10):
for palabra in miLista:
file.write(palabra+'\t')
file.write('\n')
Luego de procesar un archivo es necesario cerrarlo para que esté disponible para otras aplicaciones.
file.close()
En este momento haga el ejercicio de descargar el archivo y abrirlo desde su computador con un bloc de notas. Podra ver algo como lo siguiente:

A partir de este archivo se pueden agregar nuevas líneas, para ello utilizaremos el modo (a), supongamos la siguiente tupla:
miTupla = (‘Loren’,’ipsum’,’dolor’,’at’,’met’)
miTupla = ('Loren','ipsum','dolor','at','met')
file = open(filePath,'a')
for palabra in miTupla:
file.write(palabra+' ')
file.close()
with open(filePath, "w") as archivo:
archivo.write("Hola, este es un archivo de texto.\n")
archivo.write("Esta es una segunda línea.")
Ejemplo 1:#
Escribe un programa que cree un archivo de texto, escriba varias líneas, y luego lo lea e imprima su contenido.
with open("mi_archivo.txt", "w") as archivo:
archivo.write("Primera línea.\n")
archivo.write("Segunda línea.\n")
archivo.write("Tercera línea.\n")
# Leer el archivo de texto
with open("mi_archivo.txt", "r") as archivo:
contenido = archivo.read()
print(contenido)
Primera línea.
Segunda línea.
Tercera línea.
Lectura de archivos#
Ahora que ya tenemos un archivo creado y con contenido podemos abrirlo para leerlo.
file = open(filePath,'r')
lista = list()
for linea in file:
#print(type(linea))
lista.append(linea)
print(linea)
file.close()
print(lista)
Hola mundo
Hola mundo
Hola mundo
Hola mundo
Hola mundo
Hola mundo
Hola mundo
Hola mundo
Hola mundo
Hola mundo
Loren ipsum dolor at met
['Hola\tmundo\t\n', 'Hola\tmundo\t\n', 'Hola\tmundo\t\n', 'Hola\tmundo\t\n', 'Hola\tmundo\t\n', 'Hola\tmundo\t\n', 'Hola\tmundo\t\n', 'Hola\tmundo\t\n', 'Hola\tmundo\t\n', 'Hola\tmundo\t\n', 'Loren ipsum dolor at met ']
Lecto - escritura de archivos#
Existen modos de lectoescritura como w+, r+ y a+
## Lecto - escritura de archivos
f=open(filePath,"r+")
x=f.readlines()
print(x)
print(type(x))
f.write("\n Esto es otra línea")
f.close()
['Hola\tmundo\t\n', 'Hola\tmundo\t\n', 'Hola\tmundo\t\n', 'Hola\tmundo\t\n', 'Hola\tmundo\t\n', 'Hola\tmundo\t\n', 'Hola\tmundo\t\n', 'Hola\tmundo\t\n', 'Hola\tmundo\t\n', 'Hola\tmundo\t\n', 'Loren ipsum dolor at met ']
<class 'list'>
Leyendo archivos JSON#
Estos archivos se utilizan ampliamente en APIs de sitios web. En apariencia son similares a los diccionarios de Python, pues almacenan los datos a manera de clave y valor. Al igual que en el caso de CSV la mejor alternativa para leer estos archivos es mediante Pandas. En este caso utilizaremos el archivo anscombe.json
import json
with open('sample_data/anscombe.json') as json_file:
data = json.load(json_file)
print(data)
[{'Series': 'I', 'X': 10.0, 'Y': 8.04}, {'Series': 'I', 'X': 8.0, 'Y': 6.95}, {'Series': 'I', 'X': 13.0, 'Y': 7.58}, {'Series': 'I', 'X': 9.0, 'Y': 8.81}, {'Series': 'I', 'X': 11.0, 'Y': 8.33}, {'Series': 'I', 'X': 14.0, 'Y': 9.96}, {'Series': 'I', 'X': 6.0, 'Y': 7.24}, {'Series': 'I', 'X': 4.0, 'Y': 4.26}, {'Series': 'I', 'X': 12.0, 'Y': 10.84}, {'Series': 'I', 'X': 7.0, 'Y': 4.81}, {'Series': 'I', 'X': 5.0, 'Y': 5.68}, {'Series': 'II', 'X': 10.0, 'Y': 9.14}, {'Series': 'II', 'X': 8.0, 'Y': 8.14}, {'Series': 'II', 'X': 13.0, 'Y': 8.74}, {'Series': 'II', 'X': 9.0, 'Y': 8.77}, {'Series': 'II', 'X': 11.0, 'Y': 9.26}, {'Series': 'II', 'X': 14.0, 'Y': 8.1}, {'Series': 'II', 'X': 6.0, 'Y': 6.13}, {'Series': 'II', 'X': 4.0, 'Y': 3.1}, {'Series': 'II', 'X': 12.0, 'Y': 9.13}, {'Series': 'II', 'X': 7.0, 'Y': 7.26}, {'Series': 'II', 'X': 5.0, 'Y': 4.74}, {'Series': 'III', 'X': 10.0, 'Y': 7.46}, {'Series': 'III', 'X': 8.0, 'Y': 6.77}, {'Series': 'III', 'X': 13.0, 'Y': 12.74}, {'Series': 'III', 'X': 9.0, 'Y': 7.11}, {'Series': 'III', 'X': 11.0, 'Y': 7.81}, {'Series': 'III', 'X': 14.0, 'Y': 8.84}, {'Series': 'III', 'X': 6.0, 'Y': 6.08}, {'Series': 'III', 'X': 4.0, 'Y': 5.39}, {'Series': 'III', 'X': 12.0, 'Y': 8.15}, {'Series': 'III', 'X': 7.0, 'Y': 6.42}, {'Series': 'III', 'X': 5.0, 'Y': 5.73}, {'Series': 'IV', 'X': 8.0, 'Y': 6.58}, {'Series': 'IV', 'X': 8.0, 'Y': 5.76}, {'Series': 'IV', 'X': 8.0, 'Y': 7.71}, {'Series': 'IV', 'X': 8.0, 'Y': 8.84}, {'Series': 'IV', 'X': 8.0, 'Y': 8.47}, {'Series': 'IV', 'X': 8.0, 'Y': 7.04}, {'Series': 'IV', 'X': 8.0, 'Y': 5.25}, {'Series': 'IV', 'X': 19.0, 'Y': 12.5}, {'Series': 'IV', 'X': 8.0, 'Y': 5.56}, {'Series': 'IV', 'X': 8.0, 'Y': 7.91}, {'Series': 'IV', 'X': 8.0, 'Y': 6.89}]
Escribiendo archivos JSON#
import json
# Escribir en un archivo JSON
datos = {
"nombre": "Ana",
"edad": 30,
"ciudad": "Madrid"
}
with open("archivo.json", "w") as archivo:
json.dump(datos, archivo, indent=4)
Escribiendo archivos csv#
import csv
# Escribir en un archivo CSV
with open("archivo.csv", "w", newline='') as archivo:
escritor_csv = csv.writer(archivo)
escritor_csv.writerow(["Nombre", "Edad", "Ciudad"])
escritor_csv.writerow(["Ana", 30, "Madrid"])
escritor_csv.writerow(["Carlos", 25, "Barcelona"])
Leyendo archivos csv#
import csv
# Leer un archivo CSV
with open("archivo.csv", "r") as archivo:
lector_csv = csv.reader(archivo)
for fila in lector_csv:
print(fila)
['Nombre', 'Edad', 'Ciudad']
['Ana', '30', 'Madrid']
['Carlos', '25', 'Barcelona']
Ejemplo:#
Escribe un programa que cree un archivo CSV, escriba varias filas de datos, y luego lo lea e imprima su contenido.
import csv
# Escribir en un archivo CSV
with open("datos.csv", "w", newline='') as archivo:
escritor_csv = csv.writer(archivo)
escritor_csv.writerow(["Nombre", "Edad", "Ciudad"])
escritor_csv.writerow(["Ana", 30, "Madrid"])
escritor_csv.writerow(["Carlos", 25, "Barcelona"])
escritor_csv.writerow(["Beatriz", 28, "Valencia"])
# Leer el archivo CSV
with open("datos.csv", "r") as archivo:
lector_csv = csv.reader(archivo)
for fila in lector_csv:
print(fila)
['Nombre', 'Edad', 'Ciudad']
['Ana', '30', 'Madrid']
['Carlos', '25', 'Barcelona']
['Beatriz', '28', 'Valencia']
Ejemplo de análisis de datos desde un archivo csv#
Supongamos que tenemos un archivo CSV con datos de empleados y queremos calcular la edad promedio.
# Descarguemos un archivo de prueba
!wget https://raw.githubusercontent.com/BioAITeamLearning/IntroPython_2024_01_UAI/main/Data/empleados.csv
--2024-06-12 21:41:37-- https://raw.githubusercontent.com/BioAITeamLearning/IntroPython_2024_01_UAI/main/Data/empleados.csv
Resolving raw.githubusercontent.com (raw.githubusercontent.com)... 185.199.108.133, 185.199.109.133, 185.199.110.133, ...
Connecting to raw.githubusercontent.com (raw.githubusercontent.com)|185.199.108.133|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 557 [text/plain]
Saving to: ‘empleados.csv’
empleados.csv 0%[ ] 0 --.-KB/s
empleados.csv 100%[===================>] 557 --.-KB/s in 0s
2024-06-12 21:41:37 (20.5 MB/s) - ‘empleados.csv’ saved [557/557]
import csv
# Leer datos de empleados y calcular la edad promedio
with open("empleados.csv", "r") as archivo:
lector_csv = csv.DictReader(archivo)
total_edad = 0
contador = 0
for fila in lector_csv:
total_edad += int(fila["Edad"])
contador += 1
edad_promedio = total_edad / contador
print(f"Edad promedio: {edad_promedio}")
Edad promedio: 30.133333333333333
Ejemplo de análisis de datos desde un archivo JSON#
Supongamos que tenemos un archivo JSON con datos de varios productos y queremos calcular el precio total de todos los productos.
# Descarguemos un archivo de prueba
!wget https://raw.githubusercontent.com/BioAITeamLearning/IntroPython_2024_01_UAI/main/Data/productos.json
--2024-06-12 21:42:00-- https://raw.githubusercontent.com/BioAITeamLearning/IntroPython_2024_01_UAI/main/Data/productos.json
Resolving raw.githubusercontent.com (raw.githubusercontent.com)... 185.199.108.133, 185.199.109.133, 185.199.110.133, ...
Connecting to raw.githubusercontent.com (raw.githubusercontent.com)|185.199.108.133|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 1369 (1.3K) [text/plain]
Saving to: ‘productos.json’
productos.json 0%[ ] 0 --.-KB/s
productos.json 100%[===================>] 1.34K --.-KB/s in 0s
2024-06-12 21:42:00 (64.5 MB/s) - ‘productos.json’ saved [1369/1369]
import json
# Leer datos de productos y calcular el precio total
with open("productos.json", "r") as archivo:
productos = json.load(archivo)
total_precio = sum(producto["precio"] for producto in productos)
print(f"Precio total: {total_precio}")
Precio total: 370.0
Ejercicio 1: Registro y Análisis de Asistencia#
Crea un programa para gestionar el registro de asistencia de empleados en una institución pública. El programa debe permitir:
Guardar los datos de asistencia en un archivo CSV.
Leer y mostrar los datos de asistencia desde el archivo.
Calcular y mostrar el porcentaje de asistencia de cada empleado.
# Descarguemos un archivo de prueba
!wget https://raw.githubusercontent.com/BioAITeamLearning/IntroPython_2024_01_UAI/main/Data/asistencia.csv
--2024-06-12 21:47:08-- https://raw.githubusercontent.com/BioAITeamLearning/IntroPython_2024_01_UAI/main/Data/asistencia.csv
Resolving raw.githubusercontent.com (raw.githubusercontent.com)... 185.199.108.133, 185.199.109.133, 185.199.110.133, ...
Connecting to raw.githubusercontent.com (raw.githubusercontent.com)|185.199.108.133|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 704 [text/plain]
Saving to: ‘asistencia.csv.1’
asistencia.csv.1 0%[ ] 0 --.-KB/s
asistencia.csv.1 100%[===================>] 704 --.-KB/s in 0s
2024-06-12 21:47:08 (44.0 MB/s) - ‘asistencia.csv.1’ saved [704/704]
import csv
def agregar_asistencia(archivo, nombre, fecha, presente):
with open(archivo, "a", newline='') as archivo_csv:
escritor_csv = csv.writer(archivo_csv)
escritor_csv.writerow([nombre, fecha, presente])
def leer_asistencia(archivo):
with open(archivo, "r") as archivo_csv:
lector_csv = csv.reader(archivo_csv)
for fila in lector_csv:
print(fila)
def calcular_asistencia(archivo):
with open(archivo, "r") as archivo_csv:
lector_csv = csv.reader(archivo_csv)
empleados = {}
for fila in lector_csv:
nombre, _, presente = fila
if nombre not in empleados:
empleados[nombre] = {"asistencias": 0, "total": 0}
empleados[nombre]["total"] += 1
if presente == "True":
empleados[nombre]["asistencias"] += 1
for nombre, datos in empleados.items():
porcentaje_asistencia = (datos["asistencias"] / datos["total"]) * 100
print(f"{nombre}: {porcentaje_asistencia:.2f}% de asistencia")
# Agregar registros de asistencia
agregar_asistencia("asistencia.csv", "Juan", "2023-06-01", True)
agregar_asistencia("asistencia.csv", "Ana", "2023-06-01", True)
agregar_asistencia("asistencia.csv", "Carlos", "2023-06-01", False)
agregar_asistencia("asistencia.csv", "Juan", "2023-06-02", False)
agregar_asistencia("asistencia.csv", "Ana", "2023-06-02", True)
# Leer y mostrar los registros de asistencia
leer_asistencia("asistencia.csv")
['Juan', '2023-06-01', 'True']
['Ana', '2023-06-01', 'True']
['Carlos', '2023-06-01', 'False']
['Juan', '2023-06-02', 'False']
['Ana', '2023-06-02', 'True']
['Juan', '2023-06-01', 'True']
['Ana', '2023-06-01', 'True']
['Carlos', '2023-06-01', 'False']
['Juan', '2023-06-02', 'False']
['Ana', '2023-06-02', 'True']
# Calcular y mostrar el porcentaje de asistencia de cada empleado
calcular_asistencia("asistencia.csv")
Juan: 50.00% de asistencia
Ana: 100.00% de asistencia
Carlos: 0.00% de asistencia
Reto 2: Gestión de Inventario de Equipos#
Crea un programa para gestionar el inventario de equipos en una institución pública. El programa debe permitir:
Guardar los datos del inventario en un archivo JSON.
Leer y mostrar los datos del inventario desde el archivo.
Calcular y mostrar el valor total del inventario.
# Descarguemos un archivo de prueba
!wget https://raw.githubusercontent.com/BioAITeamLearning/IntroPython_2024_01_UAI/main/Data/inventario.json
--2024-06-12 21:47:42-- https://raw.githubusercontent.com/BioAITeamLearning/IntroPython_2024_01_UAI/main/Data/inventario.json
Resolving raw.githubusercontent.com (raw.githubusercontent.com)... 185.199.108.133, 185.199.109.133, 185.199.110.133, ...
Connecting to raw.githubusercontent.com (raw.githubusercontent.com)|185.199.108.133|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 2982 (2.9K) [text/plain]
Saving to: ‘inventario.json.1’
inventario.json.1 0%[ ] 0 --.-KB/s
inventario.json.1 100%[===================>] 2.91K --.-KB/s in 0s
2024-06-12 21:47:42 (16.1 MB/s) - ‘inventario.json.1’ saved [2982/2982]
import json
def agregar_equipo(archivo, equipo):
try:
with open(archivo, "r") as archivo_json:
inventario = json.load(archivo_json)
except FileNotFoundError:
inventario = []
inventario.append(equipo)
with open(archivo, "w") as archivo_json:
json.dump(inventario, archivo_json, indent=4)
def leer_inventario(archivo):
with open(archivo, "r") as archivo_json:
inventario = json.load(archivo_json)
for equipo in inventario:
print(equipo)
def calcular_valor_total(archivo):
with open(archivo, "r") as archivo_json:
inventario = json.load(archivo_json)
valor_total = sum(equipo["valor"] for equipo in inventario)
print(f"Valor total del inventario: {valor_total}")
# Agregar equipos al inventario
agregar_equipo("inventario.json", {"nombre": "Computadora", "marca": "Dell", "modelo": "Inspiron", "año": 2021, "valor": 800})
agregar_equipo("inventario.json", {"nombre": "Impresora", "marca": "HP","modelo": "LaserJet", "año": 2019, "valor": 200})
agregar_equipo("inventario.json", {"nombre": "Escáner", "marca": "Epson", "modelo": "Perfection", "año": 2020, "valor": 150})
# Leer y mostrar los datos del inventario
leer_inventario("inventario.json")
{'nombre': 'Computadora', 'marca': 'Dell', 'modelo': 'Inspiron', 'año': 2021, 'valor': 800}
{'nombre': 'Impresora', 'marca': 'HP', 'modelo': 'LaserJet', 'año': 2019, 'valor': 200}
{'nombre': 'Escáner', 'marca': 'Epson', 'modelo': 'Perfection', 'año': 2020, 'valor': 150}
{'nombre': 'Computadora', 'marca': 'Dell', 'modelo': 'Inspiron', 'año': 2021, 'valor': 800}
{'nombre': 'Impresora', 'marca': 'HP', 'modelo': 'LaserJet', 'año': 2019, 'valor': 200}
{'nombre': 'Escáner', 'marca': 'Epson', 'modelo': 'Perfection', 'año': 2020, 'valor': 150}
calcular_valor_total("inventario.json")
Valor total del inventario: 2300
Reto 1: Sistema de Gestión de Evaluaciones de Desempeño#
Crea un programa que gestione las evaluaciones de desempeño de empleados en una institución pública. El programa debe permitir:
Guardar los datos de las evaluaciones en un archivo JSON.
Leer y mostrar los datos de las evaluaciones desde el archivo.
Calcular y mostrar el puntaje promedio de desempeño por departamento.
Requisitos:
Cada evaluación debe contener el nombre del empleado, departamento, fecha de evaluación y puntaje.
El programa debe ser capaz de agregar nuevas evaluaciones, actualizar puntajes de evaluaciones existentes y eliminar evaluaciones.
Debe calcular el puntaje promedio de desempeño por departamento y mostrar un resumen de todos los empleados y sus evaluaciones.
# Descarguemos un archivo de prueba
!wget https://raw.githubusercontent.com/BioAITeamLearning/IntroPython_2024_01_UAI/main/Data/evaluaciones.json
# Tu código va acá
Reto 2: Sistema de Gestión de Proyectos de Infraestructura#
Crea un programa que gestione los proyectos de infraestructura en una institución pública. El programa debe permitir:
Guardar los datos de los proyectos en un archivo CSV.
Leer y mostrar los datos de los proyectos desde el archivo.
Calcular y mostrar el presupuesto total de los proyectos por estado (planificado, en curso, completado).
Requisitos:
Cada proyecto debe contener el nombre del proyecto, descripción, fecha de inicio, fecha de fin, estado y presupuesto.
El programa debe ser capaz de agregar nuevos proyectos, actualizar el estado y presupuesto de proyectos existentes y eliminar proyectos.
Debe calcular el presupuesto total por estado y mostrar un resumen de todos los proyectos.
# Descarguemos un archivo de prueba
!wget https://raw.githubusercontent.com/BioAITeamLearning/IntroPython_2024_01_UAI/main/Data/proyectos.csv
# Tu código va acá