“Data cleaning” y “Filtros”#
Para responder a preguntas a partir de los datos, pandas es una librería muy útil. Sin embargo, los datos no siempre vienen limpios y listos para ser analizados. En este notebook, veremos cómo limpiar datos y cómo filtrarlos para responder a preguntas específicas.
# Vamos a cargar un dataset de ejemplo.
import pandas as pd
df = pd.read_csv('data/titanic.csv')
df
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S |
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S |
| 4 | 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 886 | 887 | 0 | 2 | Montvila, Rev. Juozas | male | 27.0 | 0 | 0 | 211536 | 13.0000 | NaN | S |
| 887 | 888 | 1 | 1 | Graham, Miss. Margaret Edith | female | 19.0 | 0 | 0 | 112053 | 30.0000 | B42 | S |
| 888 | 889 | 0 | 3 | Johnston, Miss. Catherine Helen "Carrie" | female | NaN | 1 | 2 | W./C. 6607 | 23.4500 | NaN | S |
| 889 | 890 | 1 | 1 | Behr, Mr. Karl Howell | male | 26.0 | 0 | 0 | 111369 | 30.0000 | C148 | C |
| 890 | 891 | 0 | 3 | Dooley, Mr. Patrick | male | 32.0 | 0 | 0 | 370376 | 7.7500 | NaN | Q |
891 rows × 12 columns
Revisa algunos de los métodos anteriores para revisar la data y explorar el tamaño de la información y las columnas.
# TU CÓDIGO AQUÍ
Tratamiento de valores Faltantes#
Un problema común en los datos es la presencia de valores faltantes. Estos valores pueden ser NaN, None, NaT, entre otros. Para tratar estos valores, podemos usar el método fillna() para reemplazar los valores faltantes por un valor específico. También podemos usar el método dropna() para eliminar las filas que contienen valores faltantes.
Con el método isnull(), podemos identificar los valores faltantes en un DataFrame. Este método devuelve un DataFrame booleano con True en las posiciones donde hay valores faltantes y False en las posiciones donde no hay valores faltantes.
Si usamos fillna() se reemplazarán los valores faltantes por el valor que le pasemos como argumento. Si usamos dropna() se eliminarán las filas que contienen valores faltantes.
df.fillna('-')
df.head(10) # Note que al parecer el cambio no se ha realizado. ¿Por qué? ¿Qué podemos hacer para solucionar esto?
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S |
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S |
| 4 | 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S |
| 5 | 6 | 0 | 3 | Moran, Mr. James | male | NaN | 0 | 0 | 330877 | 8.4583 | NaN | Q |
| 6 | 7 | 0 | 1 | McCarthy, Mr. Timothy J | male | 54.0 | 0 | 0 | 17463 | 51.8625 | E46 | S |
| 7 | 8 | 0 | 3 | Palsson, Master. Gosta Leonard | male | 2.0 | 3 | 1 | 349909 | 21.0750 | NaN | S |
| 8 | 9 | 1 | 3 | Johnson, Mrs. Oscar W (Elisabeth Vilhelmina Berg) | female | 27.0 | 0 | 2 | 347742 | 11.1333 | NaN | S |
| 9 | 10 | 1 | 2 | Nasser, Mrs. Nicholas (Adele Achem) | female | 14.0 | 1 | 0 | 237736 | 30.0708 | NaN | C |
df_cleaned = df.fillna('-')
df_cleaned.head(10) # Ahora sí se ha realizado el cambio.
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | - | S |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | - | S |
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S |
| 4 | 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | - | S |
| 5 | 6 | 0 | 3 | Moran, Mr. James | male | - | 0 | 0 | 330877 | 8.4583 | - | Q |
| 6 | 7 | 0 | 1 | McCarthy, Mr. Timothy J | male | 54.0 | 0 | 0 | 17463 | 51.8625 | E46 | S |
| 7 | 8 | 0 | 3 | Palsson, Master. Gosta Leonard | male | 2.0 | 3 | 1 | 349909 | 21.0750 | - | S |
| 8 | 9 | 1 | 3 | Johnson, Mrs. Oscar W (Elisabeth Vilhelmina Berg) | female | 27.0 | 0 | 2 | 347742 | 11.1333 | - | S |
| 9 | 10 | 1 | 2 | Nasser, Mrs. Nicholas (Adele Achem) | female | 14.0 | 1 | 0 | 237736 | 30.0708 | - | C |
df.fillna('-', inplace=True) # Esta es otra forma de tratar los valores nulos,
# solo que en esta le especificamos que queremos que se haga el cambio en el mismo dataframe.
# Otras formas de completar los valores nulos son:
# - fillna(0) para completar con ceros.
# - fillna('Desconocido') para completar con un string.
# - fillna(df['columna'].mean()) para completar con el promedio de la columna.
# - fillna(df['columna'].median()) para completar con la mediana de la columna.
# - fillna(df['columna'].mode()[0]) para completar con la moda de la columna.
# - fillna(method='ffill') para completar con el valor anterior.
# - fillna(method='bfill') para completar con el valor siguiente.
Ejercicio#
Realiza la limpieza de solo una columna del dataframe y que los valores nulos se rellenen por el promedio de la columna.
# TU CÓDIGO AQUÍ
Operaciones con dataframes#
Para realizar operaciones y filtrar información del dataframe o calcular nuevas columnas a partir de los datos ya existentes podemos utilizar funcionalidades especializadas de pandas. Vamos a revisar algunas cosas que podemos hacer con los dataframes.
Operaciones de indexación booleana#
# Indexación booleana
# La indexación booleana es una técnica que nos permite seleccionar un subconjunto de datos de un DataFrame
# que cumpla con cierta condición.
# Por ejemplo, si queremos seleccionar los pasajeros que son mujeres, podemos hacer lo siguiente:
df.head(3)
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S |
# 1. revisemos los posibles valores que puede tomar la columna
df['Sex'].unique()
array(['male', 'female'], dtype=object)
# 2. Como solo quiero seleccionar los que son mujeres hago lo siguiente:
result = df['Sex'] == 'female'
result # así, en result tenemos una serie de booleanos que nos indican si el pasajero es mujer o no.
# Pero nosotros queremos es tener los registros de las mujeres, para eso hacemos lo siguiente:
0 False
1 True
2 True
3 True
4 False
...
886 False
887 True
888 True
889 False
890 False
Name: Sex, Length: 891, dtype: bool
df[result]
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S |
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S |
| 8 | 9 | 1 | 3 | Johnson, Mrs. Oscar W (Elisabeth Vilhelmina Berg) | female | 27.0 | 0 | 2 | 347742 | 11.1333 | NaN | S |
| 9 | 10 | 1 | 2 | Nasser, Mrs. Nicholas (Adele Achem) | female | 14.0 | 1 | 0 | 237736 | 30.0708 | NaN | C |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 880 | 881 | 1 | 2 | Shelley, Mrs. William (Imanita Parrish Hall) | female | 25.0 | 0 | 1 | 230433 | 26.0000 | NaN | S |
| 882 | 883 | 0 | 3 | Dahlberg, Miss. Gerda Ulrika | female | 22.0 | 0 | 0 | 7552 | 10.5167 | NaN | S |
| 885 | 886 | 0 | 3 | Rice, Mrs. William (Margaret Norton) | female | 39.0 | 0 | 5 | 382652 | 29.1250 | NaN | Q |
| 887 | 888 | 1 | 1 | Graham, Miss. Margaret Edith | female | 19.0 | 0 | 0 | 112053 | 30.0000 | B42 | S |
| 888 | 889 | 0 | 3 | Johnston, Miss. Catherine Helen "Carrie" | female | NaN | 1 | 2 | W./C. 6607 | 23.4500 | NaN | S |
314 rows × 12 columns
# O lo que es lo mismo:
df[df['Sex'] == 'female']
# Esta sintaxis se puede leer como: del dataframe df, vamos a seleccionar las filas donde el dataframe df en la columna "Sex" sea igual a "female".
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S |
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S |
| 8 | 9 | 1 | 3 | Johnson, Mrs. Oscar W (Elisabeth Vilhelmina Berg) | female | 27.0 | 0 | 2 | 347742 | 11.1333 | NaN | S |
| 9 | 10 | 1 | 2 | Nasser, Mrs. Nicholas (Adele Achem) | female | 14.0 | 1 | 0 | 237736 | 30.0708 | NaN | C |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 880 | 881 | 1 | 2 | Shelley, Mrs. William (Imanita Parrish Hall) | female | 25.0 | 0 | 1 | 230433 | 26.0000 | NaN | S |
| 882 | 883 | 0 | 3 | Dahlberg, Miss. Gerda Ulrika | female | 22.0 | 0 | 0 | 7552 | 10.5167 | NaN | S |
| 885 | 886 | 0 | 3 | Rice, Mrs. William (Margaret Norton) | female | 39.0 | 0 | 5 | 382652 | 29.1250 | NaN | Q |
| 887 | 888 | 1 | 1 | Graham, Miss. Margaret Edith | female | 19.0 | 0 | 0 | 112053 | 30.0000 | B42 | S |
| 888 | 889 | 0 | 3 | Johnston, Miss. Catherine Helen "Carrie" | female | NaN | 1 | 2 | W./C. 6607 | 23.4500 | NaN | S |
314 rows × 12 columns
Operaciones de indexación con operadores lógicos#
# Pensemos ahora que queremos saber cuales fueron los pasajeros de la clase mayor a 1 que sobrevivieron.
df[df['Pclass'] > 1]
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S |
| 4 | 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S |
| 5 | 6 | 0 | 3 | Moran, Mr. James | male | NaN | 0 | 0 | 330877 | 8.4583 | NaN | Q |
| 7 | 8 | 0 | 3 | Palsson, Master. Gosta Leonard | male | 2.0 | 3 | 1 | 349909 | 21.0750 | NaN | S |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 884 | 885 | 0 | 3 | Sutehall, Mr. Henry Jr | male | 25.0 | 0 | 0 | SOTON/OQ 392076 | 7.0500 | NaN | S |
| 885 | 886 | 0 | 3 | Rice, Mrs. William (Margaret Norton) | female | 39.0 | 0 | 5 | 382652 | 29.1250 | NaN | Q |
| 886 | 887 | 0 | 2 | Montvila, Rev. Juozas | male | 27.0 | 0 | 0 | 211536 | 13.0000 | NaN | S |
| 888 | 889 | 0 | 3 | Johnston, Miss. Catherine Helen "Carrie" | female | NaN | 1 | 2 | W./C. 6607 | 23.4500 | NaN | S |
| 890 | 891 | 0 | 3 | Dooley, Mr. Patrick | male | 32.0 | 0 | 0 | 370376 | 7.7500 | NaN | Q |
675 rows × 12 columns
# Ahora extraigamos los pasajeros que son mujeres, sobrevivieron y mayores de 20 años.
condicion = (df['Sex']=='female') & (df['Survived']==1) & (df['Age']>20) # Note que para unir los filtros usamos los operadores & y |. que son el AND y el OR respectivamente.
# Esta notación de los simbolos es más familiar para los programadores en C, C++, Java, etc.
df[condicion]
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S |
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S |
| 8 | 9 | 1 | 3 | Johnson, Mrs. Oscar W (Elisabeth Vilhelmina Berg) | female | 27.0 | 0 | 2 | 347742 | 11.1333 | NaN | S |
| 11 | 12 | 1 | 1 | Bonnell, Miss. Elizabeth | female | 58.0 | 0 | 0 | 113783 | 26.5500 | C103 | S |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 866 | 867 | 1 | 2 | Duran y More, Miss. Asuncion | female | 27.0 | 1 | 0 | SC/PARIS 2149 | 13.8583 | NaN | C |
| 871 | 872 | 1 | 1 | Beckwith, Mrs. Richard Leonard (Sallie Monypeny) | female | 47.0 | 1 | 1 | 11751 | 52.5542 | D35 | S |
| 874 | 875 | 1 | 2 | Abelson, Mrs. Samuel (Hannah Wizosky) | female | 28.0 | 1 | 0 | P/PP 3381 | 24.0000 | NaN | C |
| 879 | 880 | 1 | 1 | Potter, Mrs. Thomas Jr (Lily Alexenia Wilson) | female | 56.0 | 0 | 1 | 11767 | 83.1583 | C50 | C |
| 880 | 881 | 1 | 2 | Shelley, Mrs. William (Imanita Parrish Hall) | female | 25.0 | 0 | 1 | 230433 | 26.0000 | NaN | S |
144 rows × 12 columns
# modo PRO
df[(df['Sex']=='female') & (df['Survived']==1) & (df['Age']>20)]
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S |
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S |
| 8 | 9 | 1 | 3 | Johnson, Mrs. Oscar W (Elisabeth Vilhelmina Berg) | female | 27.0 | 0 | 2 | 347742 | 11.1333 | NaN | S |
| 11 | 12 | 1 | 1 | Bonnell, Miss. Elizabeth | female | 58.0 | 0 | 0 | 113783 | 26.5500 | C103 | S |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 866 | 867 | 1 | 2 | Duran y More, Miss. Asuncion | female | 27.0 | 1 | 0 | SC/PARIS 2149 | 13.8583 | NaN | C |
| 871 | 872 | 1 | 1 | Beckwith, Mrs. Richard Leonard (Sallie Monypeny) | female | 47.0 | 1 | 1 | 11751 | 52.5542 | D35 | S |
| 874 | 875 | 1 | 2 | Abelson, Mrs. Samuel (Hannah Wizosky) | female | 28.0 | 1 | 0 | P/PP 3381 | 24.0000 | NaN | C |
| 879 | 880 | 1 | 1 | Potter, Mrs. Thomas Jr (Lily Alexenia Wilson) | female | 56.0 | 0 | 1 | 11767 | 83.1583 | C50 | C |
| 880 | 881 | 1 | 2 | Shelley, Mrs. William (Imanita Parrish Hall) | female | 25.0 | 0 | 1 | 230433 | 26.0000 | NaN | S |
144 rows × 12 columns
Operaciones entre columnas#
Si quiero crear una columna nueva puedo simplemente decir df['nueva_columna'] = df['columna1'] + df['columna2'] y se creará una nueva columna con la suma de los valores de las columnas 1 y 2.
Veamos como quedaría el código para realizar estas operaciones. en las que sumemos 10 a la columna Fare y luego ese resultado lo vamos a dividir entre la edad para cada uno de los pasajeros.
df['mi_nueva_columna'] = 10 + df['Fare'] # Podemos crear nuevas columnas a partir de las existentes.
df.head(3)
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | mi_nueva_columna | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S | 17.2500 |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C | 81.2833 |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S | 17.9250 |
df['mi_otra_columna'] = df['mi_nueva_columna'] / df['Age'] # Podemos crear nuevas columnas a partir de las existentes.
df.head(3)
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | mi_nueva_columna | mi_otra_columna | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S | 17.2500 | 0.784091 |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C | 81.2833 | 2.139034 |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S | 17.9250 | 0.689423 |
Ordenar los valores de un resultado#
Si queremos ordenar los valores de un resultado, podemos usar el método sort_values().
# Ordenemos los valores de una columna de forma ascendente, luego de sacar los registros > 20 años.
condicion = (df['Age'] > 20)
df[condicion].sort_values('Age', ascending=True)
| PassengerId | Survived | Pclass | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | Apellido_Pasajero | Nombre_Pasajero | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 227 | 228 | 0 | 3 | male | 20.5 | 0 | 0 | A/5 21173 | 7.2500 | NaN | S | Lovell | Mr. John Hall ("Henry") |
| 37 | 38 | 0 | 3 | male | 21.0 | 0 | 0 | A./5. 2152 | 8.0500 | NaN | S | Cann | Mr. Ernest Charles |
| 56 | 57 | 1 | 2 | female | 21.0 | 0 | 0 | C.A. 31026 | 10.5000 | NaN | S | Rugg | Miss. Emily |
| 436 | 437 | 0 | 3 | female | 21.0 | 2 | 2 | W./C. 6608 | 34.3750 | NaN | S | Ford | Miss. Doolina Margaret "Daisy" |
| 106 | 107 | 1 | 3 | female | 21.0 | 0 | 0 | 343120 | 7.6500 | NaN | S | Salkjelsvik | Miss. Anna Kristine |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 116 | 117 | 0 | 3 | male | 70.5 | 0 | 0 | 370369 | 7.7500 | NaN | Q | Connors | Mr. Patrick |
| 96 | 97 | 0 | 1 | male | 71.0 | 0 | 0 | PC 17754 | 34.6542 | A5 | C | Goldschmidt | Mr. George B |
| 493 | 494 | 0 | 1 | male | 71.0 | 0 | 0 | PC 17609 | 49.5042 | NaN | C | Artagaveytia | Mr. Ramon |
| 851 | 852 | 0 | 3 | male | 74.0 | 0 | 0 | 347060 | 7.7750 | NaN | S | Svensson | Mr. Johan |
| 630 | 631 | 1 | 1 | male | 80.0 | 0 | 0 | 27042 | 30.0000 | A23 | S | Barkworth | Mr. Algernon Henry Wilson |
535 rows × 13 columns
Operaciones sobre columnas#
Si quieres sacar medidas estadísticas de una columna puedes usar los métodos mean(), median(), std(), min(), max(), count(), sum(), entre otros.
Aquellas columnas que tienen valores NaN no se incluyen en el cálculo de estas medidas. Si quieres incluir los valores NaN en el cálculo de estas medidas, puedes usar el argumento skipna=False.
df['Age'].sum() # Podemos hacer operaciones sobre las columnas.
np.float64(21205.17)
df.Age.mean() # También podemos hacerlo de esta forma, usando el nombre de la columna como atributo,
# pero si el nombre de la columna tiene espacios o caracteres especiales toca hacerlo como muestra arriba.
np.float64(29.69911764705882)
Transformar textos de un dataframe#
Ahora miremos otro ejemplo, que pasa si quiero separar de nombre el apellido y el nombre en dos columnas diferentes. Para esto podemos usar el método str.split() que nos permite separar un texto en base a un separador.
df['Apellido'] = df['Name'].str.split(',').str[0] # Podemos crear nuevas columnas a partir de las existentes.
df['Nombre'] = df['Name'].str.split(',').str[1] # Podemos crear nuevas columnas a partir de las existentes.
df.head(3)
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | mi_nueva_columna | mi_otra_columna | Apellido | Nombre | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S | 17.2500 | 0.784091 | Braund | Mr. Owen Harris |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C | 81.2833 | 2.139034 | Cumings | Mrs. John Bradley (Florence Briggs Thayer) |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S | 17.9250 | 0.689423 | Heikkinen | Miss. Laina |
Eliminiar columnas de un dataframe#
# Eliminar las columnas especificas de un DF
df.drop(columns=['mi_nueva_columna'], inplace=True) # Podemos eliminar columnas que no necesitamos.
df.drop(columns=['Name','mi_otra_columna'], inplace=True) # Podemos eliminar columnas que no necesitamos.
df.head(3)
| PassengerId | Survived | Pclass | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | Apellido | Nombre | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S | Braund | Mr. Owen Harris |
| 1 | 2 | 1 | 1 | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C | Cumings | Mrs. John Bradley (Florence Briggs Thayer) |
| 2 | 3 | 1 | 3 | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S | Heikkinen | Miss. Laina |
Cambiar el nombre de las columnas#
Ahora vamos a cambiar los nombres de las columnas al español. Para esto podemos usar el método rename() que nos permite cambiar el nombre de las columnas de un dataframe.
df.rename(columns={'Apellido':'Apellido_Pasajero', 'Nombre':'Nombre_Pasajero'}, inplace=True) # Podemos renombrar columnas. Note que siempre que usamos inplace=True, estamos modificando el dataframe original.
df.head(3)
| PassengerId | Survived | Pclass | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | Apellido_Pasajero | Nombre_Pasajero | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S | Braund | Mr. Owen Harris |
| 1 | 2 | 1 | 1 | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C | Cumings | Mrs. John Bradley (Florence Briggs Thayer) |
| 2 | 3 | 1 | 3 | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S | Heikkinen | Miss. Laina |
Ver solo algunas columnas#
Veamos como se puede seleccionar solo algunas columnas de un dataframe.
pedazo = df[['Nombre_Pasajero', 'Apellido_Pasajero', 'Survived', 'Pclass']]
pedazo.head(3)
| Nombre_Pasajero | Apellido_Pasajero | Survived | Pclass | |
|---|---|---|---|---|
| 0 | Mr. Owen Harris | Braund | 0 | 3 |
| 1 | Mrs. John Bradley (Florence Briggs Thayer) | Cumings | 1 | 1 |
| 2 | Miss. Laina | Heikkinen | 1 | 3 |
Funciones de agregación#
Para realizar operaciones de agregación en un dataframe, podemos usar el método agg(). Este método nos permite aplicar una función de agregación a una o más columnas de un dataframe.
# Funciones de agregación
# Las funciones de agregación nos permiten realizar operaciones sobre un conjunto de datos y resumiros en un solo valor. las funiones sum, mean, median, max, min, etc. son ejemplos de funciones de agregación.
df['Age'].mean() # Por ejemplo, podemos calcular el promedio de la edad de los pasajeros.
df['Age'].max() # O la edad máxima.
# otra sintaxis es usando el método agg
df['Age'].agg('mean') # Por ejemplo, podemos calcular el promedio de la edad de los pasajeros.
np.float64(29.69911764705882)
Funciones de agrupación#
Para realizar operaciones de agrupación en un DataFrame, podemos usar el método groupby(). Este método divide el DataFrame en grupos según los valores de una o más columnas. Luego, podemos aplicar funciones de agregación a estos grupos.

# Vamos a agrupar nuestos datos por sobrevivientes o no y calcular el promedio de la edad de cada grupo.
# Tradicionalmente lo haríamos así:
mean_1 = df[df['Survived']==1]['Age'].mean() # Promedio de la edad de los sobrevivientes.
mean_0 = df[df['Survived']==0]['Age'].mean() # Promedio de la edad de los no sobrevivientes.
print(mean_1)
print(mean_0)
## Entonces tendriamos que conocer cada una de las etiquetas para hacer los filtros, pero con groupby podemos hacerlo de una forma más sencilla.
28.343689655172415
30.62617924528302
df.groupby('Survived')['Age'].sum() # Esto nos retorna una serie en la que saca el valor de la suma de la edad para cada uno de los valores de la columna Survived.
# Esto se puede leer como: Agrupe los registros del dataframe df por la columna Survived y tome los valores de la columna Age y sumelos.
Survived
0 12985.50
1 8219.67
Name: Age, dtype: float64
df.groupby('Survived')['Age'].agg('sum') # Esto es igual a la anterior, solo que usamos el método agg.
df.groupby('Survived')['Age'].aggregate('sum') # Esto es igual a la anterior, solo que usamos el método aggregate.
Survived
0 12985.50
1 8219.67
Name: Age, dtype: float64
Unir varios dataframes usando merge#
Esta es una opción muy útil cuando tenemos varios dataframes y queremos unirlos en uno solo. Para esto podemos usar el método merge() que nos permite unir dos dataframes en base a una o más columnas en común.
import pandas as pd
transactions = pd.read_csv('data/transactions.csv', index_col=0)
requests = pd.read_csv('data/requests.csv', index_col=0)
# Revisemos los dataframes obtenidos
transactions.head(2)
| sender | receiver | amount | sent_date | |
|---|---|---|---|---|
| 0 | stein | smoyer | 49.03 | 2018-01-24 |
| 1 | holden4580 | joshua.henry | 34.64 | 2018-02-06 |
# Revisemos los dataframes obtenidos
requests.head(2)
| from_user | to_user | amount | request_date | |
|---|---|---|---|---|
| 0 | chad.chen | paula7980 | 78.61 | 2018-02-12 |
| 1 | kallen | lmoore | 1.94 | 2018-02-23 |
Me gustaría ver todas las solicitudes que tienen una transacción coincidente basada en los usuarios y el monto involucrado.
Para hacer esto, combinaremos ambos conjuntos de datos.
Crearemos un nuevo conjunto de datos utilizando el método DataFrame.merge.
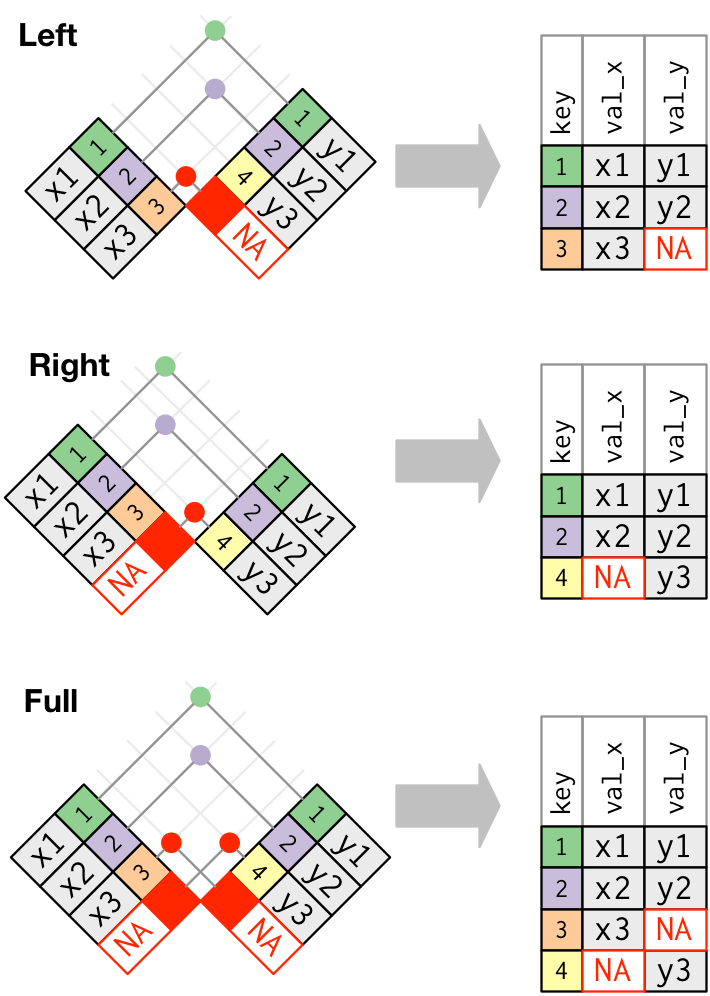
# Como estamos llamando a merge en el DataFrame `requests`, se considera el lado izquierdo
successful_requests = requests.merge(
# Y `transactions` es el lado derecho
transactions,
# Así que ahora alineamos las columnas que harán que la unión tenga sentido. esto es decir cual de la izquierda corresponde a la de la derecha.
left_on=['from_user', 'to_user', 'amount'],
right_on=['receiver', 'sender', 'amount']
)
# Veamos cómo nos fue
successful_requests.head()
| from_user | to_user | amount | request_date | sender | receiver | sent_date | |
|---|---|---|---|---|---|---|---|
| 0 | chad.chen | paula7980 | 78.61 | 2018-02-12 | paula7980 | chad.chen | 2018-07-15 |
| 1 | kallen | lmoore | 1.94 | 2018-02-23 | lmoore | kallen | 2018-03-05 |
| 2 | gregory.blackwell | rodriguez5768 | 30.57 | 2018-03-04 | rodriguez5768 | gregory.blackwell | 2018-03-17 |
| 3 | kristina.miller | john.hardy | 77.05 | 2018-03-12 | john.hardy | kristina.miller | 2018-04-25 |
| 4 | lacey8987 | mcguire | 54.09 | 2018-03-13 | mcguire | lacey8987 | 2018-06-28 |
Retos#
Reto 1#
Vamos a usar la data de sobrevivientes del Titanic. Vamos responder a los siguientes enunciados:
¿Cuántos pasajeros sobrevivieron y cuántos no sobrevivieron?
¿Cuántos pasajeros de cada clase sobrevivieron?
¿Cuántos hombres y mujeres sobrevivieron?
Usando groupby(), calcula la edad promedio para cada sexo.
Calcula tasa promedio de supervivencia para todos los pasajeros.
Calcula este ratio de supervivencia para todos los pasajeros menores de 25 años (recuerda: filtrado/indexación booleana)
# Tu código aquí