
Tutorial de Spark: Aprendiendo Apache Spark#
Adaptado de GitHub
Durante este tutorial cubriremos:#
Parte 1: Uso básico del cuaderno e integración con Python#
Parte 3: Uso de RDDs y encadenamiento de transformaciones y acciones#
Parte 4: Funciones Lambda#
Parte 5: Acciones adicionales de RDD#
Parte 6: Transformaciones adicionales de RDD#
Parte 7: Caché de RDDs y opciones de almacenamiento#
Las siguientes transformaciones serán cubiertas:#
map(),mapPartitions(),mapPartitionsWithIndex(),filter(),flatMap(),reduceByKey(),groupByKey()
Las siguientes acciones serán cubiertas:#
first(),take(),takeSample(),takeOrdered(),collect(),count(),countByValue(),reduce(),top()
También cubierto:#
cache(),unpersist(),id(),setName()
Nota que, para referencia, puedes consultar los detalles de estos métodos en la API de Python de Spark#
Part 0: Google Colaboratory environment set up#
# Download Java
!apt-get install openjdk-8-jdk-headless -qq > /dev/null
# Next, we will install Apache Spark 3.0.1 with Hadoop 2.7 from here.
!wget https://dlcdn.apache.org/spark/spark-3.5.6/spark-3.5.6-bin-hadoop3.tgz
# Now, we just need to unzip that folder.
!tar xf spark-3.5.6-bin-hadoop3.tgz
# Setting JVM and Spark path variables
import os
os.environ["JAVA_HOME"] = "/usr/lib/jvm/java-8-openjdk-amd64"
os.environ["SPARK_HOME"] = "/content/spark-3.5.6-bin-hadoop3"
# Installing required packages
!pip install pyspark==3.5.6
!pip install findspark
import findspark
findspark.init()
--2025-09-13 19:13:18-- https://dlcdn.apache.org/spark/spark-3.5.6/spark-3.5.6-bin-hadoop3.tgz
Resolving dlcdn.apache.org (dlcdn.apache.org)... 151.101.2.132, 2a04:4e42::644
Connecting to dlcdn.apache.org (dlcdn.apache.org)|151.101.2.132|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 400923510 (382M) [application/x-gzip]
Saving to: ‘spark-3.5.6-bin-hadoop3.tgz’
spark-3.5.6-bin-had 100%[===================>] 382.35M 302MB/s in 1.3s
2025-09-13 19:13:35 (302 MB/s) - ‘spark-3.5.6-bin-hadoop3.tgz’ saved [400923510/400923510]
Collecting pyspark==3.5.6
Downloading pyspark-3.5.6.tar.gz (317.4 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 317.4/317.4 MB 4.3 MB/s eta 0:00:00
?25h Preparing metadata (setup.py) ... ?25l?25hdone
Requirement already satisfied: py4j==0.10.9.7 in /usr/local/lib/python3.12/dist-packages (from pyspark==3.5.6) (0.10.9.7)
Building wheels for collected packages: pyspark
Building wheel for pyspark (setup.py) ... ?25l?25hdone
Created wheel for pyspark: filename=pyspark-3.5.6-py2.py3-none-any.whl size=317895798 sha256=3223be3a1f0f0f064c32140c9d086f7bdfa796afc20b50dcdb8174976e239a73
Stored in directory: /root/.cache/pip/wheels/64/62/f3/ec15656ea4ada0523cae62a1827fe7beb55d3c8c87174aad4a
Successfully built pyspark
Installing collected packages: pyspark
Attempting uninstall: pyspark
Found existing installation: pyspark 3.5.1
Uninstalling pyspark-3.5.1:
Successfully uninstalled pyspark-3.5.1
Successfully installed pyspark-3.5.6
Collecting findspark
Downloading findspark-2.0.1-py2.py3-none-any.whl.metadata (352 bytes)
Downloading findspark-2.0.1-py2.py3-none-any.whl (4.4 kB)
Installing collected packages: findspark
Successfully installed findspark-2.0.1
# Crear un SparkContext (sc)
from pyspark import SparkContext
sc = SparkContext("local", "example")
Parte 1: Uso básico del cuaderno e integración con Python#
(1a) Notebook usage#
####Un cuaderno está compuesto por una secuencia lineal de celdas. Estas celdas pueden contener markdown o código, pero no mezclaremos ambos en una sola celda. Cuando se ejecuta una celda de markdown, se muestra texto formateado, imágenes y enlaces, al igual que HTML en una página web normal. El texto que estás leyendo ahora es parte de una celda de markdown. Las celdas de código de Python te permiten ejecutar comandos arbitrarios de Python, como en cualquier intérprete de Python. Coloca tu cursor dentro de la celda a continuación y presiona «Shift» + «Enter» para ejecutar el código y avanzar a la siguiente celda. También puedes presionar «Ctrl» + «Enter» para ejecutar el código y permanecer en la celda. Estos comandos funcionan igual en celdas de markdown y de código.
# Esta es una celda Python. Puedes ejecutar código Python normal aquí...
print('The sum of 1 and 1 is {0}'.format(1+1))
The sum of 1 and 1 is 2
# Aquí hay otra celda de Python, esta vez con una declaración de variable (x) y una sentencia if:
x = 42
if x > 40:
print('The sum of 1 and 2 is {0}'.format(1+2))
The sum of 1 and 2 is 3
(1b) Estado del cuaderno#
A medida que trabajas en un cuaderno, es importante que ejecutes todas las celdas de código. El cuaderno es con estado, lo que significa que las variables y sus valores se conservan hasta que el cuaderno se desconecta (en Databricks Cloud) o se reinicia el kernel (en cuadernos IPython). Si no ejecutas todas las celdas de código a medida que avanzas por el cuaderno, tus variables no se inicializarán correctamente y el código posterior podría fallar. También necesitarás volver a ejecutar cualquier celda que hayas modificado para que los cambios estén disponibles en otras celdas.#
# Esta celda depende de que x ya esté definida.
# Si no ejecutáramos las celdas de la parte (1a) este código fallaría.
print(x * 2)
84
(1c) Importar Librerias#
Podemos importar bibliotecas estándar de Python (módulos) de la manera habitual. Una declaración import importará el módulo especificado. En este tutorial y en futuros laboratorios, proporcionaremos las importaciones necesarias.#
# Importar la biblioteca de expresiones regulares
import re
m = re.search('(?<=abc)def', 'abcdef')
m.group(0)
'def'
# Importar la biblioteca datetime
import datetime
print('This was last run on: {0}'.format(datetime.datetime.now()))
This was last run on: 2025-09-06 15:59:22.703444
Parte 2: Una introducción al uso de Apache Spark con la API de pySpark de Python ejecutándose en el navegador#
Contexto de Spark#
En Spark, la comunicación ocurre entre un driver y los ejecutores. El driver tiene trabajos de Spark que necesita ejecutar y estos trabajos se dividen en tareas que se envían a los ejecutores para su finalización. Los resultados de estas tareas se entregan de vuelta al driver.#
En la parte 1, vimos que el código Python normal puede ejecutarse a través de celdas. Al usar Databricks Cloud, este código se ejecuta en la Máquina Virtual Java (JVM) del driver de Spark y no en la JVM de un ejecutor, y al usar un cuaderno IPython, se ejecuta dentro del kernel asociado con el cuaderno. Dado que no se está utilizando ninguna funcionalidad de Spark, no se lanzan tareas en los ejecutores.#
Para usar Spark y su API necesitaremos usar un SparkContext. Al ejecutar Spark, inicias una nueva aplicación de Spark creando un SparkContext. Cuando se crea el SparkContext, solicita al master algunos núcleos para usar en el trabajo. El master reserva estos núcleos solo para ti; no se usarán para otras aplicaciones. Al usar Databricks Cloud o la máquina virtual provisionada para esta clase, el SparkContext se crea automáticamente como sc.#
(2a) Ejemplo de Clúster#
El diagrama a continuación muestra un clúster de ejemplo, donde los núcleos asignados para una aplicación están delineados en púrpura.#
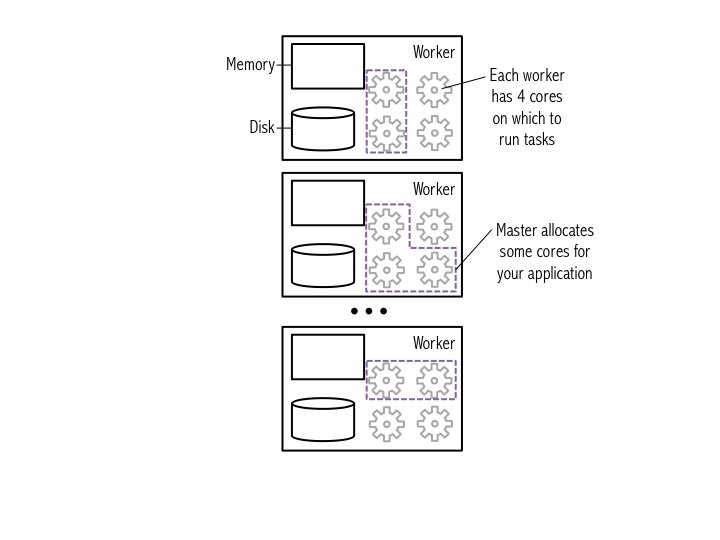
Puedes ver los detalles de tu aplicación Spark en la interfaz web de Spark. La interfaz web es accesible en Databricks Cloud yendo a «Clusters» y luego haciendo clic en el enlace «View Spark UI» para tu clúster. Al ejecutarlo localmente, lo encontrarás en localhost:4040. En la interfaz web, bajo la pestaña «Jobs», puedes ver una lista de trabajos que han sido programados o ejecutados. Es probable que no haya nada interesante aquí todavía porque no hemos ejecutado ningún trabajo, pero volveremos a esta página más tarde.#
A un alto nivel, cada aplicación Spark consta de un programa driver que lanza varias operaciones paralelas en Máquinas Virtuales Java (JVMs) de ejecutores que se ejecutan en un clúster o localmente en la misma máquina. En Databricks Cloud, «Databricks Shell» es el programa driver. Al ejecutarlo localmente, «PySparkShell» es el programa driver. En todos los casos, este programa driver contiene el bucle principal del programa y crea conjuntos de datos distribuidos en el clúster, luego aplica operaciones (transformaciones y acciones) a esos conjuntos de datos.#
Los programas driver acceden a Spark a través de un objeto SparkContext, que representa una conexión a un clúster de computación. Un objeto de contexto Spark (sc) es el punto de entrada principal para la funcionalidad de Spark. Un contexto Spark se puede usar para crear Conjuntos de Datos Distribuidos Resilientes (RDDs) en un clúster.#
Intenta imprimir sc para ver su tipo.#
# Mostrar el tipo de Spark Context sc
print(type(sc))
<class 'pyspark.context.SparkContext'>
(2b) Atributos de SparkContext#
Puedes usar la función dir() de Python para obtener una lista de todos los atributos (incluidos los métodos) accesibles a través del objeto sc.#
# Listar los atributos de sc
dir(sc)
['PACKAGE_EXTENSIONS',
'__annotations__',
'__class__',
'__delattr__',
'__dict__',
'__dir__',
'__doc__',
'__enter__',
'__eq__',
'__exit__',
'__format__',
'__ge__',
'__getattribute__',
'__getnewargs__',
'__getstate__',
'__gt__',
'__hash__',
'__init__',
'__init_subclass__',
'__le__',
'__lt__',
'__module__',
'__ne__',
'__new__',
'__reduce__',
'__reduce_ex__',
'__repr__',
'__setattr__',
'__sizeof__',
'__str__',
'__subclasshook__',
'__weakref__',
'_accumulatorServer',
'_active_spark_context',
'_assert_on_driver',
'_batchSize',
'_callsite',
'_checkpointFile',
'_conf',
'_dictToJavaMap',
'_do_init',
'_encryption_enabled',
'_ensure_initialized',
'_gateway',
'_getJavaStorageLevel',
'_initialize_context',
'_javaAccumulator',
'_jsc',
'_jvm',
'_lock',
'_next_accum_id',
'_pickled_broadcast_vars',
'_python_includes',
'_repr_html_',
'_serialize_to_jvm',
'_temp_dir',
'_unbatched_serializer',
'accumulator',
'addArchive',
'addFile',
'addJobTag',
'addPyFile',
'appName',
'applicationId',
'binaryFiles',
'binaryRecords',
'broadcast',
'cancelAllJobs',
'cancelJobGroup',
'cancelJobsWithTag',
'clearJobTags',
'defaultMinPartitions',
'defaultParallelism',
'dump_profiles',
'emptyRDD',
'environment',
'getCheckpointDir',
'getConf',
'getJobTags',
'getLocalProperty',
'getOrCreate',
'hadoopFile',
'hadoopRDD',
'listArchives',
'listFiles',
'master',
'newAPIHadoopFile',
'newAPIHadoopRDD',
'parallelize',
'pickleFile',
'profiler_collector',
'pythonExec',
'pythonVer',
'range',
'removeJobTag',
'resources',
'runJob',
'sequenceFile',
'serializer',
'setCheckpointDir',
'setInterruptOnCancel',
'setJobDescription',
'setJobGroup',
'setLocalProperty',
'setLogLevel',
'setSystemProperty',
'show_profiles',
'sparkHome',
'sparkUser',
'startTime',
'statusTracker',
'stop',
'textFile',
'uiWebUrl',
'union',
'version',
'wholeTextFiles']
(2c) Obtener ayuda#
Alternativamente, puedes usar la función help() de Python para obtener una lista más fácil de leer de todos los atributos, incluidos ejemplos, que tiene el objeto sc.#
# Utiliza la ayuda para obtener información más detallada
help(sc)
Help on SparkContext in module pyspark.context object:
class SparkContext(builtins.object)
| SparkContext(master: Optional[str] = None, appName: Optional[str] = None, sparkHome: Optional[str] = None, pyFiles: Optional[List[str]] = None, environment: Optional[Dict[str, Any]] = None, batchSize: int = 0, serializer: 'Serializer' = CloudPickleSerializer(), conf: Optional[pyspark.conf.SparkConf] = None, gateway: Optional[py4j.java_gateway.JavaGateway] = None, jsc: Optional[py4j.java_gateway.JavaObject] = None, profiler_cls: Type[pyspark.profiler.BasicProfiler] = <class 'pyspark.profiler.BasicProfiler'>, udf_profiler_cls: Type[pyspark.profiler.UDFBasicProfiler] = <class 'pyspark.profiler.UDFBasicProfiler'>, memory_profiler_cls: Type[pyspark.profiler.MemoryProfiler] = <class 'pyspark.profiler.MemoryProfiler'>)
|
| Main entry point for Spark functionality. A SparkContext represents the
| connection to a Spark cluster, and can be used to create :class:`RDD` and
| broadcast variables on that cluster.
|
| When you create a new SparkContext, at least the master and app name should
| be set, either through the named parameters here or through `conf`.
|
| Parameters
| ----------
| master : str, optional
| Cluster URL to connect to (e.g. mesos://host:port, spark://host:port, local[4]).
| appName : str, optional
| A name for your job, to display on the cluster web UI.
| sparkHome : str, optional
| Location where Spark is installed on cluster nodes.
| pyFiles : list, optional
| Collection of .zip or .py files to send to the cluster
| and add to PYTHONPATH. These can be paths on the local file
| system or HDFS, HTTP, HTTPS, or FTP URLs.
| environment : dict, optional
| A dictionary of environment variables to set on
| worker nodes.
| batchSize : int, optional, default 0
| The number of Python objects represented as a single
| Java object. Set 1 to disable batching, 0 to automatically choose
| the batch size based on object sizes, or -1 to use an unlimited
| batch size
| serializer : :class:`Serializer`, optional, default :class:`CPickleSerializer`
| The serializer for RDDs.
| conf : :class:`SparkConf`, optional
| An object setting Spark properties.
| gateway : class:`py4j.java_gateway.JavaGateway`, optional
| Use an existing gateway and JVM, otherwise a new JVM
| will be instantiated. This is only used internally.
| jsc : class:`py4j.java_gateway.JavaObject`, optional
| The JavaSparkContext instance. This is only used internally.
| profiler_cls : type, optional, default :class:`BasicProfiler`
| A class of custom Profiler used to do profiling
| udf_profiler_cls : type, optional, default :class:`UDFBasicProfiler`
| A class of custom Profiler used to do udf profiling
|
| Notes
| -----
| Only one :class:`SparkContext` should be active per JVM. You must `stop()`
| the active :class:`SparkContext` before creating a new one.
|
| :class:`SparkContext` instance is not supported to share across multiple
| processes out of the box, and PySpark does not guarantee multi-processing execution.
| Use threads instead for concurrent processing purpose.
|
| Examples
| --------
| >>> from pyspark.context import SparkContext
| >>> sc = SparkContext('local', 'test')
| >>> sc2 = SparkContext('local', 'test2') # doctest: +IGNORE_EXCEPTION_DETAIL
| Traceback (most recent call last):
| ...
| ValueError: ...
|
| Methods defined here:
|
| __enter__(self) -> 'SparkContext'
| Enable 'with SparkContext(...) as sc: app(sc)' syntax.
|
| __exit__(self, type: Optional[Type[BaseException]], value: Optional[BaseException], trace: Optional[traceback]) -> None
| Enable 'with SparkContext(...) as sc: app' syntax.
|
| Specifically stop the context on exit of the with block.
|
| __getnewargs__(self) -> NoReturn
|
| __init__(self, master: Optional[str] = None, appName: Optional[str] = None, sparkHome: Optional[str] = None, pyFiles: Optional[List[str]] = None, environment: Optional[Dict[str, Any]] = None, batchSize: int = 0, serializer: 'Serializer' = CloudPickleSerializer(), conf: Optional[pyspark.conf.SparkConf] = None, gateway: Optional[py4j.java_gateway.JavaGateway] = None, jsc: Optional[py4j.java_gateway.JavaObject] = None, profiler_cls: Type[pyspark.profiler.BasicProfiler] = <class 'pyspark.profiler.BasicProfiler'>, udf_profiler_cls: Type[pyspark.profiler.UDFBasicProfiler] = <class 'pyspark.profiler.UDFBasicProfiler'>, memory_profiler_cls: Type[pyspark.profiler.MemoryProfiler] = <class 'pyspark.profiler.MemoryProfiler'>)
| Initialize self. See help(type(self)) for accurate signature.
|
| __repr__(self) -> str
| Return repr(self).
|
| accumulator(self, value: ~T, accum_param: Optional[ForwardRef('AccumulatorParam[T]')] = None) -> 'Accumulator[T]'
| Create an :class:`Accumulator` with the given initial value, using a given
| :class:`AccumulatorParam` helper object to define how to add values of the
| data type if provided. Default AccumulatorParams are used for integers
| and floating-point numbers if you do not provide one. For other types,
| a custom AccumulatorParam can be used.
|
| .. versionadded:: 0.7.0
|
| Parameters
| ----------
| value : T
| initialized value
| accum_param : :class:`pyspark.AccumulatorParam`, optional
| helper object to define how to add values
|
| Returns
| -------
| :class:`Accumulator`
| `Accumulator` object, a shared variable that can be accumulated
|
| Examples
| --------
| >>> acc = sc.accumulator(9)
| >>> acc.value
| 9
| >>> acc += 1
| >>> acc.value
| 10
|
| Accumulator object can be accumulated in RDD operations:
|
| >>> rdd = sc.range(5)
| >>> def f(x):
| ... global acc
| ... acc += 1
| ...
| >>> rdd.foreach(f)
| >>> acc.value
| 15
|
| addArchive(self, path: str) -> None
| Add an archive to be downloaded with this Spark job on every node.
| The `path` passed can be either a local file, a file in HDFS
| (or other Hadoop-supported filesystems), or an HTTP, HTTPS or
| FTP URI.
|
| To access the file in Spark jobs, use :meth:`SparkFiles.get` with the
| filename to find its download/unpacked location. The given path should
| be one of .zip, .tar, .tar.gz, .tgz and .jar.
|
| .. versionadded:: 3.3.0
|
| Parameters
| ----------
| path : str
| can be either a local file, a file in HDFS (or other Hadoop-supported
| filesystems), or an HTTP, HTTPS or FTP URI. To access the file in Spark jobs,
| use :meth:`SparkFiles.get` to find its download location.
|
| See Also
| --------
| :meth:`SparkContext.listArchives`
| :meth:`SparkFiles.get`
|
| Notes
| -----
| A path can be added only once. Subsequent additions of the same path are ignored.
| This API is experimental.
|
| Examples
| --------
| Creates a zipped file that contains a text file written '100'.
|
| >>> import os
| >>> import tempfile
| >>> import zipfile
| >>> from pyspark import SparkFiles
|
| >>> with tempfile.TemporaryDirectory() as d:
| ... path = os.path.join(d, "test.txt")
| ... with open(path, "w") as f:
| ... _ = f.write("100")
| ...
| ... zip_path1 = os.path.join(d, "test1.zip")
| ... with zipfile.ZipFile(zip_path1, "w", zipfile.ZIP_DEFLATED) as z:
| ... z.write(path, os.path.basename(path))
| ...
| ... zip_path2 = os.path.join(d, "test2.zip")
| ... with zipfile.ZipFile(zip_path2, "w", zipfile.ZIP_DEFLATED) as z:
| ... z.write(path, os.path.basename(path))
| ...
| ... sc.addArchive(zip_path1)
| ... arch_list1 = sorted(sc.listArchives)
| ...
| ... sc.addArchive(zip_path2)
| ... arch_list2 = sorted(sc.listArchives)
| ...
| ... # add zip_path2 twice, this addition will be ignored
| ... sc.addArchive(zip_path2)
| ... arch_list3 = sorted(sc.listArchives)
| ...
| ... def func(iterator):
| ... with open("%s/test.txt" % SparkFiles.get("test1.zip")) as f:
| ... mul = int(f.readline())
| ... return [x * mul for x in iterator]
| ...
| ... collected = sc.parallelize([1, 2, 3, 4]).mapPartitions(func).collect()
|
| >>> arch_list1
| ['file:/.../test1.zip']
| >>> arch_list2
| ['file:/.../test1.zip', 'file:/.../test2.zip']
| >>> arch_list3
| ['file:/.../test1.zip', 'file:/.../test2.zip']
| >>> collected
| [100, 200, 300, 400]
|
| addFile(self, path: str, recursive: bool = False) -> None
| Add a file to be downloaded with this Spark job on every node.
| The `path` passed can be either a local file, a file in HDFS
| (or other Hadoop-supported filesystems), or an HTTP, HTTPS or
| FTP URI.
|
| To access the file in Spark jobs, use :meth:`SparkFiles.get` with the
| filename to find its download location.
|
| A directory can be given if the recursive option is set to True.
| Currently directories are only supported for Hadoop-supported filesystems.
|
| .. versionadded:: 0.7.0
|
| Parameters
| ----------
| path : str
| can be either a local file, a file in HDFS (or other Hadoop-supported
| filesystems), or an HTTP, HTTPS or FTP URI. To access the file in Spark jobs,
| use :meth:`SparkFiles.get` to find its download location.
| recursive : bool, default False
| whether to recursively add files in the input directory
|
| See Also
| --------
| :meth:`SparkContext.listFiles`
| :meth:`SparkContext.addPyFile`
| :meth:`SparkFiles.get`
|
| Notes
| -----
| A path can be added only once. Subsequent additions of the same path are ignored.
|
| Examples
| --------
| >>> import os
| >>> import tempfile
| >>> from pyspark import SparkFiles
|
| >>> with tempfile.TemporaryDirectory() as d:
| ... path1 = os.path.join(d, "test1.txt")
| ... with open(path1, "w") as f:
| ... _ = f.write("100")
| ...
| ... path2 = os.path.join(d, "test2.txt")
| ... with open(path2, "w") as f:
| ... _ = f.write("200")
| ...
| ... sc.addFile(path1)
| ... file_list1 = sorted(sc.listFiles)
| ...
| ... sc.addFile(path2)
| ... file_list2 = sorted(sc.listFiles)
| ...
| ... # add path2 twice, this addition will be ignored
| ... sc.addFile(path2)
| ... file_list3 = sorted(sc.listFiles)
| ...
| ... def func(iterator):
| ... with open(SparkFiles.get("test1.txt")) as f:
| ... mul = int(f.readline())
| ... return [x * mul for x in iterator]
| ...
| ... collected = sc.parallelize([1, 2, 3, 4]).mapPartitions(func).collect()
|
| >>> file_list1
| ['file:/.../test1.txt']
| >>> file_list2
| ['file:/.../test1.txt', 'file:/.../test2.txt']
| >>> file_list3
| ['file:/.../test1.txt', 'file:/.../test2.txt']
| >>> collected
| [100, 200, 300, 400]
|
| addJobTag(self, tag: str) -> None
| Add a tag to be assigned to all the jobs started by this thread.
|
| .. versionadded:: 3.5.0
|
| Parameters
| ----------
| tag : str
| The tag to be added. Cannot contain ',' (comma) character.
|
| See Also
| --------
| :meth:`SparkContext.removeJobTag`
| :meth:`SparkContext.getJobTags`
| :meth:`SparkContext.clearJobTags`
| :meth:`SparkContext.cancelJobsWithTag`
| :meth:`SparkContext.setInterruptOnCancel`
|
| Examples
| --------
| >>> import threading
| >>> from time import sleep
| >>> from pyspark import InheritableThread
| >>> sc.setInterruptOnCancel(interruptOnCancel=True)
| >>> result = "Not Set"
| >>> lock = threading.Lock()
| >>> def map_func(x):
| ... sleep(100)
| ... raise RuntimeError("Task should have been cancelled")
| ...
| >>> def start_job(x):
| ... global result
| ... try:
| ... sc.addJobTag("job_to_cancel")
| ... result = sc.parallelize(range(x)).map(map_func).collect()
| ... except Exception as e:
| ... result = "Cancelled"
| ... lock.release()
| ...
| >>> def stop_job():
| ... sleep(5)
| ... sc.cancelJobsWithTag("job_to_cancel")
| ...
| >>> suppress = lock.acquire()
| >>> suppress = InheritableThread(target=start_job, args=(10,)).start()
| >>> suppress = InheritableThread(target=stop_job).start()
| >>> suppress = lock.acquire()
| >>> print(result)
| Cancelled
| >>> sc.clearJobTags()
|
| addPyFile(self, path: str) -> None
| Add a .py or .zip dependency for all tasks to be executed on this
| SparkContext in the future. The `path` passed can be either a local
| file, a file in HDFS (or other Hadoop-supported filesystems), or an
| HTTP, HTTPS or FTP URI.
|
| .. versionadded:: 0.7.0
|
| Parameters
| ----------
| path : str
| can be either a .py file or .zip dependency.
|
| See Also
| --------
| :meth:`SparkContext.addFile`
|
| Notes
| -----
| A path can be added only once. Subsequent additions of the same path are ignored.
|
| binaryFiles(self, path: str, minPartitions: Optional[int] = None) -> pyspark.rdd.RDD[typing.Tuple[str, bytes]]
| Read a directory of binary files from HDFS, a local file system
| (available on all nodes), or any Hadoop-supported file system URI
| as a byte array. Each file is read as a single record and returned
| in a key-value pair, where the key is the path of each file, the
| value is the content of each file.
|
| .. versionadded:: 1.3.0
|
| Parameters
| ----------
| path : str
| directory to the input data files, the path can be comma separated
| paths as a list of inputs
| minPartitions : int, optional
| suggested minimum number of partitions for the resulting RDD
|
| Returns
| -------
| :class:`RDD`
| RDD representing path-content pairs from the file(s).
|
| Notes
| -----
| Small files are preferred, large file is also allowable, but may cause bad performance.
|
| See Also
| --------
| :meth:`SparkContext.binaryRecords`
|
| Examples
| --------
| >>> import os
| >>> import tempfile
| >>> with tempfile.TemporaryDirectory() as d:
| ... # Write a temporary binary file
| ... with open(os.path.join(d, "1.bin"), "wb") as f1:
| ... _ = f1.write(b"binary data I")
| ...
| ... # Write another temporary binary file
| ... with open(os.path.join(d, "2.bin"), "wb") as f2:
| ... _ = f2.write(b"binary data II")
| ...
| ... collected = sorted(sc.binaryFiles(d).collect())
|
| >>> collected
| [('.../1.bin', b'binary data I'), ('.../2.bin', b'binary data II')]
|
| binaryRecords(self, path: str, recordLength: int) -> pyspark.rdd.RDD[bytes]
| Load data from a flat binary file, assuming each record is a set of numbers
| with the specified numerical format (see ByteBuffer), and the number of
| bytes per record is constant.
|
| .. versionadded:: 1.3.0
|
| Parameters
| ----------
| path : str
| Directory to the input data files
| recordLength : int
| The length at which to split the records
|
| Returns
| -------
| :class:`RDD`
| RDD of data with values, represented as byte arrays
|
| See Also
| --------
| :meth:`SparkContext.binaryFiles`
|
| Examples
| --------
| >>> import os
| >>> import tempfile
| >>> with tempfile.TemporaryDirectory() as d:
| ... # Write a temporary file
| ... with open(os.path.join(d, "1.bin"), "w") as f:
| ... for i in range(3):
| ... _ = f.write("%04d" % i)
| ...
| ... # Write another file
| ... with open(os.path.join(d, "2.bin"), "w") as f:
| ... for i in [-1, -2, -10]:
| ... _ = f.write("%04d" % i)
| ...
| ... collected = sorted(sc.binaryRecords(d, 4).collect())
|
| >>> collected
| [b'-001', b'-002', b'-010', b'0000', b'0001', b'0002']
|
| broadcast(self, value: ~T) -> 'Broadcast[T]'
| Broadcast a read-only variable to the cluster, returning a :class:`Broadcast`
| object for reading it in distributed functions. The variable will
| be sent to each cluster only once.
|
| .. versionadded:: 0.7.0
|
| Parameters
| ----------
| value : T
| value to broadcast to the Spark nodes
|
| Returns
| -------
| :class:`Broadcast`
| :class:`Broadcast` object, a read-only variable cached on each machine
|
| Examples
| --------
| >>> mapping = {1: 10001, 2: 10002}
| >>> bc = sc.broadcast(mapping)
|
| >>> rdd = sc.range(5)
| >>> rdd2 = rdd.map(lambda i: bc.value[i] if i in bc.value else -1)
| >>> rdd2.collect()
| [-1, 10001, 10002, -1, -1]
|
| >>> bc.destroy()
|
| cancelAllJobs(self) -> None
| Cancel all jobs that have been scheduled or are running.
|
| .. versionadded:: 1.1.0
|
| See Also
| --------
| :meth:`SparkContext.cancelJobGroup`
| :meth:`SparkContext.cancelJobsWithTag`
| :meth:`SparkContext.runJob`
|
| cancelJobGroup(self, groupId: str) -> None
| Cancel active jobs for the specified group. See :meth:`SparkContext.setJobGroup`.
| for more information.
|
| .. versionadded:: 1.1.0
|
| Parameters
| ----------
| groupId : str
| The group ID to cancel the job.
|
| See Also
| --------
| :meth:`SparkContext.setJobGroup`
|
| cancelJobsWithTag(self, tag: str) -> None
| Cancel active jobs that have the specified tag. See
| :meth:`SparkContext.addJobTag`.
|
| .. versionadded:: 3.5.0
|
| Parameters
| ----------
| tag : str
| The tag to be cancelled. Cannot contain ',' (comma) character.
|
| See Also
| --------
| :meth:`SparkContext.addJobTag`
| :meth:`SparkContext.removeJobTag`
| :meth:`SparkContext.getJobTags`
| :meth:`SparkContext.clearJobTags`
| :meth:`SparkContext.setInterruptOnCancel`
|
| clearJobTags(self) -> None
| Clear the current thread's job tags.
|
| .. versionadded:: 3.5.0
|
| See Also
| --------
| :meth:`SparkContext.addJobTag`
| :meth:`SparkContext.removeJobTag`
| :meth:`SparkContext.getJobTags`
| :meth:`SparkContext.cancelJobsWithTag`
| :meth:`SparkContext.setInterruptOnCancel`
|
| Examples
| --------
| >>> sc.addJobTag("job_to_cancel")
| >>> sc.clearJobTags()
| >>> sc.getJobTags()
| set()
|
| dump_profiles(self, path: str) -> None
| Dump the profile stats into directory `path`
|
| .. versionadded:: 1.2.0
|
| See Also
| --------
| :meth:`SparkContext.show_profiles`
|
| emptyRDD(self) -> pyspark.rdd.RDD[typing.Any]
| Create an :class:`RDD` that has no partitions or elements.
|
| .. versionadded:: 1.5.0
|
| Returns
| -------
| :class:`RDD`
| An empty RDD
|
| Examples
| --------
| >>> sc.emptyRDD()
| EmptyRDD...
| >>> sc.emptyRDD().count()
| 0
|
| getCheckpointDir(self) -> Optional[str]
| Return the directory where RDDs are checkpointed. Returns None if no
| checkpoint directory has been set.
|
| .. versionadded:: 3.1.0
|
| See Also
| --------
| :meth:`SparkContext.setCheckpointDir`
| :meth:`RDD.checkpoint`
| :meth:`RDD.getCheckpointFile`
|
| getConf(self) -> pyspark.conf.SparkConf
| Return a copy of this SparkContext's configuration :class:`SparkConf`.
|
| .. versionadded:: 2.1.0
|
| getJobTags(self) -> Set[str]
| Get the tags that are currently set to be assigned to all the jobs started by this thread.
|
| .. versionadded:: 3.5.0
|
| Returns
| -------
| set of str
| the tags that are currently set to be assigned to all the jobs started by this thread.
|
| See Also
| --------
| :meth:`SparkContext.addJobTag`
| :meth:`SparkContext.removeJobTag`
| :meth:`SparkContext.clearJobTags`
| :meth:`SparkContext.cancelJobsWithTag`
| :meth:`SparkContext.setInterruptOnCancel`
|
| Examples
| --------
| >>> sc.addJobTag("job_to_cancel")
| >>> sc.getJobTags()
| {'job_to_cancel'}
| >>> sc.clearJobTags()
|
| getLocalProperty(self, key: str) -> Optional[str]
| Get a local property set in this thread, or null if it is missing. See
| :meth:`setLocalProperty`.
|
| .. versionadded:: 1.0.0
|
| See Also
| --------
| :meth:`SparkContext.setLocalProperty`
|
| hadoopFile(self, path: str, inputFormatClass: str, keyClass: str, valueClass: str, keyConverter: Optional[str] = None, valueConverter: Optional[str] = None, conf: Optional[Dict[str, str]] = None, batchSize: int = 0) -> pyspark.rdd.RDD[typing.Tuple[~T, ~U]]
| Read an 'old' Hadoop InputFormat with arbitrary key and value class from HDFS,
| a local file system (available on all nodes), or any Hadoop-supported file system URI.
| The mechanism is the same as for meth:`SparkContext.sequenceFile`.
|
| .. versionadded:: 1.1.0
|
| A Hadoop configuration can be passed in as a Python dict. This will be converted into a
| Configuration in Java.
|
| Parameters
| ----------
| path : str
| path to Hadoop file
| inputFormatClass : str
| fully qualified classname of Hadoop InputFormat
| (e.g. "org.apache.hadoop.mapreduce.lib.input.TextInputFormat")
| keyClass : str
| fully qualified classname of key Writable class (e.g. "org.apache.hadoop.io.Text")
| valueClass : str
| fully qualified classname of value Writable class
| (e.g. "org.apache.hadoop.io.LongWritable")
| keyConverter : str, optional
| fully qualified name of a function returning key WritableConverter
| valueConverter : str, optional
| fully qualified name of a function returning value WritableConverter
| conf : dict, optional
| Hadoop configuration, passed in as a dict
| batchSize : int, optional, default 0
| The number of Python objects represented as a single
| Java object. (default 0, choose batchSize automatically)
|
| Returns
| -------
| :class:`RDD`
| RDD of tuples of key and corresponding value
|
| See Also
| --------
| :meth:`RDD.saveAsSequenceFile`
| :meth:`RDD.saveAsNewAPIHadoopFile`
| :meth:`RDD.saveAsHadoopFile`
| :meth:`SparkContext.newAPIHadoopFile`
| :meth:`SparkContext.hadoopRDD`
|
| Examples
| --------
| >>> import os
| >>> import tempfile
|
| Set the related classes
|
| >>> output_format_class = "org.apache.hadoop.mapred.TextOutputFormat"
| >>> input_format_class = "org.apache.hadoop.mapred.TextInputFormat"
| >>> key_class = "org.apache.hadoop.io.IntWritable"
| >>> value_class = "org.apache.hadoop.io.Text"
|
| >>> with tempfile.TemporaryDirectory() as d:
| ... path = os.path.join(d, "old_hadoop_file")
| ...
| ... # Write a temporary Hadoop file
| ... rdd = sc.parallelize([(1, ""), (1, "a"), (3, "x")])
| ... rdd.saveAsHadoopFile(path, output_format_class, key_class, value_class)
| ...
| ... loaded = sc.hadoopFile(path, input_format_class, key_class, value_class)
| ... collected = sorted(loaded.collect())
|
| >>> collected
| [(0, '1\t'), (0, '1\ta'), (0, '3\tx')]
|
| hadoopRDD(self, inputFormatClass: str, keyClass: str, valueClass: str, keyConverter: Optional[str] = None, valueConverter: Optional[str] = None, conf: Optional[Dict[str, str]] = None, batchSize: int = 0) -> pyspark.rdd.RDD[typing.Tuple[~T, ~U]]
| Read an 'old' Hadoop InputFormat with arbitrary key and value class, from an arbitrary
| Hadoop configuration, which is passed in as a Python dict.
| This will be converted into a Configuration in Java.
| The mechanism is the same as for meth:`SparkContext.sequenceFile`.
|
| .. versionadded:: 1.1.0
|
| Parameters
| ----------
| inputFormatClass : str
| fully qualified classname of Hadoop InputFormat
| (e.g. "org.apache.hadoop.mapreduce.lib.input.TextInputFormat")
| keyClass : str
| fully qualified classname of key Writable class (e.g. "org.apache.hadoop.io.Text")
| valueClass : str
| fully qualified classname of value Writable class
| (e.g. "org.apache.hadoop.io.LongWritable")
| keyConverter : str, optional
| fully qualified name of a function returning key WritableConverter
| valueConverter : str, optional
| fully qualified name of a function returning value WritableConverter
| conf : dict, optional
| Hadoop configuration, passed in as a dict
| batchSize : int, optional, default 0
| The number of Python objects represented as a single
| Java object. (default 0, choose batchSize automatically)
|
| Returns
| -------
| :class:`RDD`
| RDD of tuples of key and corresponding value
|
| See Also
| --------
| :meth:`RDD.saveAsNewAPIHadoopDataset`
| :meth:`RDD.saveAsHadoopDataset`
| :meth:`SparkContext.newAPIHadoopRDD`
| :meth:`SparkContext.hadoopFile`
|
| Examples
| --------
| >>> import os
| >>> import tempfile
|
| Set the related classes
|
| >>> output_format_class = "org.apache.hadoop.mapred.TextOutputFormat"
| >>> input_format_class = "org.apache.hadoop.mapred.TextInputFormat"
| >>> key_class = "org.apache.hadoop.io.IntWritable"
| >>> value_class = "org.apache.hadoop.io.Text"
|
| >>> with tempfile.TemporaryDirectory() as d:
| ... path = os.path.join(d, "old_hadoop_file")
| ...
| ... # Create the conf for writing
| ... write_conf = {
| ... "mapred.output.format.class": output_format_class,
| ... "mapreduce.job.output.key.class": key_class,
| ... "mapreduce.job.output.value.class": value_class,
| ... "mapreduce.output.fileoutputformat.outputdir": path,
| ... }
| ...
| ... # Write a temporary Hadoop file
| ... rdd = sc.parallelize([(1, ""), (1, "a"), (3, "x")])
| ... rdd.saveAsHadoopDataset(conf=write_conf)
| ...
| ... # Create the conf for reading
| ... read_conf = {"mapreduce.input.fileinputformat.inputdir": path}
| ...
| ... loaded = sc.hadoopRDD(input_format_class, key_class, value_class, conf=read_conf)
| ... collected = sorted(loaded.collect())
|
| >>> collected
| [(0, '1\t'), (0, '1\ta'), (0, '3\tx')]
|
| newAPIHadoopFile(self, path: str, inputFormatClass: str, keyClass: str, valueClass: str, keyConverter: Optional[str] = None, valueConverter: Optional[str] = None, conf: Optional[Dict[str, str]] = None, batchSize: int = 0) -> pyspark.rdd.RDD[typing.Tuple[~T, ~U]]
| Read a 'new API' Hadoop InputFormat with arbitrary key and value class from HDFS,
| a local file system (available on all nodes), or any Hadoop-supported file system URI.
| The mechanism is the same as for meth:`SparkContext.sequenceFile`.
|
| A Hadoop configuration can be passed in as a Python dict. This will be converted into a
| Configuration in Java
|
| .. versionadded:: 1.1.0
|
| Parameters
| ----------
| path : str
| path to Hadoop file
| inputFormatClass : str
| fully qualified classname of Hadoop InputFormat
| (e.g. "org.apache.hadoop.mapreduce.lib.input.TextInputFormat")
| keyClass : str
| fully qualified classname of key Writable class
| (e.g. "org.apache.hadoop.io.Text")
| valueClass : str
| fully qualified classname of value Writable class
| (e.g. "org.apache.hadoop.io.LongWritable")
| keyConverter : str, optional
| fully qualified name of a function returning key WritableConverter
| None by default
| valueConverter : str, optional
| fully qualified name of a function returning value WritableConverter
| None by default
| conf : dict, optional
| Hadoop configuration, passed in as a dict
| None by default
| batchSize : int, optional, default 0
| The number of Python objects represented as a single
| Java object. (default 0, choose batchSize automatically)
|
| Returns
| -------
| :class:`RDD`
| RDD of tuples of key and corresponding value
|
| See Also
| --------
| :meth:`RDD.saveAsSequenceFile`
| :meth:`RDD.saveAsNewAPIHadoopFile`
| :meth:`RDD.saveAsHadoopFile`
| :meth:`SparkContext.sequenceFile`
| :meth:`SparkContext.hadoopFile`
|
| Examples
| --------
| >>> import os
| >>> import tempfile
|
| Set the related classes
|
| >>> output_format_class = "org.apache.hadoop.mapreduce.lib.output.SequenceFileOutputFormat"
| >>> input_format_class = "org.apache.hadoop.mapreduce.lib.input.SequenceFileInputFormat"
| >>> key_class = "org.apache.hadoop.io.IntWritable"
| >>> value_class = "org.apache.hadoop.io.Text"
|
| >>> with tempfile.TemporaryDirectory() as d:
| ... path = os.path.join(d, "new_hadoop_file")
| ...
| ... # Write a temporary Hadoop file
| ... rdd = sc.parallelize([(1, ""), (1, "a"), (3, "x")])
| ... rdd.saveAsNewAPIHadoopFile(path, output_format_class, key_class, value_class)
| ...
| ... loaded = sc.newAPIHadoopFile(path, input_format_class, key_class, value_class)
| ... collected = sorted(loaded.collect())
|
| >>> collected
| [(1, ''), (1, 'a'), (3, 'x')]
|
| newAPIHadoopRDD(self, inputFormatClass: str, keyClass: str, valueClass: str, keyConverter: Optional[str] = None, valueConverter: Optional[str] = None, conf: Optional[Dict[str, str]] = None, batchSize: int = 0) -> pyspark.rdd.RDD[typing.Tuple[~T, ~U]]
| Read a 'new API' Hadoop InputFormat with arbitrary key and value class, from an arbitrary
| Hadoop configuration, which is passed in as a Python dict.
| This will be converted into a Configuration in Java.
| The mechanism is the same as for meth:`SparkContext.sequenceFile`.
|
| .. versionadded:: 1.1.0
|
| Parameters
| ----------
| inputFormatClass : str
| fully qualified classname of Hadoop InputFormat
| (e.g. "org.apache.hadoop.mapreduce.lib.input.TextInputFormat")
| keyClass : str
| fully qualified classname of key Writable class (e.g. "org.apache.hadoop.io.Text")
| valueClass : str
| fully qualified classname of value Writable class
| (e.g. "org.apache.hadoop.io.LongWritable")
| keyConverter : str, optional
| fully qualified name of a function returning key WritableConverter
| (None by default)
| valueConverter : str, optional
| fully qualified name of a function returning value WritableConverter
| (None by default)
| conf : dict, optional
| Hadoop configuration, passed in as a dict (None by default)
| batchSize : int, optional, default 0
| The number of Python objects represented as a single
| Java object. (default 0, choose batchSize automatically)
|
| Returns
| -------
| :class:`RDD`
| RDD of tuples of key and corresponding value
|
| See Also
| --------
| :meth:`RDD.saveAsNewAPIHadoopDataset`
| :meth:`RDD.saveAsHadoopDataset`
| :meth:`SparkContext.hadoopRDD`
| :meth:`SparkContext.hadoopFile`
|
| Examples
| --------
| >>> import os
| >>> import tempfile
|
| Set the related classes
|
| >>> output_format_class = "org.apache.hadoop.mapreduce.lib.output.SequenceFileOutputFormat"
| >>> input_format_class = "org.apache.hadoop.mapreduce.lib.input.SequenceFileInputFormat"
| >>> key_class = "org.apache.hadoop.io.IntWritable"
| >>> value_class = "org.apache.hadoop.io.Text"
|
| >>> with tempfile.TemporaryDirectory() as d:
| ... path = os.path.join(d, "new_hadoop_file")
| ...
| ... # Create the conf for writing
| ... write_conf = {
| ... "mapreduce.job.outputformat.class": (output_format_class),
| ... "mapreduce.job.output.key.class": key_class,
| ... "mapreduce.job.output.value.class": value_class,
| ... "mapreduce.output.fileoutputformat.outputdir": path,
| ... }
| ...
| ... # Write a temporary Hadoop file
| ... rdd = sc.parallelize([(1, ""), (1, "a"), (3, "x")])
| ... rdd.saveAsNewAPIHadoopDataset(conf=write_conf)
| ...
| ... # Create the conf for reading
| ... read_conf = {"mapreduce.input.fileinputformat.inputdir": path}
| ...
| ... loaded = sc.newAPIHadoopRDD(input_format_class,
| ... key_class, value_class, conf=read_conf)
| ... collected = sorted(loaded.collect())
|
| >>> collected
| [(1, ''), (1, 'a'), (3, 'x')]
|
| parallelize(self, c: Iterable[~T], numSlices: Optional[int] = None) -> pyspark.rdd.RDD[~T]
| Distribute a local Python collection to form an RDD. Using range
| is recommended if the input represents a range for performance.
|
| .. versionadded:: 0.7.0
|
| Parameters
| ----------
| c : :class:`collections.abc.Iterable`
| iterable collection to distribute
| numSlices : int, optional
| the number of partitions of the new RDD
|
| Returns
| -------
| :class:`RDD`
| RDD representing distributed collection.
|
| Examples
| --------
| >>> sc.parallelize([0, 2, 3, 4, 6], 5).glom().collect()
| [[0], [2], [3], [4], [6]]
| >>> sc.parallelize(range(0, 6, 2), 5).glom().collect()
| [[], [0], [], [2], [4]]
|
| Deal with a list of strings.
|
| >>> strings = ["a", "b", "c"]
| >>> sc.parallelize(strings, 2).glom().collect()
| [['a'], ['b', 'c']]
|
| pickleFile(self, name: str, minPartitions: Optional[int] = None) -> pyspark.rdd.RDD[typing.Any]
| Load an RDD previously saved using :meth:`RDD.saveAsPickleFile` method.
|
| .. versionadded:: 1.1.0
|
| Parameters
| ----------
| name : str
| directory to the input data files, the path can be comma separated
| paths as a list of inputs
| minPartitions : int, optional
| suggested minimum number of partitions for the resulting RDD
|
| Returns
| -------
| :class:`RDD`
| RDD representing unpickled data from the file(s).
|
| See Also
| --------
| :meth:`RDD.saveAsPickleFile`
|
| Examples
| --------
| >>> import os
| >>> import tempfile
| >>> with tempfile.TemporaryDirectory() as d:
| ... # Write a temporary pickled file
| ... path1 = os.path.join(d, "pickled1")
| ... sc.parallelize(range(10)).saveAsPickleFile(path1, 3)
| ...
| ... # Write another temporary pickled file
| ... path2 = os.path.join(d, "pickled2")
| ... sc.parallelize(range(-10, -5)).saveAsPickleFile(path2, 3)
| ...
| ... # Load picked file
| ... collected1 = sorted(sc.pickleFile(path1, 3).collect())
| ... collected2 = sorted(sc.pickleFile(path2, 4).collect())
| ...
| ... # Load two picked files together
| ... collected3 = sorted(sc.pickleFile('{},{}'.format(path1, path2), 5).collect())
|
| >>> collected1
| [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
| >>> collected2
| [-10, -9, -8, -7, -6]
| >>> collected3
| [-10, -9, -8, -7, -6, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
|
| range(self, start: int, end: Optional[int] = None, step: int = 1, numSlices: Optional[int] = None) -> pyspark.rdd.RDD[int]
| Create a new RDD of int containing elements from `start` to `end`
| (exclusive), increased by `step` every element. Can be called the same
| way as python's built-in range() function. If called with a single argument,
| the argument is interpreted as `end`, and `start` is set to 0.
|
| .. versionadded:: 1.5.0
|
| Parameters
| ----------
| start : int
| the start value
| end : int, optional
| the end value (exclusive)
| step : int, optional, default 1
| the incremental step
| numSlices : int, optional
| the number of partitions of the new RDD
|
| Returns
| -------
| :class:`RDD`
| An RDD of int
|
| See Also
| --------
| :meth:`pyspark.sql.SparkSession.range`
|
| Examples
| --------
| >>> sc.range(5).collect()
| [0, 1, 2, 3, 4]
| >>> sc.range(2, 4).collect()
| [2, 3]
| >>> sc.range(1, 7, 2).collect()
| [1, 3, 5]
|
| Generate RDD with a negative step
|
| >>> sc.range(5, 0, -1).collect()
| [5, 4, 3, 2, 1]
| >>> sc.range(0, 5, -1).collect()
| []
|
| Control the number of partitions
|
| >>> sc.range(5, numSlices=1).getNumPartitions()
| 1
| >>> sc.range(5, numSlices=10).getNumPartitions()
| 10
|
| removeJobTag(self, tag: str) -> None
| Remove a tag previously added to be assigned to all the jobs started by this thread.
| Noop if such a tag was not added earlier.
|
| .. versionadded:: 3.5.0
|
| Parameters
| ----------
| tag : str
| The tag to be removed. Cannot contain ',' (comma) character.
|
| See Also
| --------
| :meth:`SparkContext.addJobTag`
| :meth:`SparkContext.getJobTags`
| :meth:`SparkContext.clearJobTags`
| :meth:`SparkContext.cancelJobsWithTag`
| :meth:`SparkContext.setInterruptOnCancel`
|
| Examples
| --------
| >>> sc.addJobTag("job_to_cancel1")
| >>> sc.addJobTag("job_to_cancel2")
| >>> sc.getJobTags()
| {'job_to_cancel1', 'job_to_cancel2'}
| >>> sc.removeJobTag("job_to_cancel1")
| >>> sc.getJobTags()
| {'job_to_cancel2'}
| >>> sc.clearJobTags()
|
| runJob(self, rdd: pyspark.rdd.RDD[~T], partitionFunc: Callable[[Iterable[~T]], Iterable[~U]], partitions: Optional[Sequence[int]] = None, allowLocal: bool = False) -> List[~U]
| Executes the given partitionFunc on the specified set of partitions,
| returning the result as an array of elements.
|
| If 'partitions' is not specified, this will run over all partitions.
|
| .. versionadded:: 1.1.0
|
| Parameters
| ----------
| rdd : :class:`RDD`
| target RDD to run tasks on
| partitionFunc : function
| a function to run on each partition of the RDD
| partitions : list, optional
| set of partitions to run on; some jobs may not want to compute on all
| partitions of the target RDD, e.g. for operations like `first`
| allowLocal : bool, default False
| this parameter takes no effect
|
| Returns
| -------
| list
| results of specified partitions
|
| See Also
| --------
| :meth:`SparkContext.cancelAllJobs`
|
| Examples
| --------
| >>> myRDD = sc.parallelize(range(6), 3)
| >>> sc.runJob(myRDD, lambda part: [x * x for x in part])
| [0, 1, 4, 9, 16, 25]
|
| >>> myRDD = sc.parallelize(range(6), 3)
| >>> sc.runJob(myRDD, lambda part: [x * x for x in part], [0, 2], True)
| [0, 1, 16, 25]
|
| sequenceFile(self, path: str, keyClass: Optional[str] = None, valueClass: Optional[str] = None, keyConverter: Optional[str] = None, valueConverter: Optional[str] = None, minSplits: Optional[int] = None, batchSize: int = 0) -> pyspark.rdd.RDD[typing.Tuple[~T, ~U]]
| Read a Hadoop SequenceFile with arbitrary key and value Writable class from HDFS,
| a local file system (available on all nodes), or any Hadoop-supported file system URI.
| The mechanism is as follows:
|
| 1. A Java RDD is created from the SequenceFile or other InputFormat, and the key
| and value Writable classes
| 2. Serialization is attempted via Pickle pickling
| 3. If this fails, the fallback is to call 'toString' on each key and value
| 4. :class:`CPickleSerializer` is used to deserialize pickled objects on the Python side
|
| .. versionadded:: 1.3.0
|
| Parameters
| ----------
| path : str
| path to sequencefile
| keyClass: str, optional
| fully qualified classname of key Writable class (e.g. "org.apache.hadoop.io.Text")
| valueClass : str, optional
| fully qualified classname of value Writable class
| (e.g. "org.apache.hadoop.io.LongWritable")
| keyConverter : str, optional
| fully qualified name of a function returning key WritableConverter
| valueConverter : str, optional
| fully qualifiedname of a function returning value WritableConverter
| minSplits : int, optional
| minimum splits in dataset (default min(2, sc.defaultParallelism))
| batchSize : int, optional, default 0
| The number of Python objects represented as a single
| Java object. (default 0, choose batchSize automatically)
|
| Returns
| -------
| :class:`RDD`
| RDD of tuples of key and corresponding value
|
| See Also
| --------
| :meth:`RDD.saveAsSequenceFile`
| :meth:`RDD.saveAsNewAPIHadoopFile`
| :meth:`RDD.saveAsHadoopFile`
| :meth:`SparkContext.newAPIHadoopFile`
| :meth:`SparkContext.hadoopFile`
|
| Examples
| --------
| >>> import os
| >>> import tempfile
|
| Set the class of output format
|
| >>> output_format_class = "org.apache.hadoop.mapreduce.lib.output.SequenceFileOutputFormat"
|
| >>> with tempfile.TemporaryDirectory() as d:
| ... path = os.path.join(d, "hadoop_file")
| ...
| ... # Write a temporary Hadoop file
| ... rdd = sc.parallelize([(1, {3.0: "bb"}), (2, {1.0: "aa"}), (3, {2.0: "dd"})])
| ... rdd.saveAsNewAPIHadoopFile(path, output_format_class)
| ...
| ... collected = sorted(sc.sequenceFile(path).collect())
|
| >>> collected
| [(1, {3.0: 'bb'}), (2, {1.0: 'aa'}), (3, {2.0: 'dd'})]
|
| setCheckpointDir(self, dirName: str) -> None
| Set the directory under which RDDs are going to be checkpointed. The
| directory must be an HDFS path if running on a cluster.
|
| .. versionadded:: 0.7.0
|
| Parameters
| ----------
| dirName : str
| path to the directory where checkpoint files will be stored
| (must be HDFS path if running in cluster)
|
| See Also
| --------
| :meth:`SparkContext.getCheckpointDir`
| :meth:`RDD.checkpoint`
| :meth:`RDD.getCheckpointFile`
|
| setInterruptOnCancel(self, interruptOnCancel: bool) -> None
| Set the behavior of job cancellation from jobs started in this thread.
|
| .. versionadded:: 3.5.0
|
| Parameters
| ----------
| interruptOnCancel : bool
| If true, then job cancellation will result in ``Thread.interrupt()``
| being called on the job's executor threads. This is useful to help ensure that
| the tasks are actually stopped in a timely manner, but is off by default due to
| HDFS-1208, where HDFS may respond to ``Thread.interrupt()`` by marking nodes as dead.
|
| See Also
| --------
| :meth:`SparkContext.addJobTag`
| :meth:`SparkContext.removeJobTag`
| :meth:`SparkContext.cancelAllJobs`
| :meth:`SparkContext.cancelJobGroup`
| :meth:`SparkContext.cancelJobsWithTag`
|
| setJobDescription(self, value: str) -> None
| Set a human readable description of the current job.
|
| .. versionadded:: 2.3.0
|
| Parameters
| ----------
| value : str
| The job description to set.
|
| Notes
| -----
| If you run jobs in parallel, use :class:`pyspark.InheritableThread` for thread
| local inheritance.
|
| setJobGroup(self, groupId: str, description: str, interruptOnCancel: bool = False) -> None
| Assigns a group ID to all the jobs started by this thread until the group ID is set to a
| different value or cleared.
|
| Often, a unit of execution in an application consists of multiple Spark actions or jobs.
| Application programmers can use this method to group all those jobs together and give a
| group description. Once set, the Spark web UI will associate such jobs with this group.
|
| The application can use :meth:`SparkContext.cancelJobGroup` to cancel all
| running jobs in this group.
|
| .. versionadded:: 1.0.0
|
| Parameters
| ----------
| groupId : str
| The group ID to assign.
| description : str
| The description to set for the job group.
| interruptOnCancel : bool, optional, default False
| whether to interrupt jobs on job cancellation.
|
| Notes
| -----
| If interruptOnCancel is set to true for the job group, then job cancellation will result
| in Thread.interrupt() being called on the job's executor threads. This is useful to help
| ensure that the tasks are actually stopped in a timely manner, but is off by default due
| to HDFS-1208, where HDFS may respond to Thread.interrupt() by marking nodes as dead.
|
| If you run jobs in parallel, use :class:`pyspark.InheritableThread` for thread
| local inheritance.
|
| See Also
| --------
| :meth:`SparkContext.cancelJobGroup`
|
| Examples
| --------
| >>> import threading
| >>> from time import sleep
| >>> from pyspark import InheritableThread
| >>> result = "Not Set"
| >>> lock = threading.Lock()
| >>> def map_func(x):
| ... sleep(100)
| ... raise RuntimeError("Task should have been cancelled")
| ...
| >>> def start_job(x):
| ... global result
| ... try:
| ... sc.setJobGroup("job_to_cancel", "some description")
| ... result = sc.parallelize(range(x)).map(map_func).collect()
| ... except Exception as e:
| ... result = "Cancelled"
| ... lock.release()
| ...
| >>> def stop_job():
| ... sleep(5)
| ... sc.cancelJobGroup("job_to_cancel")
| ...
| >>> suppress = lock.acquire()
| >>> suppress = InheritableThread(target=start_job, args=(10,)).start()
| >>> suppress = InheritableThread(target=stop_job).start()
| >>> suppress = lock.acquire()
| >>> print(result)
| Cancelled
|
| setLocalProperty(self, key: str, value: str) -> None
| Set a local property that affects jobs submitted from this thread, such as the
| Spark fair scheduler pool.
|
| .. versionadded:: 1.0.0
|
| Parameters
| ----------
| key : str
| The key of the local property to set.
| value : str
| The value of the local property to set.
|
| See Also
| --------
| :meth:`SparkContext.getLocalProperty`
|
| Notes
| -----
| If you run jobs in parallel, use :class:`pyspark.InheritableThread` for thread
| local inheritance.
|
| setLogLevel(self, logLevel: str) -> None
| Control our logLevel. This overrides any user-defined log settings.
| Valid log levels include: ALL, DEBUG, ERROR, FATAL, INFO, OFF, TRACE, WARN
|
| .. versionadded:: 1.4.0
|
| Parameters
| ----------
| logLevel : str
| The desired log level as a string.
|
| Examples
| --------
| >>> sc.setLogLevel("WARN") # doctest :+SKIP
|
| show_profiles(self) -> None
| Print the profile stats to stdout
|
| .. versionadded:: 1.2.0
|
| See Also
| --------
| :meth:`SparkContext.dump_profiles`
|
| sparkUser(self) -> str
| Get SPARK_USER for user who is running SparkContext.
|
| .. versionadded:: 1.0.0
|
| statusTracker(self) -> pyspark.status.StatusTracker
| Return :class:`StatusTracker` object
|
| .. versionadded:: 1.4.0
|
| stop(self) -> None
| Shut down the :class:`SparkContext`.
|
| .. versionadded:: 0.7.0
|
| textFile(self, name: str, minPartitions: Optional[int] = None, use_unicode: bool = True) -> pyspark.rdd.RDD[str]
| Read a text file from HDFS, a local file system (available on all
| nodes), or any Hadoop-supported file system URI, and return it as an
| RDD of Strings. The text files must be encoded as UTF-8.
|
| .. versionadded:: 0.7.0
|
| Parameters
| ----------
| name : str
| directory to the input data files, the path can be comma separated
| paths as a list of inputs
| minPartitions : int, optional
| suggested minimum number of partitions for the resulting RDD
| use_unicode : bool, default True
| If `use_unicode` is False, the strings will be kept as `str` (encoding
| as `utf-8`), which is faster and smaller than unicode.
|
| .. versionadded:: 1.2.0
|
| Returns
| -------
| :class:`RDD`
| RDD representing text data from the file(s).
|
| See Also
| --------
| :meth:`RDD.saveAsTextFile`
| :meth:`SparkContext.wholeTextFiles`
|
| Examples
| --------
| >>> import os
| >>> import tempfile
| >>> with tempfile.TemporaryDirectory() as d:
| ... path1 = os.path.join(d, "text1")
| ... path2 = os.path.join(d, "text2")
| ...
| ... # Write a temporary text file
| ... sc.parallelize(["x", "y", "z"]).saveAsTextFile(path1)
| ...
| ... # Write another temporary text file
| ... sc.parallelize(["aa", "bb", "cc"]).saveAsTextFile(path2)
| ...
| ... # Load text file
| ... collected1 = sorted(sc.textFile(path1, 3).collect())
| ... collected2 = sorted(sc.textFile(path2, 4).collect())
| ...
| ... # Load two text files together
| ... collected3 = sorted(sc.textFile('{},{}'.format(path1, path2), 5).collect())
|
| >>> collected1
| ['x', 'y', 'z']
| >>> collected2
| ['aa', 'bb', 'cc']
| >>> collected3
| ['aa', 'bb', 'cc', 'x', 'y', 'z']
|
| union(self, rdds: List[pyspark.rdd.RDD[~T]]) -> pyspark.rdd.RDD[~T]
| Build the union of a list of RDDs.
|
| This supports unions() of RDDs with different serialized formats,
| although this forces them to be reserialized using the default
| serializer:
|
| .. versionadded:: 0.7.0
|
| See Also
| --------
| :meth:`RDD.union`
|
| Examples
| --------
| >>> import os
| >>> import tempfile
| >>> with tempfile.TemporaryDirectory() as d:
| ... # generate a text RDD
| ... with open(os.path.join(d, "union-text.txt"), "w") as f:
| ... _ = f.write("Hello")
| ... text_rdd = sc.textFile(d)
| ...
| ... # generate another RDD
| ... parallelized = sc.parallelize(["World!"])
| ...
| ... unioned = sorted(sc.union([text_rdd, parallelized]).collect())
|
| >>> unioned
| ['Hello', 'World!']
|
| wholeTextFiles(self, path: str, minPartitions: Optional[int] = None, use_unicode: bool = True) -> pyspark.rdd.RDD[typing.Tuple[str, str]]
| Read a directory of text files from HDFS, a local file system
| (available on all nodes), or any Hadoop-supported file system
| URI. Each file is read as a single record and returned in a
| key-value pair, where the key is the path of each file, the
| value is the content of each file.
| The text files must be encoded as UTF-8.
|
| .. versionadded:: 1.0.0
|
| For example, if you have the following files:
|
| .. code-block:: text
|
| hdfs://a-hdfs-path/part-00000
| hdfs://a-hdfs-path/part-00001
| ...
| hdfs://a-hdfs-path/part-nnnnn
|
| Do ``rdd = sparkContext.wholeTextFiles("hdfs://a-hdfs-path")``,
| then ``rdd`` contains:
|
| .. code-block:: text
|
| (a-hdfs-path/part-00000, its content)
| (a-hdfs-path/part-00001, its content)
| ...
| (a-hdfs-path/part-nnnnn, its content)
|
| Parameters
| ----------
| path : str
| directory to the input data files, the path can be comma separated
| paths as a list of inputs
| minPartitions : int, optional
| suggested minimum number of partitions for the resulting RDD
| use_unicode : bool, default True
| If `use_unicode` is False, the strings will be kept as `str` (encoding
| as `utf-8`), which is faster and smaller than unicode.
|
| .. versionadded:: 1.2.0
|
| Returns
| -------
| :class:`RDD`
| RDD representing path-content pairs from the file(s).
|
| Notes
| -----
| Small files are preferred, as each file will be loaded fully in memory.
|
| See Also
| --------
| :meth:`RDD.saveAsTextFile`
| :meth:`SparkContext.textFile`
|
| Examples
| --------
| >>> import os
| >>> import tempfile
| >>> with tempfile.TemporaryDirectory() as d:
| ... # Write a temporary text file
| ... with open(os.path.join(d, "1.txt"), "w") as f:
| ... _ = f.write("123")
| ...
| ... # Write another temporary text file
| ... with open(os.path.join(d, "2.txt"), "w") as f:
| ... _ = f.write("xyz")
| ...
| ... collected = sorted(sc.wholeTextFiles(d).collect())
| >>> collected
| [('.../1.txt', '123'), ('.../2.txt', 'xyz')]
|
| ----------------------------------------------------------------------
| Class methods defined here:
|
| getOrCreate(conf: Optional[pyspark.conf.SparkConf] = None) -> 'SparkContext'
| Get or instantiate a :class:`SparkContext` and register it as a singleton object.
|
| .. versionadded:: 1.4.0
|
| Parameters
| ----------
| conf : :class:`SparkConf`, optional
| :class:`SparkConf` that will be used for initialization of the :class:`SparkContext`.
|
| Returns
| -------
| :class:`SparkContext`
| current :class:`SparkContext`, or a new one if it wasn't created before the function
| call.
|
| Examples
| --------
| >>> SparkContext.getOrCreate()
| <SparkContext ...>
|
| setSystemProperty(key: str, value: str) -> None
| Set a Java system property, such as `spark.executor.memory`. This must
| be invoked before instantiating :class:`SparkContext`.
|
| .. versionadded:: 0.9.0
|
| Parameters
| ----------
| key : str
| The key of a new Java system property.
| value : str
| The value of a new Java system property.
|
| ----------------------------------------------------------------------
| Readonly properties defined here:
|
| applicationId
| A unique identifier for the Spark application.
| Its format depends on the scheduler implementation.
|
| * in case of local spark app something like 'local-1433865536131'
| * in case of YARN something like 'application_1433865536131_34483'
|
| .. versionadded:: 1.5.0
|
| Examples
| --------
| >>> sc.applicationId # doctest: +ELLIPSIS
| 'local-...'
|
| defaultMinPartitions
| Default min number of partitions for Hadoop RDDs when not given by user
|
| .. versionadded:: 1.1.0
|
| Examples
| --------
| >>> sc.defaultMinPartitions > 0
| True
|
| defaultParallelism
| Default level of parallelism to use when not given by user (e.g. for reduce tasks)
|
| .. versionadded:: 0.7.0
|
| Examples
| --------
| >>> sc.defaultParallelism > 0
| True
|
| listArchives
| Returns a list of archive paths that are added to resources.
|
| .. versionadded:: 3.4.0
|
| See Also
| --------
| :meth:`SparkContext.addArchive`
|
| listFiles
| Returns a list of file paths that are added to resources.
|
| .. versionadded:: 3.4.0
|
| See Also
| --------
| :meth:`SparkContext.addFile`
|
| resources
| Return the resource information of this :class:`SparkContext`.
| A resource could be a GPU, FPGA, etc.
|
| .. versionadded:: 3.0.0
|
| startTime
| Return the epoch time when the :class:`SparkContext` was started.
|
| .. versionadded:: 1.5.0
|
| Examples
| --------
| >>> _ = sc.startTime
|
| uiWebUrl
| Return the URL of the SparkUI instance started by this :class:`SparkContext`
|
| .. versionadded:: 2.1.0
|
| Notes
| -----
| When the web ui is disabled, e.g., by ``spark.ui.enabled`` set to ``False``,
| it returns ``None``.
|
| Examples
| --------
| >>> sc.uiWebUrl
| 'http://...'
|
| version
| The version of Spark on which this application is running.
|
| .. versionadded:: 1.1.0
|
| Examples
| --------
| >>> _ = sc.version
|
| ----------------------------------------------------------------------
| Data descriptors defined here:
|
| __dict__
| dictionary for instance variables
|
| __weakref__
| list of weak references to the object
|
| ----------------------------------------------------------------------
| Data and other attributes defined here:
|
| PACKAGE_EXTENSIONS = ('.zip', '.egg', '.jar')
|
| __annotations__ = {'PACKAGE_EXTENSIONS': typing.Iterable[str], '_activ...
# Después de leer la ayuda hemos decidido que queremos usar sc.version para ver qué versión de Spark estamos ejecutando
sc.version
'3.5.6'
# Help can be used on any Python object
help(map)
Help on class map in module builtins:
class map(object)
| map(func, *iterables) --> map object
|
| Make an iterator that computes the function using arguments from
| each of the iterables. Stops when the shortest iterable is exhausted.
|
| Methods defined here:
|
| __getattribute__(self, name, /)
| Return getattr(self, name).
|
| __iter__(self, /)
| Implement iter(self).
|
| __next__(self, /)
| Implement next(self).
|
| __reduce__(...)
| Return state information for pickling.
|
| ----------------------------------------------------------------------
| Static methods defined here:
|
| __new__(*args, **kwargs)
| Create and return a new object. See help(type) for accurate signature.
Parte 3: Uso de RDDs y encadenamiento de transformaciones y acciones#
Trabajando con tu primer RDD#
En Spark, primero creamos un Conjunto de Datos Distribuidos Resilientes (RDD) base. Luego, podemos aplicar una o más transformaciones a ese RDD base. Un RDD es inmutable, por lo que una vez creado, no se puede cambiar. Como resultado, cada transformación crea un nuevo RDD. Finalmente, podemos aplicar una o más acciones a los RDDs. Nota que Spark utiliza la evaluación perezosa, por lo que las transformaciones no se ejecutan realmente hasta que ocurre una acción.#
Realizaremos varios ejercicios para obtener una mejor comprensión de los RDDs:#
Crear una colección de Python de 10,000 enteros
Crear un RDD base de Spark a partir de esa colección
Restar uno de cada valor usando
mapRealizar la acción
collectpara ver los resultadosRealizar la acción
countpara ver los conteosAplicar la transformación
filtery ver los resultados concollectAprender sobre funciones lambda
Explorar cómo funciona la evaluación perezosa y los desafíos de depuración que introduce
(3a) Crear una colección de enteros en Python en el rango de 1 a 10000#
Usaremos la función xrange() para crear una lista de enteros. xrange() solo genera valores a medida que se necesitan. Esto es diferente del comportamiento de range(), que genera la lista completa al ejecutarse. Debido a esto, xrange() es más eficiente en memoria que range(), especialmente para rangos grandes.#
data = range(1, 10001)
print(data)
range(1, 10001)
# Los datos son una lista normal de Python
# Obtener el primer elemento de los datos
data[9999]
10000
# Podemos comprobar el tamaño de la lista utilizando la función len()
len(data)
10000
(3b) Datos distribuidos y uso de una colección para crear un RDD#
En Spark, los conjuntos de datos se representan como una lista de entradas, donde la lista se divide en muchas particiones diferentes que se almacenan en diferentes máquinas. Cada partición contiene un subconjunto único de las entradas en la lista. Spark llama a los conjuntos de datos que almacena «Conjuntos de Datos Distribuidos Resilientes» (RDDs).#
Una de las características definitorias de Spark, en comparación con otros marcos de análisis de datos (por ejemplo, Hadoop), es que almacena datos en memoria en lugar de en disco. Esto permite que las aplicaciones de Spark se ejecuten mucho más rápido, ya que no se ven ralentizadas por la necesidad de leer datos del disco.#
La figura a continuación ilustra cómo Spark divide una lista de entradas de datos en particiones que se almacenan en memoria en un trabajador.#
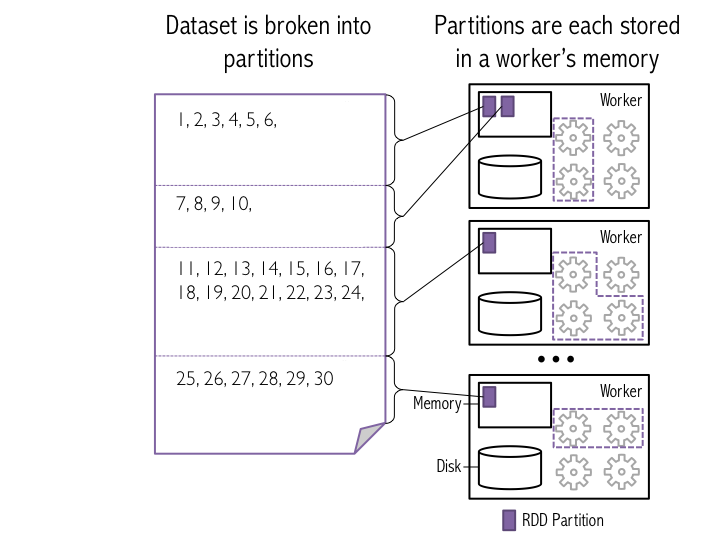
Para crear el RDD, usamos sc.parallelize(), que le dice a Spark que cree un nuevo conjunto de datos de entrada basado en los datos que se pasan. En este ejemplo, proporcionaremos un xrange. El segundo argumento del método sc.parallelize() le dice a Spark en cuántas particiones dividir los datos cuando los almacena en memoria (hablaremos más sobre esto más adelante en este tutorial). Ten en cuenta que para un mejor rendimiento al usar parallelize, se recomienda xrange() si la entrada representa un rango. Esta es la razón por la cual usamos xrange() en 3a.#
Hay muchos tipos diferentes de RDDs. La clase base para los RDDs es pyspark.RDD y otros RDDs heredan de pyspark.RDD. Dado que los otros tipos de RDD heredan de pyspark.RDD, tienen las mismas API y son funcionalmente idénticos. Veremos que sc.parallelize() genera un pyspark.rdd.PipelinedRDD cuando su entrada es un xrange, y un pyspark.RDD cuando su entrada es un range.#
Después de generar RDDs, podemos verlos en la pestaña «Storage» de la interfaz web. Notarás que los nuevos conjuntos de datos no se enumeran hasta que Spark necesita devolver un resultado debido a la ejecución de una acción. Esta característica de Spark se llama «evaluación perezosa». Esto permite que Spark evite realizar cálculos innecesarios.#
# Paraleliza los datos usando 8 particiones
# Esta operación es una transformación de datos en un RDD
# Spark utiliza la evaluación perezosa, por lo que no se ejecutan trabajos Spark en este punto
xrangeRDD = sc.parallelize(data, 8)
# Veamos la ayuda sobre paralelizar
help(sc.parallelize)
Help on method parallelize in module pyspark.context:
parallelize(c: Iterable[~T], numSlices: Optional[int] = None) -> pyspark.rdd.RDD[~T] method of pyspark.context.SparkContext instance
Distribute a local Python collection to form an RDD. Using range
is recommended if the input represents a range for performance.
.. versionadded:: 0.7.0
Parameters
----------
c : :class:`collections.abc.Iterable`
iterable collection to distribute
numSlices : int, optional
the number of partitions of the new RDD
Returns
-------
:class:`RDD`
RDD representing distributed collection.
Examples
--------
>>> sc.parallelize([0, 2, 3, 4, 6], 5).glom().collect()
[[0], [2], [3], [4], [6]]
>>> sc.parallelize(range(0, 6, 2), 5).glom().collect()
[[], [0], [], [2], [4]]
Deal with a list of strings.
>>> strings = ["a", "b", "c"]
>>> sc.parallelize(strings, 2).glom().collect()
[['a'], ['b', 'c']]
# Veamos qué tipo devuelve sc.parallelize()
print('type of xrangeRDD: {0}'.format(type(xrangeRDD)))
# ¿Y si usamos un rango
dataRange = range(1, 10001)
rangeRDD = sc.parallelize(dataRange, 8)
print('type of dataRangeRDD: {0}'.format(type(rangeRDD)))
type of xrangeRDD: <class 'pyspark.rdd.PipelinedRDD'>
type of dataRangeRDD: <class 'pyspark.rdd.PipelinedRDD'>
# Cada RDD recibe un ID único
print('xrangeRDD id: {0}'.format(xrangeRDD.id()))
print('rangeRDD id: {0}'.format(rangeRDD.id()))
xrangeRDD id: 2
rangeRDD id: 3
# Podemos nombrar cada RDD recién creado usando el método setName()
xrangeRDD.setName('My first RDD')
My first RDD PythonRDD[2] at RDD at PythonRDD.scala:53
# Veamos el linaje (el conjunto de transformaciones) del RDD usando toDebugString()
print(xrangeRDD.toDebugString())
b'(8) My first RDD PythonRDD[2] at RDD at PythonRDD.scala:53 []\n | ParallelCollectionRDD[0] at readRDDFromFile at PythonRDD.scala:289 []'
# Usemos help para ver que métodos podemos llamar en este RDD
help(xrangeRDD)
Help on PipelinedRDD in module pyspark.rdd object:
class PipelinedRDD(RDD, typing.Generic)
| PipelinedRDD(prev: pyspark.rdd.RDD[~T], func: Callable[[int, Iterable[~T]], Iterable[~U]], preservesPartitioning: bool = False, isFromBarrier: bool = False)
|
| Examples
| --------
| Pipelined maps:
|
| >>> rdd = sc.parallelize([1, 2, 3, 4])
| >>> rdd.map(lambda x: 2 * x).cache().map(lambda x: 2 * x).collect()
| [4, 8, 12, 16]
| >>> rdd.map(lambda x: 2 * x).map(lambda x: 2 * x).collect()
| [4, 8, 12, 16]
|
| Pipelined reduces:
|
| >>> from operator import add
| >>> rdd.map(lambda x: 2 * x).reduce(add)
| 20
| >>> rdd.flatMap(lambda x: [x, x]).reduce(add)
| 20
|
| Method resolution order:
| PipelinedRDD
| RDD
| typing.Generic
| builtins.object
|
| Methods defined here:
|
| __init__(self, prev: pyspark.rdd.RDD[~T], func: Callable[[int, Iterable[~T]], Iterable[~U]], preservesPartitioning: bool = False, isFromBarrier: bool = False)
| Initialize self. See help(type(self)) for accurate signature.
|
| getNumPartitions(self) -> int
| Returns the number of partitions in RDD
|
| .. versionadded:: 1.1.0
|
| Returns
| -------
| int
| number of partitions
|
| Examples
| --------
| >>> rdd = sc.parallelize([1, 2, 3, 4], 2)
| >>> rdd.getNumPartitions()
| 2
|
| id(self) -> int
| A unique ID for this RDD (within its SparkContext).
|
| .. versionadded:: 0.7.0
|
| Returns
| -------
| int
| The unique ID for this :class:`RDD`
|
| Examples
| --------
| >>> rdd = sc.range(5)
| >>> rdd.id() # doctest: +SKIP
| 3
|
| ----------------------------------------------------------------------
| Data and other attributes defined here:
|
| __annotations__ = {}
|
| __orig_bases__ = (pyspark.rdd.RDD[~U], typing.Generic[~T, ~U])
|
| __parameters__ = (~T, ~U)
|
| ----------------------------------------------------------------------
| Methods inherited from RDD:
|
| __add__(self: 'RDD[T]', other: 'RDD[U]') -> 'RDD[Union[T, U]]'
| Return the union of this RDD and another one.
|
| Examples
| --------
| >>> rdd = sc.parallelize([1, 1, 2, 3])
| >>> (rdd + rdd).collect()
| [1, 1, 2, 3, 1, 1, 2, 3]
|
| __getnewargs__(self) -> NoReturn
|
| __repr__(self) -> str
| Return repr(self).
|
| aggregate(self: 'RDD[T]', zeroValue: ~U, seqOp: Callable[[~U, ~T], ~U], combOp: Callable[[~U, ~U], ~U]) -> ~U
| Aggregate the elements of each partition, and then the results for all
| the partitions, using a given combine functions and a neutral "zero
| value."
|
| The functions ``op(t1, t2)`` is allowed to modify ``t1`` and return it
| as its result value to avoid object allocation; however, it should not
| modify ``t2``.
|
| The first function (seqOp) can return a different result type, U, than
| the type of this RDD. Thus, we need one operation for merging a T into
| an U and one operation for merging two U
|
| .. versionadded:: 1.1.0
|
| Parameters
| ----------
| zeroValue : U
| the initial value for the accumulated result of each partition
| seqOp : function
| a function used to accumulate results within a partition
| combOp : function
| an associative function used to combine results from different partitions
|
| Returns
| -------
| U
| the aggregated result
|
| See Also
| --------
| :meth:`RDD.reduce`
| :meth:`RDD.fold`
|
| Examples
| --------
| >>> seqOp = (lambda x, y: (x[0] + y, x[1] + 1))
| >>> combOp = (lambda x, y: (x[0] + y[0], x[1] + y[1]))
| >>> sc.parallelize([1, 2, 3, 4]).aggregate((0, 0), seqOp, combOp)
| (10, 4)
| >>> sc.parallelize([]).aggregate((0, 0), seqOp, combOp)
| (0, 0)
|
| aggregateByKey(self: 'RDD[Tuple[K, V]]', zeroValue: ~U, seqFunc: Callable[[~U, ~V], ~U], combFunc: Callable[[~U, ~U], ~U], numPartitions: Optional[int] = None, partitionFunc: Callable[[~K], int] = <function portable_hash at 0x7d0ad45511c0>) -> 'RDD[Tuple[K, U]]'
| Aggregate the values of each key, using given combine functions and a neutral
| "zero value". This function can return a different result type, U, than the type
| of the values in this RDD, V. Thus, we need one operation for merging a V into
| a U and one operation for merging two U's, The former operation is used for merging
| values within a partition, and the latter is used for merging values between
| partitions. To avoid memory allocation, both of these functions are
| allowed to modify and return their first argument instead of creating a new U.
|
| .. versionadded:: 1.1.0
|
| Parameters
| ----------
| zeroValue : U
| the initial value for the accumulated result of each partition
| seqFunc : function
| a function to merge a V into a U
| combFunc : function
| a function to combine two U's into a single one
| numPartitions : int, optional
| the number of partitions in new :class:`RDD`
| partitionFunc : function, optional, default `portable_hash`
| function to compute the partition index
|
| Returns
| -------
| :class:`RDD`
| a :class:`RDD` containing the keys and the aggregated result for each key
|
| See Also
| --------
| :meth:`RDD.reduceByKey`
| :meth:`RDD.combineByKey`
| :meth:`RDD.foldByKey`
| :meth:`RDD.groupByKey`
|
| Examples
| --------
| >>> rdd = sc.parallelize([("a", 1), ("b", 1), ("a", 2)])
| >>> seqFunc = (lambda x, y: (x[0] + y, x[1] + 1))
| >>> combFunc = (lambda x, y: (x[0] + y[0], x[1] + y[1]))
| >>> sorted(rdd.aggregateByKey((0, 0), seqFunc, combFunc).collect())
| [('a', (3, 2)), ('b', (1, 1))]
|
| barrier(self: 'RDD[T]') -> 'RDDBarrier[T]'
| Marks the current stage as a barrier stage, where Spark must launch all tasks together.
| In case of a task failure, instead of only restarting the failed task, Spark will abort the
| entire stage and relaunch all tasks for this stage.
| The barrier execution mode feature is experimental and it only handles limited scenarios.
| Please read the linked SPIP and design docs to understand the limitations and future plans.
|
| .. versionadded:: 2.4.0
|
| Returns
| -------
| :class:`RDDBarrier`
| instance that provides actions within a barrier stage.
|
| See Also
| --------
| :class:`pyspark.BarrierTaskContext`
|
| Notes
| -----
| For additional information see
|
| - `SPIP: Barrier Execution Mode <https://issues.apache.org/jira/browse/SPARK-24374>`_
| - `Design Doc <https://issues.apache.org/jira/browse/SPARK-24582>`_
|
| This API is experimental
|
| cache(self: 'RDD[T]') -> 'RDD[T]'
| Persist this RDD with the default storage level (`MEMORY_ONLY`).
|
| .. versionadded:: 0.7.0
|
| Returns
| -------
| :class:`RDD`
| The same :class:`RDD` with storage level set to `MEMORY_ONLY`
|
| See Also
| --------
| :meth:`RDD.persist`
| :meth:`RDD.unpersist`
| :meth:`RDD.getStorageLevel`
|
| Examples
| --------
| >>> rdd = sc.range(5)
| >>> rdd2 = rdd.cache()
| >>> rdd2 is rdd
| True
| >>> str(rdd.getStorageLevel())
| 'Memory Serialized 1x Replicated'
| >>> _ = rdd.unpersist()
|
| cartesian(self: 'RDD[T]', other: 'RDD[U]') -> 'RDD[Tuple[T, U]]'
| Return the Cartesian product of this RDD and another one, that is, the
| RDD of all pairs of elements ``(a, b)`` where ``a`` is in `self` and
| ``b`` is in `other`.
|
| .. versionadded:: 0.7.0
|
| Parameters
| ----------
| other : :class:`RDD`
| another :class:`RDD`
|
| Returns
| -------
| :class:`RDD`
| the Cartesian product of this :class:`RDD` and another one
|
| See Also
| --------
| :meth:`pyspark.sql.DataFrame.crossJoin`
|
| Examples
| --------
| >>> rdd = sc.parallelize([1, 2])
| >>> sorted(rdd.cartesian(rdd).collect())
| [(1, 1), (1, 2), (2, 1), (2, 2)]
|
| checkpoint(self) -> None
| Mark this RDD for checkpointing. It will be saved to a file inside the
| checkpoint directory set with :meth:`SparkContext.setCheckpointDir` and
| all references to its parent RDDs will be removed. This function must
| be called before any job has been executed on this RDD. It is strongly
| recommended that this RDD is persisted in memory, otherwise saving it
| on a file will require recomputation.
|
| .. versionadded:: 0.7.0
|
| See Also
| --------
| :meth:`RDD.isCheckpointed`
| :meth:`RDD.getCheckpointFile`
| :meth:`RDD.localCheckpoint`
| :meth:`SparkContext.setCheckpointDir`
| :meth:`SparkContext.getCheckpointDir`
|
| Examples
| --------
| >>> rdd = sc.range(5)
| >>> rdd.is_checkpointed
| False
| >>> rdd.getCheckpointFile() == None
| True
|
| >>> rdd.checkpoint()
| >>> rdd.is_checkpointed
| True
| >>> rdd.getCheckpointFile() == None
| True
|
| >>> rdd.count()
| 5
| >>> rdd.is_checkpointed
| True
| >>> rdd.getCheckpointFile() == None
| False
|
| cleanShuffleDependencies(self, blocking: bool = False) -> None
| Removes an RDD's shuffles and it's non-persisted ancestors.
|
| When running without a shuffle service, cleaning up shuffle files enables downscaling.
| If you use the RDD after this call, you should checkpoint and materialize it first.
|
| .. versionadded:: 3.3.0
|
| Parameters
| ----------
| blocking : bool, optional, default False
| whether to block on shuffle cleanup tasks
|
| Notes
| -----
| This API is a developer API.
|
| coalesce(self: 'RDD[T]', numPartitions: int, shuffle: bool = False) -> 'RDD[T]'
| Return a new RDD that is reduced into `numPartitions` partitions.
|
| .. versionadded:: 1.0.0
|
| Parameters
| ----------
| numPartitions : int, optional
| the number of partitions in new :class:`RDD`
| shuffle : bool, optional, default False
| whether to add a shuffle step
|
| Returns
| -------
| :class:`RDD`
| a :class:`RDD` that is reduced into `numPartitions` partitions
|
| See Also
| --------
| :meth:`RDD.repartition`
|
| Examples
| --------
| >>> sc.parallelize([1, 2, 3, 4, 5], 3).glom().collect()
| [[1], [2, 3], [4, 5]]
| >>> sc.parallelize([1, 2, 3, 4, 5], 3).coalesce(1).glom().collect()
| [[1, 2, 3, 4, 5]]
|
| cogroup(self: 'RDD[Tuple[K, V]]', other: 'RDD[Tuple[K, U]]', numPartitions: Optional[int] = None) -> 'RDD[Tuple[K, Tuple[ResultIterable[V], ResultIterable[U]]]]'
| For each key k in `self` or `other`, return a resulting RDD that
| contains a tuple with the list of values for that key in `self` as
| well as `other`.
|
| .. versionadded:: 0.7.0
|
| Parameters
| ----------
| other : :class:`RDD`
| another :class:`RDD`
|
| Returns
| -------
| :class:`RDD`
| a :class:`RDD` containing the keys and cogrouped values
|
| See Also
| --------
| :meth:`RDD.groupWith`
| :meth:`RDD.join`
|
| Examples
| --------
| >>> rdd1 = sc.parallelize([("a", 1), ("b", 4)])
| >>> rdd2 = sc.parallelize([("a", 2)])
| >>> [(x, tuple(map(list, y))) for x, y in sorted(list(rdd1.cogroup(rdd2).collect()))]
| [('a', ([1], [2])), ('b', ([4], []))]
|
| collect(self: 'RDD[T]') -> List[~T]
| Return a list that contains all the elements in this RDD.
|
| .. versionadded:: 0.7.0
|
| Returns
| -------
| list
| a list containing all the elements
|
| Notes
| -----
| This method should only be used if the resulting array is expected
| to be small, as all the data is loaded into the driver's memory.
|
| See Also
| --------
| :meth:`RDD.toLocalIterator`
| :meth:`pyspark.sql.DataFrame.collect`
|
| Examples
| --------
| >>> sc.range(5).collect()
| [0, 1, 2, 3, 4]
| >>> sc.parallelize(["x", "y", "z"]).collect()
| ['x', 'y', 'z']
|
| collectAsMap(self: 'RDD[Tuple[K, V]]') -> Dict[~K, ~V]
| Return the key-value pairs in this RDD to the master as a dictionary.
|
| .. versionadded:: 0.7.0
|
| Returns
| -------
| :class:`dict`
| a dictionary of (key, value) pairs
|
| See Also
| --------
| :meth:`RDD.countByValue`
|
| Notes
| -----
| This method should only be used if the resulting data is expected
| to be small, as all the data is loaded into the driver's memory.
|
| Examples
| --------
| >>> m = sc.parallelize([(1, 2), (3, 4)]).collectAsMap()
| >>> m[1]
| 2
| >>> m[3]
| 4
|
| collectWithJobGroup(self: 'RDD[T]', groupId: str, description: str, interruptOnCancel: bool = False) -> 'List[T]'
| When collect rdd, use this method to specify job group.
|
| .. versionadded:: 3.0.0
|
| .. deprecated:: 3.1.0
| Use :class:`pyspark.InheritableThread` with the pinned thread mode enabled.
|
| Parameters
| ----------
| groupId : str
| The group ID to assign.
| description : str
| The description to set for the job group.
| interruptOnCancel : bool, optional, default False
| whether to interrupt jobs on job cancellation.
|
| Returns
| -------
| list
| a list containing all the elements
|
| See Also
| --------
| :meth:`RDD.collect`
| :meth:`SparkContext.setJobGroup`
|
| combineByKey(self: 'RDD[Tuple[K, V]]', createCombiner: Callable[[~V], ~U], mergeValue: Callable[[~U, ~V], ~U], mergeCombiners: Callable[[~U, ~U], ~U], numPartitions: Optional[int] = None, partitionFunc: Callable[[~K], int] = <function portable_hash at 0x7d0ad45511c0>) -> 'RDD[Tuple[K, U]]'
| Generic function to combine the elements for each key using a custom
| set of aggregation functions.
|
| Turns an RDD[(K, V)] into a result of type RDD[(K, C)], for a "combined
| type" C.
|
| To avoid memory allocation, both mergeValue and mergeCombiners are allowed to
| modify and return their first argument instead of creating a new C.
|
| In addition, users can control the partitioning of the output RDD.
|
| .. versionadded:: 0.7.0
|
| Parameters
| ----------
| createCombiner : function
| a function to turns a V into a C
| mergeValue : function
| a function to merge a V into a C
| mergeCombiners : function
| a function to combine two C's into a single one
| numPartitions : int, optional
| the number of partitions in new :class:`RDD`
| partitionFunc : function, optional, default `portable_hash`
| function to compute the partition index
|
| Returns
| -------
| :class:`RDD`
| a :class:`RDD` containing the keys and the aggregated result for each key
|
| See Also
| --------
| :meth:`RDD.reduceByKey`
| :meth:`RDD.aggregateByKey`
| :meth:`RDD.foldByKey`
| :meth:`RDD.groupByKey`
|
| Notes
| -----
| V and C can be different -- for example, one might group an RDD of type
| (Int, Int) into an RDD of type (Int, List[Int]).
|
| Examples
| --------
| >>> rdd = sc.parallelize([("a", 1), ("b", 1), ("a", 2)])
| >>> def to_list(a):
| ... return [a]
| ...
| >>> def append(a, b):
| ... a.append(b)
| ... return a
| ...
| >>> def extend(a, b):
| ... a.extend(b)
| ... return a
| ...
| >>> sorted(rdd.combineByKey(to_list, append, extend).collect())
| [('a', [1, 2]), ('b', [1])]
|
| count(self) -> int
| Return the number of elements in this RDD.
|
| .. versionadded:: 0.7.0
|
| Returns
| -------
| int
| the number of elements
|
| See Also
| --------
| :meth:`RDD.countApprox`
| :meth:`pyspark.sql.DataFrame.count`
|
| Examples
| --------
| >>> sc.parallelize([2, 3, 4]).count()
| 3
|
| countApprox(self, timeout: int, confidence: float = 0.95) -> int
| Approximate version of count() that returns a potentially incomplete
| result within a timeout, even if not all tasks have finished.
|
| .. versionadded:: 1.2.0
|
| Parameters
| ----------
| timeout : int
| maximum time to wait for the job, in milliseconds
| confidence : float
| the desired statistical confidence in the result
|
| Returns
| -------
| int
| a potentially incomplete result, with error bounds
|
| See Also
| --------
| :meth:`RDD.count`
|
| Examples
| --------
| >>> rdd = sc.parallelize(range(1000), 10)
| >>> rdd.countApprox(1000, 1.0)
| 1000
|
| countApproxDistinct(self: 'RDD[T]', relativeSD: float = 0.05) -> int
| Return approximate number of distinct elements in the RDD.
|
| .. versionadded:: 1.2.0
|
| Parameters
| ----------
| relativeSD : float, optional
| Relative accuracy. Smaller values create
| counters that require more space.
| It must be greater than 0.000017.
|
| Returns
| -------
| int
| approximate number of distinct elements
|
| See Also
| --------
| :meth:`RDD.distinct`
|
| Notes
| -----
| The algorithm used is based on streamlib's implementation of
| `"HyperLogLog in Practice: Algorithmic Engineering of a State
| of The Art Cardinality Estimation Algorithm", available here
| <https://doi.org/10.1145/2452376.2452456>`_.
|
| Examples
| --------
| >>> n = sc.parallelize(range(1000)).map(str).countApproxDistinct()
| >>> 900 < n < 1100
| True
| >>> n = sc.parallelize([i % 20 for i in range(1000)]).countApproxDistinct()
| >>> 16 < n < 24
| True
|
| countByKey(self: 'RDD[Tuple[K, V]]') -> Dict[~K, int]
| Count the number of elements for each key, and return the result to the
| master as a dictionary.
|
| .. versionadded:: 0.7.0
|
| Returns
| -------
| dict
| a dictionary of (key, count) pairs
|
| See Also
| --------
| :meth:`RDD.collectAsMap`
| :meth:`RDD.countByValue`
|
| Examples
| --------
| >>> rdd = sc.parallelize([("a", 1), ("b", 1), ("a", 1)])
| >>> sorted(rdd.countByKey().items())
| [('a', 2), ('b', 1)]
|
| countByValue(self: 'RDD[K]') -> Dict[~K, int]
| Return the count of each unique value in this RDD as a dictionary of
| (value, count) pairs.
|
| .. versionadded:: 0.7.0
|
| Returns
| -------
| dict
| a dictionary of (value, count) pairs
|
| See Also
| --------
| :meth:`RDD.collectAsMap`
| :meth:`RDD.countByKey`
|
| Examples
| --------
| >>> sorted(sc.parallelize([1, 2, 1, 2, 2], 2).countByValue().items())
| [(1, 2), (2, 3)]
|
| distinct(self: 'RDD[T]', numPartitions: Optional[int] = None) -> 'RDD[T]'
| Return a new RDD containing the distinct elements in this RDD.
|
| .. versionadded:: 0.7.0
|
| Parameters
| ----------
| numPartitions : int, optional
| the number of partitions in new :class:`RDD`
|
| Returns
| -------
| :class:`RDD`
| a new :class:`RDD` containing the distinct elements
|
| See Also
| --------
| :meth:`RDD.countApproxDistinct`
|
| Examples
| --------
| >>> sorted(sc.parallelize([1, 1, 2, 3]).distinct().collect())
| [1, 2, 3]
|
| filter(self: 'RDD[T]', f: Callable[[~T], bool]) -> 'RDD[T]'
| Return a new RDD containing only the elements that satisfy a predicate.
|
| .. versionadded:: 0.7.0
|
| Parameters
| ----------
| f : function
| a function to run on each element of the RDD
|
| Returns
| -------
| :class:`RDD`
| a new :class:`RDD` by applying a function to each element
|
| See Also
| --------
| :meth:`RDD.map`
|
| Examples
| --------
| >>> rdd = sc.parallelize([1, 2, 3, 4, 5])
| >>> rdd.filter(lambda x: x % 2 == 0).collect()
| [2, 4]
|
| first(self: 'RDD[T]') -> ~T
| Return the first element in this RDD.
|
| .. versionadded:: 0.7.0
|
| Returns
| -------
| T
| the first element
|
| See Also
| --------
| :meth:`RDD.take`
| :meth:`pyspark.sql.DataFrame.first`
| :meth:`pyspark.sql.DataFrame.head`
|
| Examples
| --------
| >>> sc.parallelize([2, 3, 4]).first()
| 2
| >>> sc.parallelize([]).first()
| Traceback (most recent call last):
| ...
| ValueError: RDD is empty
|
| flatMap(self: 'RDD[T]', f: Callable[[~T], Iterable[~U]], preservesPartitioning: bool = False) -> 'RDD[U]'
| Return a new RDD by first applying a function to all elements of this
| RDD, and then flattening the results.
|
| .. versionadded:: 0.7.0
|
| Parameters
| ----------
| f : function
| a function to turn a T into a sequence of U
| preservesPartitioning : bool, optional, default False
| indicates whether the input function preserves the partitioner,
| which should be False unless this is a pair RDD and the input
|
| Returns
| -------
| :class:`RDD`
| a new :class:`RDD` by applying a function to all elements
|
| See Also
| --------
| :meth:`RDD.map`
| :meth:`RDD.mapPartitions`
| :meth:`RDD.mapPartitionsWithIndex`
| :meth:`RDD.mapPartitionsWithSplit`
|
| Examples
| --------
| >>> rdd = sc.parallelize([2, 3, 4])
| >>> sorted(rdd.flatMap(lambda x: range(1, x)).collect())
| [1, 1, 1, 2, 2, 3]
| >>> sorted(rdd.flatMap(lambda x: [(x, x), (x, x)]).collect())
| [(2, 2), (2, 2), (3, 3), (3, 3), (4, 4), (4, 4)]
|
| flatMapValues(self: 'RDD[Tuple[K, V]]', f: Callable[[~V], Iterable[~U]]) -> 'RDD[Tuple[K, U]]'
| Pass each value in the key-value pair RDD through a flatMap function
| without changing the keys; this also retains the original RDD's
| partitioning.
|
| .. versionadded:: 0.7.0
|
| Parameters
| ----------
| f : function
| a function to turn a V into a sequence of U
|
| Returns
| -------
| :class:`RDD`
| a :class:`RDD` containing the keys and the flat-mapped value
|
| See Also
| --------
| :meth:`RDD.flatMap`
| :meth:`RDD.mapValues`
|
| Examples
| --------
| >>> rdd = sc.parallelize([("a", ["x", "y", "z"]), ("b", ["p", "r"])])
| >>> def f(x): return x
| ...
| >>> rdd.flatMapValues(f).collect()
| [('a', 'x'), ('a', 'y'), ('a', 'z'), ('b', 'p'), ('b', 'r')]
|
| fold(self: 'RDD[T]', zeroValue: ~T, op: Callable[[~T, ~T], ~T]) -> ~T
| Aggregate the elements of each partition, and then the results for all
| the partitions, using a given associative function and a neutral "zero value."
|
| The function ``op(t1, t2)`` is allowed to modify ``t1`` and return it
| as its result value to avoid object allocation; however, it should not
| modify ``t2``.
|
| This behaves somewhat differently from fold operations implemented
| for non-distributed collections in functional languages like Scala.
| This fold operation may be applied to partitions individually, and then
| fold those results into the final result, rather than apply the fold
| to each element sequentially in some defined ordering. For functions
| that are not commutative, the result may differ from that of a fold
| applied to a non-distributed collection.
|
| .. versionadded:: 0.7.0
|
| Parameters
| ----------
| zeroValue : T
| the initial value for the accumulated result of each partition
| op : function
| a function used to both accumulate results within a partition and combine
| results from different partitions
|
| Returns
| -------
| T
| the aggregated result
|
| See Also
| --------
| :meth:`RDD.reduce`
| :meth:`RDD.aggregate`
|
| Examples
| --------
| >>> from operator import add
| >>> sc.parallelize([1, 2, 3, 4, 5]).fold(0, add)
| 15
|
| foldByKey(self: 'RDD[Tuple[K, V]]', zeroValue: ~V, func: Callable[[~V, ~V], ~V], numPartitions: Optional[int] = None, partitionFunc: Callable[[~K], int] = <function portable_hash at 0x7d0ad45511c0>) -> 'RDD[Tuple[K, V]]'
| Merge the values for each key using an associative function "func"
| and a neutral "zeroValue" which may be added to the result an
| arbitrary number of times, and must not change the result
| (e.g., 0 for addition, or 1 for multiplication.).
|
| .. versionadded:: 1.1.0
|
| Parameters
| ----------
| zeroValue : V
| the initial value for the accumulated result of each partition
| func : function
| a function to combine two V's into a single one
| numPartitions : int, optional
| the number of partitions in new :class:`RDD`
| partitionFunc : function, optional, default `portable_hash`
| function to compute the partition index
|
| Returns
| -------
| :class:`RDD`
| a :class:`RDD` containing the keys and the aggregated result for each key
|
| See Also
| --------
| :meth:`RDD.reduceByKey`
| :meth:`RDD.combineByKey`
| :meth:`RDD.aggregateByKey`
| :meth:`RDD.groupByKey`
|
| Examples
| --------
| >>> rdd = sc.parallelize([("a", 1), ("b", 1), ("a", 1)])
| >>> from operator import add
| >>> sorted(rdd.foldByKey(0, add).collect())
| [('a', 2), ('b', 1)]
|
| foreach(self: 'RDD[T]', f: Callable[[~T], NoneType]) -> None
| Applies a function to all elements of this RDD.
|
| .. versionadded:: 0.7.0
|
| Parameters
| ----------
| f : function
| a function applied to each element
|
| See Also
| --------
| :meth:`RDD.foreachPartition`
| :meth:`pyspark.sql.DataFrame.foreach`
| :meth:`pyspark.sql.DataFrame.foreachPartition`
|
| Examples
| --------
| >>> def f(x): print(x)
| ...
| >>> sc.parallelize([1, 2, 3, 4, 5]).foreach(f)
|
| foreachPartition(self: 'RDD[T]', f: Callable[[Iterable[~T]], NoneType]) -> None
| Applies a function to each partition of this RDD.
|
| .. versionadded:: 1.0.0
|
| Parameters
| ----------
| f : function
| a function applied to each partition
|
| See Also
| --------
| :meth:`RDD.foreach`
| :meth:`pyspark.sql.DataFrame.foreach`
| :meth:`pyspark.sql.DataFrame.foreachPartition`
|
| Examples
| --------
| >>> def f(iterator):
| ... for x in iterator:
| ... print(x)
| ...
| >>> sc.parallelize([1, 2, 3, 4, 5]).foreachPartition(f)
|
| fullOuterJoin(self: 'RDD[Tuple[K, V]]', other: 'RDD[Tuple[K, U]]', numPartitions: Optional[int] = None) -> 'RDD[Tuple[K, Tuple[Optional[V], Optional[U]]]]'
| Perform a right outer join of `self` and `other`.
|
| For each element (k, v) in `self`, the resulting RDD will either
| contain all pairs (k, (v, w)) for w in `other`, or the pair
| (k, (v, None)) if no elements in `other` have key k.
|
| Similarly, for each element (k, w) in `other`, the resulting RDD will
| either contain all pairs (k, (v, w)) for v in `self`, or the pair
| (k, (None, w)) if no elements in `self` have key k.
|
| Hash-partitions the resulting RDD into the given number of partitions.
|
| .. versionadded:: 1.2.0
|
| Parameters
| ----------
| other : :class:`RDD`
| another :class:`RDD`
| numPartitions : int, optional
| the number of partitions in new :class:`RDD`
|
| Returns
| -------
| :class:`RDD`
| a :class:`RDD` containing all pairs of elements with matching keys
|
| See Also
| --------
| :meth:`RDD.join`
| :meth:`RDD.leftOuterJoin`
| :meth:`RDD.fullOuterJoin`
| :meth:`pyspark.sql.DataFrame.join`
|
| Examples
| --------
| >>> rdd1 = sc.parallelize([("a", 1), ("b", 4)])
| >>> rdd2 = sc.parallelize([("a", 2), ("c", 8)])
| >>> sorted(rdd1.fullOuterJoin(rdd2).collect())
| [('a', (1, 2)), ('b', (4, None)), ('c', (None, 8))]
|
| getCheckpointFile(self) -> Optional[str]
| Gets the name of the file to which this RDD was checkpointed
|
| Not defined if RDD is checkpointed locally.
|
| .. versionadded:: 0.7.0
|
| Returns
| -------
| str
| the name of the file to which this :class:`RDD` was checkpointed
|
| See Also
| --------
| :meth:`RDD.checkpoint`
| :meth:`SparkContext.setCheckpointDir`
| :meth:`SparkContext.getCheckpointDir`
|
| getResourceProfile(self) -> Optional[pyspark.resource.profile.ResourceProfile]
| Get the :class:`pyspark.resource.ResourceProfile` specified with this RDD or None
| if it wasn't specified.
|
| .. versionadded:: 3.1.0
|
| Returns
| -------
| class:`pyspark.resource.ResourceProfile`
| The user specified profile or None if none were specified
|
| See Also
| --------
| :meth:`RDD.withResources`
|
| Notes
| -----
| This API is experimental
|
| getStorageLevel(self) -> pyspark.storagelevel.StorageLevel
| Get the RDD's current storage level.
|
| .. versionadded:: 1.0.0
|
| Returns
| -------
| :class:`StorageLevel`
| current :class:`StorageLevel`
|
| See Also
| --------
| :meth:`RDD.name`
|
| Examples
| --------
| >>> rdd = sc.parallelize([1,2])
| >>> rdd.getStorageLevel()
| StorageLevel(False, False, False, False, 1)
| >>> print(rdd.getStorageLevel())
| Serialized 1x Replicated
|
| glom(self: 'RDD[T]') -> 'RDD[List[T]]'
| Return an RDD created by coalescing all elements within each partition
| into a list.
|
| .. versionadded:: 0.7.0
|
| Returns
| -------
| :class:`RDD`
| a new :class:`RDD` coalescing all elements within each partition into a list
|
| Examples
| --------
| >>> rdd = sc.parallelize([1, 2, 3, 4], 2)
| >>> sorted(rdd.glom().collect())
| [[1, 2], [3, 4]]
|
| groupBy(self: 'RDD[T]', f: Callable[[~T], ~K], numPartitions: Optional[int] = None, partitionFunc: Callable[[~K], int] = <function portable_hash at 0x7d0ad45511c0>) -> 'RDD[Tuple[K, Iterable[T]]]'
| Return an RDD of grouped items.
|
| .. versionadded:: 0.7.0
|
| Parameters
| ----------
| f : function
| a function to compute the key
| numPartitions : int, optional
| the number of partitions in new :class:`RDD`
| partitionFunc : function, optional, default `portable_hash`
| a function to compute the partition index
|
| Returns
| -------
| :class:`RDD`
| a new :class:`RDD` of grouped items
|
| See Also
| --------
| :meth:`RDD.groupByKey`
| :meth:`pyspark.sql.DataFrame.groupBy`
|
| Examples
| --------
| >>> rdd = sc.parallelize([1, 1, 2, 3, 5, 8])
| >>> result = rdd.groupBy(lambda x: x % 2).collect()
| >>> sorted([(x, sorted(y)) for (x, y) in result])
| [(0, [2, 8]), (1, [1, 1, 3, 5])]
|
| groupByKey(self: 'RDD[Tuple[K, V]]', numPartitions: Optional[int] = None, partitionFunc: Callable[[~K], int] = <function portable_hash at 0x7d0ad45511c0>) -> 'RDD[Tuple[K, Iterable[V]]]'
| Group the values for each key in the RDD into a single sequence.
| Hash-partitions the resulting RDD with numPartitions partitions.
|
| .. versionadded:: 0.7.0
|
| Parameters
| ----------
| numPartitions : int, optional
| the number of partitions in new :class:`RDD`
| partitionFunc : function, optional, default `portable_hash`
| function to compute the partition index
|
| Returns
| -------
| :class:`RDD`
| a :class:`RDD` containing the keys and the grouped result for each key
|
| See Also
| --------
| :meth:`RDD.reduceByKey`
| :meth:`RDD.combineByKey`
| :meth:`RDD.aggregateByKey`
| :meth:`RDD.foldByKey`
|
| Notes
| -----
| If you are grouping in order to perform an aggregation (such as a
| sum or average) over each key, using reduceByKey or aggregateByKey will
| provide much better performance.
|
| Examples
| --------
| >>> rdd = sc.parallelize([("a", 1), ("b", 1), ("a", 1)])
| >>> sorted(rdd.groupByKey().mapValues(len).collect())
| [('a', 2), ('b', 1)]
| >>> sorted(rdd.groupByKey().mapValues(list).collect())
| [('a', [1, 1]), ('b', [1])]
|
| groupWith(self: 'RDD[Tuple[Any, Any]]', other: 'RDD[Tuple[Any, Any]]', *others: 'RDD[Tuple[Any, Any]]') -> 'RDD[Tuple[Any, Tuple[ResultIterable[Any], ...]]]'
| Alias for cogroup but with support for multiple RDDs.
|
| .. versionadded:: 0.7.0
|
| Parameters
| ----------
| other : :class:`RDD`
| another :class:`RDD`
| others : :class:`RDD`
| other :class:`RDD`\s
|
| Returns
| -------
| :class:`RDD`
| a :class:`RDD` containing the keys and cogrouped values
|
| See Also
| --------
| :meth:`RDD.cogroup`
| :meth:`RDD.join`
|
| Examples
| --------
| >>> rdd1 = sc.parallelize([("a", 5), ("b", 6)])
| >>> rdd2 = sc.parallelize([("a", 1), ("b", 4)])
| >>> rdd3 = sc.parallelize([("a", 2)])
| >>> rdd4 = sc.parallelize([("b", 42)])
| >>> [(x, tuple(map(list, y))) for x, y in
| ... sorted(list(rdd1.groupWith(rdd2, rdd3, rdd4).collect()))]
| [('a', ([5], [1], [2], [])), ('b', ([6], [4], [], [42]))]
|
| histogram(self: 'RDD[S]', buckets: Union[int, List[ForwardRef('S')], Tuple[ForwardRef('S'), ...]]) -> Tuple[Sequence[ForwardRef('S')], List[int]]
| Compute a histogram using the provided buckets. The buckets
| are all open to the right except for the last which is closed.
| e.g. [1,10,20,50] means the buckets are [1,10) [10,20) [20,50],
| which means 1<=x<10, 10<=x<20, 20<=x<=50. And on the input of 1
| and 50 we would have a histogram of 1,0,1.
|
| If your histogram is evenly spaced (e.g. [0, 10, 20, 30]),
| this can be switched from an O(log n) insertion to O(1) per
| element (where n is the number of buckets).
|
| Buckets must be sorted, not contain any duplicates, and have
| at least two elements.
|
| If `buckets` is a number, it will generate buckets which are
| evenly spaced between the minimum and maximum of the RDD. For
| example, if the min value is 0 and the max is 100, given `buckets`
| as 2, the resulting buckets will be [0,50) [50,100]. `buckets` must
| be at least 1. An exception is raised if the RDD contains infinity.
| If the elements in the RDD do not vary (max == min), a single bucket
| will be used.
|
| .. versionadded:: 1.2.0
|
| Parameters
| ----------
| buckets : int, or list, or tuple
| if `buckets` is a number, it computes a histogram of the data using
| `buckets` number of buckets evenly, otherwise, `buckets` is the provided
| buckets to bin the data.
|
| Returns
| -------
| tuple
| a tuple of buckets and histogram
|
| See Also
| --------
| :meth:`RDD.stats`
|
| Examples
| --------
| >>> rdd = sc.parallelize(range(51))
| >>> rdd.histogram(2)
| ([0, 25, 50], [25, 26])
| >>> rdd.histogram([0, 5, 25, 50])
| ([0, 5, 25, 50], [5, 20, 26])
| >>> rdd.histogram([0, 15, 30, 45, 60]) # evenly spaced buckets
| ([0, 15, 30, 45, 60], [15, 15, 15, 6])
| >>> rdd = sc.parallelize(["ab", "ac", "b", "bd", "ef"])
| >>> rdd.histogram(("a", "b", "c"))
| (('a', 'b', 'c'), [2, 2])
|
| intersection(self: 'RDD[T]', other: 'RDD[T]') -> 'RDD[T]'
| Return the intersection of this RDD and another one. The output will
| not contain any duplicate elements, even if the input RDDs did.
|
| .. versionadded:: 1.0.0
|
| Parameters
| ----------
| other : :class:`RDD`
| another :class:`RDD`
|
| Returns
| -------
| :class:`RDD`
| the intersection of this :class:`RDD` and another one
|
| See Also
| --------
| :meth:`pyspark.sql.DataFrame.intersect`
|
| Notes
| -----
| This method performs a shuffle internally.
|
| Examples
| --------
| >>> rdd1 = sc.parallelize([1, 10, 2, 3, 4, 5])
| >>> rdd2 = sc.parallelize([1, 6, 2, 3, 7, 8])
| >>> rdd1.intersection(rdd2).collect()
| [1, 2, 3]
|
| isCheckpointed(self) -> bool
| Return whether this RDD is checkpointed and materialized, either reliably or locally.
|
| .. versionadded:: 0.7.0
|
| Returns
| -------
| bool
| whether this :class:`RDD` is checkpointed and materialized, either reliably or locally
|
| See Also
| --------
| :meth:`RDD.checkpoint`
| :meth:`RDD.getCheckpointFile`
| :meth:`SparkContext.setCheckpointDir`
| :meth:`SparkContext.getCheckpointDir`
|
| isEmpty(self) -> bool
| Returns true if and only if the RDD contains no elements at all.
|
| .. versionadded:: 1.3.0
|
| Returns
| -------
| bool
| whether the :class:`RDD` is empty
|
| See Also
| --------
| :meth:`RDD.first`
| :meth:`pyspark.sql.DataFrame.isEmpty`
|
| Notes
| -----
| An RDD may be empty even when it has at least 1 partition.
|
| Examples
| --------
| >>> sc.parallelize([]).isEmpty()
| True
| >>> sc.parallelize([1]).isEmpty()
| False
|
| isLocallyCheckpointed(self) -> bool
| Return whether this RDD is marked for local checkpointing.
|
| Exposed for testing.
|
| .. versionadded:: 2.2.0
|
| Returns
| -------
| bool
| whether this :class:`RDD` is marked for local checkpointing
|
| See Also
| --------
| :meth:`RDD.localCheckpoint`
|
| join(self: 'RDD[Tuple[K, V]]', other: 'RDD[Tuple[K, U]]', numPartitions: Optional[int] = None) -> 'RDD[Tuple[K, Tuple[V, U]]]'
| Return an RDD containing all pairs of elements with matching keys in
| `self` and `other`.
|
| Each pair of elements will be returned as a (k, (v1, v2)) tuple, where
| (k, v1) is in `self` and (k, v2) is in `other`.
|
| Performs a hash join across the cluster.
|
| .. versionadded:: 0.7.0
|
| Parameters
| ----------
| other : :class:`RDD`
| another :class:`RDD`
| numPartitions : int, optional
| the number of partitions in new :class:`RDD`
|
| Returns
| -------
| :class:`RDD`
| a :class:`RDD` containing all pairs of elements with matching keys
|
| See Also
| --------
| :meth:`RDD.leftOuterJoin`
| :meth:`RDD.rightOuterJoin`
| :meth:`RDD.fullOuterJoin`
| :meth:`RDD.cogroup`
| :meth:`RDD.groupWith`
| :meth:`pyspark.sql.DataFrame.join`
|
| Examples
| --------
| >>> rdd1 = sc.parallelize([("a", 1), ("b", 4)])
| >>> rdd2 = sc.parallelize([("a", 2), ("a", 3)])
| >>> sorted(rdd1.join(rdd2).collect())
| [('a', (1, 2)), ('a', (1, 3))]
|
| keyBy(self: 'RDD[T]', f: Callable[[~T], ~K]) -> 'RDD[Tuple[K, T]]'
| Creates tuples of the elements in this RDD by applying `f`.
|
| .. versionadded:: 0.9.1
|
| Parameters
| ----------
| f : function
| a function to compute the key
|
| Returns
| -------
| :class:`RDD`
| a :class:`RDD` with the elements from this that are not in `other`
|
| See Also
| --------
| :meth:`RDD.map`
| :meth:`RDD.keys`
| :meth:`RDD.values`
|
| Examples
| --------
| >>> rdd1 = sc.parallelize(range(0,3)).keyBy(lambda x: x*x)
| >>> rdd2 = sc.parallelize(zip(range(0,5), range(0,5)))
| >>> [(x, list(map(list, y))) for x, y in sorted(rdd1.cogroup(rdd2).collect())]
| [(0, [[0], [0]]), (1, [[1], [1]]), (2, [[], [2]]), (3, [[], [3]]), (4, [[2], [4]])]
|
| keys(self: 'RDD[Tuple[K, V]]') -> 'RDD[K]'
| Return an RDD with the keys of each tuple.
|
| .. versionadded:: 0.7.0
|
| Returns
| -------
| :class:`RDD`
| a :class:`RDD` only containing the keys
|
| See Also
| --------
| :meth:`RDD.values`
|
| Examples
| --------
| >>> rdd = sc.parallelize([(1, 2), (3, 4)]).keys()
| >>> rdd.collect()
| [1, 3]
|
| leftOuterJoin(self: 'RDD[Tuple[K, V]]', other: 'RDD[Tuple[K, U]]', numPartitions: Optional[int] = None) -> 'RDD[Tuple[K, Tuple[V, Optional[U]]]]'
| Perform a left outer join of `self` and `other`.
|
| For each element (k, v) in `self`, the resulting RDD will either
| contain all pairs (k, (v, w)) for w in `other`, or the pair
| (k, (v, None)) if no elements in `other` have key k.
|
| Hash-partitions the resulting RDD into the given number of partitions.
|
| .. versionadded:: 0.7.0
|
| Parameters
| ----------
| other : :class:`RDD`
| another :class:`RDD`
| numPartitions : int, optional
| the number of partitions in new :class:`RDD`
|
| Returns
| -------
| :class:`RDD`
| a :class:`RDD` containing all pairs of elements with matching keys
|
| See Also
| --------
| :meth:`RDD.join`
| :meth:`RDD.rightOuterJoin`
| :meth:`RDD.fullOuterJoin`
| :meth:`pyspark.sql.DataFrame.join`
|
| Examples
| --------
| >>> rdd1 = sc.parallelize([("a", 1), ("b", 4)])
| >>> rdd2 = sc.parallelize([("a", 2)])
| >>> sorted(rdd1.leftOuterJoin(rdd2).collect())
| [('a', (1, 2)), ('b', (4, None))]
|
| localCheckpoint(self) -> None
| Mark this RDD for local checkpointing using Spark's existing caching layer.
|
| This method is for users who wish to truncate RDD lineages while skipping the expensive
| step of replicating the materialized data in a reliable distributed file system. This is
| useful for RDDs with long lineages that need to be truncated periodically (e.g. GraphX).
|
| Local checkpointing sacrifices fault-tolerance for performance. In particular, checkpointed
| data is written to ephemeral local storage in the executors instead of to a reliable,
| fault-tolerant storage. The effect is that if an executor fails during the computation,
| the checkpointed data may no longer be accessible, causing an irrecoverable job failure.
|
| This is NOT safe to use with dynamic allocation, which removes executors along
| with their cached blocks. If you must use both features, you are advised to set
| `spark.dynamicAllocation.cachedExecutorIdleTimeout` to a high value.
|
| The checkpoint directory set through :meth:`SparkContext.setCheckpointDir` is not used.
|
| .. versionadded:: 2.2.0
|
| See Also
| --------
| :meth:`RDD.checkpoint`
| :meth:`RDD.isLocallyCheckpointed`
|
| Examples
| --------
| >>> rdd = sc.range(5)
| >>> rdd.isLocallyCheckpointed()
| False
|
| >>> rdd.localCheckpoint()
| >>> rdd.isLocallyCheckpointed()
| True
|
| lookup(self: 'RDD[Tuple[K, V]]', key: ~K) -> List[~V]
| Return the list of values in the RDD for key `key`. This operation
| is done efficiently if the RDD has a known partitioner by only
| searching the partition that the key maps to.
|
| .. versionadded:: 1.2.0
|
| Parameters
| ----------
| key : K
| the key to look up
|
| Returns
| -------
| list
| the list of values in the :class:`RDD` for key `key`
|
| Examples
| --------
| >>> l = range(1000)
| >>> rdd = sc.parallelize(zip(l, l), 10)
| >>> rdd.lookup(42) # slow
| [42]
| >>> sorted = rdd.sortByKey()
| >>> sorted.lookup(42) # fast
| [42]
| >>> sorted.lookup(1024)
| []
| >>> rdd2 = sc.parallelize([(('a', 'b'), 'c')]).groupByKey()
| >>> list(rdd2.lookup(('a', 'b'))[0])
| ['c']
|
| map(self: 'RDD[T]', f: Callable[[~T], ~U], preservesPartitioning: bool = False) -> 'RDD[U]'
| Return a new RDD by applying a function to each element of this RDD.
|
| .. versionadded:: 0.7.0
|
| Parameters
| ----------
| f : function
| a function to run on each element of the RDD
| preservesPartitioning : bool, optional, default False
| indicates whether the input function preserves the partitioner,
| which should be False unless this is a pair RDD and the input
|
| Returns
| -------
| :class:`RDD`
| a new :class:`RDD` by applying a function to all elements
|
| See Also
| --------
| :meth:`RDD.flatMap`
| :meth:`RDD.mapPartitions`
| :meth:`RDD.mapPartitionsWithIndex`
| :meth:`RDD.mapPartitionsWithSplit`
|
| Examples
| --------
| >>> rdd = sc.parallelize(["b", "a", "c"])
| >>> sorted(rdd.map(lambda x: (x, 1)).collect())
| [('a', 1), ('b', 1), ('c', 1)]
|
| mapPartitions(self: 'RDD[T]', f: Callable[[Iterable[~T]], Iterable[~U]], preservesPartitioning: bool = False) -> 'RDD[U]'
| Return a new RDD by applying a function to each partition of this RDD.
|
| .. versionadded:: 0.7.0
|
| Parameters
| ----------
| f : function
| a function to run on each partition of the RDD
| preservesPartitioning : bool, optional, default False
| indicates whether the input function preserves the partitioner,
| which should be False unless this is a pair RDD and the input
|
| Returns
| -------
| :class:`RDD`
| a new :class:`RDD` by applying a function to each partition
|
| See Also
| --------
| :meth:`RDD.map`
| :meth:`RDD.flatMap`
| :meth:`RDD.mapPartitionsWithIndex`
| :meth:`RDD.mapPartitionsWithSplit`
| :meth:`RDDBarrier.mapPartitions`
|
| Examples
| --------
| >>> rdd = sc.parallelize([1, 2, 3, 4], 2)
| >>> def f(iterator): yield sum(iterator)
| ...
| >>> rdd.mapPartitions(f).collect()
| [3, 7]
|
| mapPartitionsWithIndex(self: 'RDD[T]', f: Callable[[int, Iterable[~T]], Iterable[~U]], preservesPartitioning: bool = False) -> 'RDD[U]'
| Return a new RDD by applying a function to each partition of this RDD,
| while tracking the index of the original partition.
|
| .. versionadded:: 0.7.0
|
| Parameters
| ----------
| f : function
| a function to run on each partition of the RDD
| preservesPartitioning : bool, optional, default False
| indicates whether the input function preserves the partitioner,
| which should be False unless this is a pair RDD and the input
|
| Returns
| -------
| :class:`RDD`
| a new :class:`RDD` by applying a function to each partition
|
| See Also
| --------
| :meth:`RDD.map`
| :meth:`RDD.flatMap`
| :meth:`RDD.mapPartitions`
| :meth:`RDD.mapPartitionsWithSplit`
| :meth:`RDDBarrier.mapPartitionsWithIndex`
|
| Examples
| --------
| >>> rdd = sc.parallelize([1, 2, 3, 4], 4)
| >>> def f(splitIndex, iterator): yield splitIndex
| ...
| >>> rdd.mapPartitionsWithIndex(f).sum()
| 6
|
| mapPartitionsWithSplit(self: 'RDD[T]', f: Callable[[int, Iterable[~T]], Iterable[~U]], preservesPartitioning: bool = False) -> 'RDD[U]'
| Return a new RDD by applying a function to each partition of this RDD,
| while tracking the index of the original partition.
|
| .. versionadded:: 0.7.0
|
| .. deprecated:: 0.9.0
| use meth:`RDD.mapPartitionsWithIndex` instead.
|
| Parameters
| ----------
| f : function
| a function to run on each partition of the RDD
| preservesPartitioning : bool, optional, default False
| indicates whether the input function preserves the partitioner,
| which should be False unless this is a pair RDD and the input
|
| Returns
| -------
| :class:`RDD`
| a new :class:`RDD` by applying a function to each partition
|
| See Also
| --------
| :meth:`RDD.map`
| :meth:`RDD.flatMap`
| :meth:`RDD.mapPartitions`
| :meth:`RDD.mapPartitionsWithIndex`
|
| Examples
| --------
| >>> rdd = sc.parallelize([1, 2, 3, 4], 4)
| >>> def f(splitIndex, iterator): yield splitIndex
| ...
| >>> rdd.mapPartitionsWithSplit(f).sum()
| 6
|
| mapValues(self: 'RDD[Tuple[K, V]]', f: Callable[[~V], ~U]) -> 'RDD[Tuple[K, U]]'
| Pass each value in the key-value pair RDD through a map function
| without changing the keys; this also retains the original RDD's
| partitioning.
|
| .. versionadded:: 0.7.0
|
| Parameters
| ----------
| f : function
| a function to turn a V into a U
|
| Returns
| -------
| :class:`RDD`
| a :class:`RDD` containing the keys and the mapped value
|
| See Also
| --------
| :meth:`RDD.map`
| :meth:`RDD.flatMapValues`
|
| Examples
| --------
| >>> rdd = sc.parallelize([("a", ["apple", "banana", "lemon"]), ("b", ["grapes"])])
| >>> def f(x): return len(x)
| ...
| >>> rdd.mapValues(f).collect()
| [('a', 3), ('b', 1)]
|
| max(self: 'RDD[T]', key: Optional[Callable[[~T], ForwardRef('S')]] = None) -> ~T
| Find the maximum item in this RDD.
|
| .. versionadded:: 1.0.0
|
| Parameters
| ----------
| key : function, optional
| A function used to generate key for comparing
|
| Returns
| -------
| T
| the maximum item
|
| See Also
| --------
| :meth:`RDD.min`
|
| Examples
| --------
| >>> rdd = sc.parallelize([1.0, 5.0, 43.0, 10.0])
| >>> rdd.max()
| 43.0
| >>> rdd.max(key=str)
| 5.0
|
| mean(self: 'RDD[NumberOrArray]') -> float
| Compute the mean of this RDD's elements.
|
| .. versionadded:: 0.9.1
|
| Returns
| -------
| float
| the mean of all elements
|
| See Also
| --------
| :meth:`RDD.stats`
| :meth:`RDD.sum`
| :meth:`RDD.meanApprox`
|
| Examples
| --------
| >>> sc.parallelize([1, 2, 3]).mean()
| 2.0
|
| meanApprox(self: 'RDD[Union[float, int]]', timeout: int, confidence: float = 0.95) -> pyspark.rdd.BoundedFloat
| Approximate operation to return the mean within a timeout
| or meet the confidence.
|
| .. versionadded:: 1.2.0
|
| Parameters
| ----------
| timeout : int
| maximum time to wait for the job, in milliseconds
| confidence : float
| the desired statistical confidence in the result
|
| Returns
| -------
| :class:`BoundedFloat`
| a potentially incomplete result, with error bounds
|
| See Also
| --------
| :meth:`RDD.mean`
|
| Examples
| --------
| >>> rdd = sc.parallelize(range(1000), 10)
| >>> r = sum(range(1000)) / 1000.0
| >>> abs(rdd.meanApprox(1000) - r) / r < 0.05
| True
|
| min(self: 'RDD[T]', key: Optional[Callable[[~T], ForwardRef('S')]] = None) -> ~T
| Find the minimum item in this RDD.
|
| .. versionadded:: 1.0.0
|
| Parameters
| ----------
| key : function, optional
| A function used to generate key for comparing
|
| Returns
| -------
| T
| the minimum item
|
| See Also
| --------
| :meth:`RDD.max`
|
| Examples
| --------
| >>> rdd = sc.parallelize([2.0, 5.0, 43.0, 10.0])
| >>> rdd.min()
| 2.0
| >>> rdd.min(key=str)
| 10.0
|
| name(self) -> Optional[str]
| Return the name of this RDD.
|
| .. versionadded:: 1.0.0
|
| Returns
| -------
| str
| :class:`RDD` name
|
| See Also
| --------
| :meth:`RDD.setName`
|
| Examples
| --------
| >>> rdd = sc.range(5)
| >>> rdd.name() == None
| True
|
| partitionBy(self: 'RDD[Tuple[K, V]]', numPartitions: Optional[int], partitionFunc: Callable[[~K], int] = <function portable_hash at 0x7d0ad45511c0>) -> 'RDD[Tuple[K, V]]'
| Return a copy of the RDD partitioned using the specified partitioner.
|
| .. versionadded:: 0.7.0
|
| Parameters
| ----------
| numPartitions : int, optional
| the number of partitions in new :class:`RDD`
| partitionFunc : function, optional, default `portable_hash`
| function to compute the partition index
|
| Returns
| -------
| :class:`RDD`
| a :class:`RDD` partitioned using the specified partitioner
|
| See Also
| --------
| :meth:`RDD.repartition`
| :meth:`RDD.repartitionAndSortWithinPartitions`
|
| Examples
| --------
| >>> pairs = sc.parallelize([1, 2, 3, 4, 2, 4, 1]).map(lambda x: (x, x))
| >>> sets = pairs.partitionBy(2).glom().collect()
| >>> len(set(sets[0]).intersection(set(sets[1])))
| 0
|
| persist(self: 'RDD[T]', storageLevel: pyspark.storagelevel.StorageLevel = StorageLevel(False, True, False, False, 1)) -> 'RDD[T]'
| Set this RDD's storage level to persist its values across operations
| after the first time it is computed. This can only be used to assign
| a new storage level if the RDD does not have a storage level set yet.
| If no storage level is specified defaults to (`MEMORY_ONLY`).
|
| .. versionadded:: 0.9.1
|
| Parameters
| ----------
| storageLevel : :class:`StorageLevel`, default `MEMORY_ONLY`
| the target storage level
|
| Returns
| -------
| :class:`RDD`
| The same :class:`RDD` with storage level set to `storageLevel`.
|
| See Also
| --------
| :meth:`RDD.cache`
| :meth:`RDD.unpersist`
| :meth:`RDD.getStorageLevel`
|
| Examples
| --------
| >>> rdd = sc.parallelize(["b", "a", "c"])
| >>> rdd.persist().is_cached
| True
| >>> str(rdd.getStorageLevel())
| 'Memory Serialized 1x Replicated'
| >>> _ = rdd.unpersist()
| >>> rdd.is_cached
| False
|
| >>> from pyspark import StorageLevel
| >>> rdd2 = sc.range(5)
| >>> _ = rdd2.persist(StorageLevel.MEMORY_AND_DISK)
| >>> rdd2.is_cached
| True
| >>> str(rdd2.getStorageLevel())
| 'Disk Memory Serialized 1x Replicated'
|
| Can not override existing storage level
|
| >>> _ = rdd2.persist(StorageLevel.MEMORY_ONLY_2)
| Traceback (most recent call last):
| ...
| py4j.protocol.Py4JJavaError: ...
|
| Assign another storage level after `unpersist`
|
| >>> _ = rdd2.unpersist()
| >>> rdd2.is_cached
| False
| >>> _ = rdd2.persist(StorageLevel.MEMORY_ONLY_2)
| >>> str(rdd2.getStorageLevel())
| 'Memory Serialized 2x Replicated'
| >>> rdd2.is_cached
| True
| >>> _ = rdd2.unpersist()
|
| pipe(self, command: str, env: Optional[Dict[str, str]] = None, checkCode: bool = False) -> 'RDD[str]'
| Return an RDD created by piping elements to a forked external process.
|
| .. versionadded:: 0.7.0
|
| Parameters
| ----------
| command : str
| command to run.
| env : dict, optional
| environment variables to set.
| checkCode : bool, optional
| whether to check the return value of the shell command.
|
| Returns
| -------
| :class:`RDD`
| a new :class:`RDD` of strings
|
| Examples
| --------
| >>> sc.parallelize(['1', '2', '', '3']).pipe('cat').collect()
| ['1', '2', '', '3']
|
| randomSplit(self: 'RDD[T]', weights: Sequence[Union[int, float]], seed: Optional[int] = None) -> 'List[RDD[T]]'
| Randomly splits this RDD with the provided weights.
|
| .. versionadded:: 1.3.0
|
| Parameters
| ----------
| weights : list
| weights for splits, will be normalized if they don't sum to 1
| seed : int, optional
| random seed
|
| Returns
| -------
| list
| split :class:`RDD`\s in a list
|
| See Also
| --------
| :meth:`pyspark.sql.DataFrame.randomSplit`
|
| Examples
| --------
| >>> rdd = sc.parallelize(range(500), 1)
| >>> rdd1, rdd2 = rdd.randomSplit([2, 3], 17)
| >>> len(rdd1.collect() + rdd2.collect())
| 500
| >>> 150 < rdd1.count() < 250
| True
| >>> 250 < rdd2.count() < 350
| True
|
| reduce(self: 'RDD[T]', f: Callable[[~T, ~T], ~T]) -> ~T
| Reduces the elements of this RDD using the specified commutative and
| associative binary operator. Currently reduces partitions locally.
|
| .. versionadded:: 0.7.0
|
| Parameters
| ----------
| f : function
| the reduce function
|
| Returns
| -------
| T
| the aggregated result
|
| See Also
| --------
| :meth:`RDD.treeReduce`
| :meth:`RDD.aggregate`
| :meth:`RDD.treeAggregate`
|
| Examples
| --------
| >>> from operator import add
| >>> sc.parallelize([1, 2, 3, 4, 5]).reduce(add)
| 15
| >>> sc.parallelize((2 for _ in range(10))).map(lambda x: 1).cache().reduce(add)
| 10
| >>> sc.parallelize([]).reduce(add)
| Traceback (most recent call last):
| ...
| ValueError: Can not reduce() empty RDD
|
| reduceByKey(self: 'RDD[Tuple[K, V]]', func: Callable[[~V, ~V], ~V], numPartitions: Optional[int] = None, partitionFunc: Callable[[~K], int] = <function portable_hash at 0x7d0ad45511c0>) -> 'RDD[Tuple[K, V]]'
| Merge the values for each key using an associative and commutative reduce function.
|
| This will also perform the merging locally on each mapper before
| sending results to a reducer, similarly to a "combiner" in MapReduce.
|
| Output will be partitioned with `numPartitions` partitions, or
| the default parallelism level if `numPartitions` is not specified.
| Default partitioner is hash-partition.
|
| .. versionadded:: 1.6.0
|
| Parameters
| ----------
| func : function
| the reduce function
| numPartitions : int, optional
| the number of partitions in new :class:`RDD`
| partitionFunc : function, optional, default `portable_hash`
| function to compute the partition index
|
| Returns
| -------
| :class:`RDD`
| a :class:`RDD` containing the keys and the aggregated result for each key
|
| See Also
| --------
| :meth:`RDD.reduceByKeyLocally`
| :meth:`RDD.combineByKey`
| :meth:`RDD.aggregateByKey`
| :meth:`RDD.foldByKey`
| :meth:`RDD.groupByKey`
|
| Examples
| --------
| >>> from operator import add
| >>> rdd = sc.parallelize([("a", 1), ("b", 1), ("a", 1)])
| >>> sorted(rdd.reduceByKey(add).collect())
| [('a', 2), ('b', 1)]
|
| reduceByKeyLocally(self: 'RDD[Tuple[K, V]]', func: Callable[[~V, ~V], ~V]) -> Dict[~K, ~V]
| Merge the values for each key using an associative and commutative reduce function, but
| return the results immediately to the master as a dictionary.
|
| This will also perform the merging locally on each mapper before
| sending results to a reducer, similarly to a "combiner" in MapReduce.
|
| .. versionadded:: 0.7.0
|
| Parameters
| ----------
| func : function
| the reduce function
|
| Returns
| -------
| dict
| a dict containing the keys and the aggregated result for each key
|
| See Also
| --------
| :meth:`RDD.reduceByKey`
| :meth:`RDD.aggregateByKey`
|
| Examples
| --------
| >>> from operator import add
| >>> rdd = sc.parallelize([("a", 1), ("b", 1), ("a", 1)])
| >>> sorted(rdd.reduceByKeyLocally(add).items())
| [('a', 2), ('b', 1)]
|
| repartition(self: 'RDD[T]', numPartitions: int) -> 'RDD[T]'
| Return a new RDD that has exactly numPartitions partitions.
|
| Can increase or decrease the level of parallelism in this RDD.
| Internally, this uses a shuffle to redistribute data.
| If you are decreasing the number of partitions in this RDD, consider
| using `coalesce`, which can avoid performing a shuffle.
|
| .. versionadded:: 1.0.0
|
| Parameters
| ----------
| numPartitions : int, optional
| the number of partitions in new :class:`RDD`
|
| Returns
| -------
| :class:`RDD`
| a :class:`RDD` with exactly numPartitions partitions
|
| See Also
| --------
| :meth:`RDD.coalesce`
| :meth:`RDD.partitionBy`
| :meth:`RDD.repartitionAndSortWithinPartitions`
|
| Examples
| --------
| >>> rdd = sc.parallelize([1,2,3,4,5,6,7], 4)
| >>> sorted(rdd.glom().collect())
| [[1], [2, 3], [4, 5], [6, 7]]
| >>> len(rdd.repartition(2).glom().collect())
| 2
| >>> len(rdd.repartition(10).glom().collect())
| 10
|
| repartitionAndSortWithinPartitions(self: 'RDD[Tuple[Any, Any]]', numPartitions: Optional[int] = None, partitionFunc: Callable[[Any], int] = <function portable_hash at 0x7d0ad45511c0>, ascending: bool = True, keyfunc: Callable[[Any], Any] = <function RDD.<lambda> at 0x7d0ad465b4c0>) -> 'RDD[Tuple[Any, Any]]'
| Repartition the RDD according to the given partitioner and, within each resulting partition,
| sort records by their keys.
|
| .. versionadded:: 1.2.0
|
| Parameters
| ----------
| numPartitions : int, optional
| the number of partitions in new :class:`RDD`
| partitionFunc : function, optional, default `portable_hash`
| a function to compute the partition index
| ascending : bool, optional, default True
| sort the keys in ascending or descending order
| keyfunc : function, optional, default identity mapping
| a function to compute the key
|
| Returns
| -------
| :class:`RDD`
| a new :class:`RDD`
|
| See Also
| --------
| :meth:`RDD.repartition`
| :meth:`RDD.partitionBy`
| :meth:`RDD.sortBy`
| :meth:`RDD.sortByKey`
|
| Examples
| --------
| >>> rdd = sc.parallelize([(0, 5), (3, 8), (2, 6), (0, 8), (3, 8), (1, 3)])
| >>> rdd2 = rdd.repartitionAndSortWithinPartitions(2, lambda x: x % 2, True)
| >>> rdd2.glom().collect()
| [[(0, 5), (0, 8), (2, 6)], [(1, 3), (3, 8), (3, 8)]]
|
| rightOuterJoin(self: 'RDD[Tuple[K, V]]', other: 'RDD[Tuple[K, U]]', numPartitions: Optional[int] = None) -> 'RDD[Tuple[K, Tuple[Optional[V], U]]]'
| Perform a right outer join of `self` and `other`.
|
| For each element (k, w) in `other`, the resulting RDD will either
| contain all pairs (k, (v, w)) for v in this, or the pair (k, (None, w))
| if no elements in `self` have key k.
|
| Hash-partitions the resulting RDD into the given number of partitions.
|
| .. versionadded:: 0.7.0
|
| Parameters
| ----------
| other : :class:`RDD`
| another :class:`RDD`
| numPartitions : int, optional
| the number of partitions in new :class:`RDD`
|
| Returns
| -------
| :class:`RDD`
| a :class:`RDD` containing all pairs of elements with matching keys
|
| See Also
| --------
| :meth:`RDD.join`
| :meth:`RDD.leftOuterJoin`
| :meth:`RDD.fullOuterJoin`
| :meth:`pyspark.sql.DataFrame.join`
|
| Examples
| --------
| >>> rdd1 = sc.parallelize([("a", 1), ("b", 4)])
| >>> rdd2 = sc.parallelize([("a", 2)])
| >>> sorted(rdd2.rightOuterJoin(rdd1).collect())
| [('a', (2, 1)), ('b', (None, 4))]
|
| sample(self: 'RDD[T]', withReplacement: bool, fraction: float, seed: Optional[int] = None) -> 'RDD[T]'
| Return a sampled subset of this RDD.
|
| .. versionadded:: 0.7.0
|
| Parameters
| ----------
| withReplacement : bool
| can elements be sampled multiple times (replaced when sampled out)
| fraction : float
| expected size of the sample as a fraction of this RDD's size
| without replacement: probability that each element is chosen; fraction must be [0, 1]
| with replacement: expected number of times each element is chosen; fraction must be >= 0
| seed : int, optional
| seed for the random number generator
|
| Returns
| -------
| :class:`RDD`
| a new :class:`RDD` containing a sampled subset of elements
|
| See Also
| --------
| :meth:`RDD.takeSample`
| :meth:`RDD.sampleByKey`
| :meth:`pyspark.sql.DataFrame.sample`
|
| Notes
| -----
| This is not guaranteed to provide exactly the fraction specified of the total
| count of the given :class:`DataFrame`.
|
| Examples
| --------
| >>> rdd = sc.parallelize(range(100), 4)
| >>> 6 <= rdd.sample(False, 0.1, 81).count() <= 14
| True
|
| sampleByKey(self: 'RDD[Tuple[K, V]]', withReplacement: bool, fractions: Dict[~K, Union[float, int]], seed: Optional[int] = None) -> 'RDD[Tuple[K, V]]'
| Return a subset of this RDD sampled by key (via stratified sampling).
| Create a sample of this RDD using variable sampling rates for
| different keys as specified by fractions, a key to sampling rate map.
|
| .. versionadded:: 0.7.0
|
| Parameters
| ----------
| withReplacement : bool
| whether to sample with or without replacement
| fractions : dict
| map of specific keys to sampling rates
| seed : int, optional
| seed for the random number generator
|
| Returns
| -------
| :class:`RDD`
| a :class:`RDD` containing the stratified sampling result
|
| See Also
| --------
| :meth:`RDD.sample`
|
| Examples
| --------
| >>> fractions = {"a": 0.2, "b": 0.1}
| >>> rdd = sc.parallelize(fractions.keys()).cartesian(sc.parallelize(range(0, 1000)))
| >>> sample = dict(rdd.sampleByKey(False, fractions, 2).groupByKey().collect())
| >>> 100 < len(sample["a"]) < 300 and 50 < len(sample["b"]) < 150
| True
| >>> max(sample["a"]) <= 999 and min(sample["a"]) >= 0
| True
| >>> max(sample["b"]) <= 999 and min(sample["b"]) >= 0
| True
|
| sampleStdev(self: 'RDD[NumberOrArray]') -> float
| Compute the sample standard deviation of this RDD's elements (which
| corrects for bias in estimating the standard deviation by dividing by
| N-1 instead of N).
|
| .. versionadded:: 0.9.1
|
| Returns
| -------
| float
| the sample standard deviation of all elements
|
| See Also
| --------
| :meth:`RDD.stats`
| :meth:`RDD.stdev`
| :meth:`RDD.variance`
| :meth:`RDD.sampleVariance`
|
| Examples
| --------
| >>> sc.parallelize([1, 2, 3]).sampleStdev()
| 1.0
|
| sampleVariance(self: 'RDD[NumberOrArray]') -> float
| Compute the sample variance of this RDD's elements (which corrects
| for bias in estimating the variance by dividing by N-1 instead of N).
|
| .. versionadded:: 0.9.1
|
| Returns
| -------
| float
| the sample variance of all elements
|
| See Also
| --------
| :meth:`RDD.stats`
| :meth:`RDD.variance`
| :meth:`RDD.stdev`
| :meth:`RDD.sampleStdev`
|
| Examples
| --------
| >>> sc.parallelize([1, 2, 3]).sampleVariance()
| 1.0
|
| saveAsHadoopDataset(self: 'RDD[Tuple[K, V]]', conf: Dict[str, str], keyConverter: Optional[str] = None, valueConverter: Optional[str] = None) -> None
| Output a Python RDD of key-value pairs (of form ``RDD[(K, V)]``) to any Hadoop file
| system, using the old Hadoop OutputFormat API (mapred package). Keys/values are
| converted for output using either user specified converters or, by default,
| "org.apache.spark.api.python.JavaToWritableConverter".
|
| .. versionadded:: 1.1.0
|
| Parameters
| ----------
| conf : dict
| Hadoop job configuration
| keyConverter : str, optional
| fully qualified classname of key converter (None by default)
| valueConverter : str, optional
| fully qualified classname of value converter (None by default)
|
| See Also
| --------
| :meth:`SparkContext.hadoopRDD`
| :meth:`RDD.saveAsNewAPIHadoopDataset`
| :meth:`RDD.saveAsHadoopFile`
| :meth:`RDD.saveAsNewAPIHadoopFile`
| :meth:`RDD.saveAsSequenceFile`
|
| Examples
| --------
| >>> import os
| >>> import tempfile
|
| Set the related classes
|
| >>> output_format_class = "org.apache.hadoop.mapred.TextOutputFormat"
| >>> input_format_class = "org.apache.hadoop.mapred.TextInputFormat"
| >>> key_class = "org.apache.hadoop.io.IntWritable"
| >>> value_class = "org.apache.hadoop.io.Text"
|
| >>> with tempfile.TemporaryDirectory() as d:
| ... path = os.path.join(d, "old_hadoop_file")
| ...
| ... # Create the conf for writing
| ... write_conf = {
| ... "mapred.output.format.class": output_format_class,
| ... "mapreduce.job.output.key.class": key_class,
| ... "mapreduce.job.output.value.class": value_class,
| ... "mapreduce.output.fileoutputformat.outputdir": path,
| ... }
| ...
| ... # Write a temporary Hadoop file
| ... rdd = sc.parallelize([(1, ""), (1, "a"), (3, "x")])
| ... rdd.saveAsHadoopDataset(conf=write_conf)
| ...
| ... # Create the conf for reading
| ... read_conf = {"mapreduce.input.fileinputformat.inputdir": path}
| ...
| ... # Load this Hadoop file as an RDD
| ... loaded = sc.hadoopRDD(input_format_class, key_class, value_class, conf=read_conf)
| ... sorted(loaded.collect())
| [(0, '1\t'), (0, '1\ta'), (0, '3\tx')]
|
| saveAsHadoopFile(self: 'RDD[Tuple[K, V]]', path: str, outputFormatClass: str, keyClass: Optional[str] = None, valueClass: Optional[str] = None, keyConverter: Optional[str] = None, valueConverter: Optional[str] = None, conf: Optional[Dict[str, str]] = None, compressionCodecClass: Optional[str] = None) -> None
| Output a Python RDD of key-value pairs (of form ``RDD[(K, V)]``) to any Hadoop file
| system, using the old Hadoop OutputFormat API (mapred package). Key and value types
| will be inferred if not specified. Keys and values are converted for output using either
| user specified converters or "org.apache.spark.api.python.JavaToWritableConverter". The
| `conf` is applied on top of the base Hadoop conf associated with the SparkContext
| of this RDD to create a merged Hadoop MapReduce job configuration for saving the data.
|
| .. versionadded:: 1.1.0
|
| Parameters
| ----------
| path : str
| path to Hadoop file
| outputFormatClass : str
| fully qualified classname of Hadoop OutputFormat
| (e.g. "org.apache.hadoop.mapred.SequenceFileOutputFormat")
| keyClass : str, optional
| fully qualified classname of key Writable class
| (e.g. "org.apache.hadoop.io.IntWritable", None by default)
| valueClass : str, optional
| fully qualified classname of value Writable class
| (e.g. "org.apache.hadoop.io.Text", None by default)
| keyConverter : str, optional
| fully qualified classname of key converter (None by default)
| valueConverter : str, optional
| fully qualified classname of value converter (None by default)
| conf : dict, optional
| (None by default)
| compressionCodecClass : str
| fully qualified classname of the compression codec class
| i.e. "org.apache.hadoop.io.compress.GzipCodec" (None by default)
|
| See Also
| --------
| :meth:`SparkContext.hadoopFile`
| :meth:`RDD.saveAsNewAPIHadoopFile`
| :meth:`RDD.saveAsHadoopDataset`
| :meth:`RDD.saveAsNewAPIHadoopDataset`
| :meth:`RDD.saveAsSequenceFile`
|
| Examples
| --------
| >>> import os
| >>> import tempfile
|
| Set the related classes
|
| >>> output_format_class = "org.apache.hadoop.mapred.TextOutputFormat"
| >>> input_format_class = "org.apache.hadoop.mapred.TextInputFormat"
| >>> key_class = "org.apache.hadoop.io.IntWritable"
| >>> value_class = "org.apache.hadoop.io.Text"
|
| >>> with tempfile.TemporaryDirectory() as d:
| ... path = os.path.join(d, "old_hadoop_file")
| ...
| ... # Write a temporary Hadoop file
| ... rdd = sc.parallelize([(1, ""), (1, "a"), (3, "x")])
| ... rdd.saveAsHadoopFile(path, output_format_class, key_class, value_class)
| ...
| ... # Load this Hadoop file as an RDD
| ... loaded = sc.hadoopFile(path, input_format_class, key_class, value_class)
| ... sorted(loaded.collect())
| [(0, '1\t'), (0, '1\ta'), (0, '3\tx')]
|
| saveAsNewAPIHadoopDataset(self: 'RDD[Tuple[K, V]]', conf: Dict[str, str], keyConverter: Optional[str] = None, valueConverter: Optional[str] = None) -> None
| Output a Python RDD of key-value pairs (of form ``RDD[(K, V)]``) to any Hadoop file
| system, using the new Hadoop OutputFormat API (mapreduce package). Keys/values are
| converted for output using either user specified converters or, by default,
| "org.apache.spark.api.python.JavaToWritableConverter".
|
| .. versionadded:: 1.1.0
|
| Parameters
| ----------
| conf : dict
| Hadoop job configuration
| keyConverter : str, optional
| fully qualified classname of key converter (None by default)
| valueConverter : str, optional
| fully qualified classname of value converter (None by default)
|
| See Also
| --------
| :meth:`SparkContext.newAPIHadoopRDD`
| :meth:`RDD.saveAsHadoopDataset`
| :meth:`RDD.saveAsHadoopFile`
| :meth:`RDD.saveAsNewAPIHadoopFile`
| :meth:`RDD.saveAsSequenceFile`
|
| Examples
| --------
| >>> import os
| >>> import tempfile
|
| Set the related classes
|
| >>> output_format_class = "org.apache.hadoop.mapreduce.lib.output.SequenceFileOutputFormat"
| >>> input_format_class = "org.apache.hadoop.mapreduce.lib.input.SequenceFileInputFormat"
| >>> key_class = "org.apache.hadoop.io.IntWritable"
| >>> value_class = "org.apache.hadoop.io.Text"
|
| >>> with tempfile.TemporaryDirectory() as d:
| ... path = os.path.join(d, "new_hadoop_file")
| ...
| ... # Create the conf for writing
| ... write_conf = {
| ... "mapreduce.job.outputformat.class": (output_format_class),
| ... "mapreduce.job.output.key.class": key_class,
| ... "mapreduce.job.output.value.class": value_class,
| ... "mapreduce.output.fileoutputformat.outputdir": path,
| ... }
| ...
| ... # Write a temporary Hadoop file
| ... rdd = sc.parallelize([(1, ""), (1, "a"), (3, "x")])
| ... rdd.saveAsNewAPIHadoopDataset(conf=write_conf)
| ...
| ... # Create the conf for reading
| ... read_conf = {"mapreduce.input.fileinputformat.inputdir": path}
| ...
| ... # Load this Hadoop file as an RDD
| ... loaded = sc.newAPIHadoopRDD(input_format_class,
| ... key_class, value_class, conf=read_conf)
| ... sorted(loaded.collect())
| [(1, ''), (1, 'a'), (3, 'x')]
|
| saveAsNewAPIHadoopFile(self: 'RDD[Tuple[K, V]]', path: str, outputFormatClass: str, keyClass: Optional[str] = None, valueClass: Optional[str] = None, keyConverter: Optional[str] = None, valueConverter: Optional[str] = None, conf: Optional[Dict[str, str]] = None) -> None
| Output a Python RDD of key-value pairs (of form ``RDD[(K, V)]``) to any Hadoop file
| system, using the new Hadoop OutputFormat API (mapreduce package). Key and value types
| will be inferred if not specified. Keys and values are converted for output using either
| user specified converters or "org.apache.spark.api.python.JavaToWritableConverter". The
| `conf` is applied on top of the base Hadoop conf associated with the SparkContext
| of this RDD to create a merged Hadoop MapReduce job configuration for saving the data.
|
| .. versionadded:: 1.1.0
|
| Parameters
| ----------
| path : str
| path to Hadoop file
| outputFormatClass : str
| fully qualified classname of Hadoop OutputFormat
| (e.g. "org.apache.hadoop.mapreduce.lib.output.SequenceFileOutputFormat")
| keyClass : str, optional
| fully qualified classname of key Writable class
| (e.g. "org.apache.hadoop.io.IntWritable", None by default)
| valueClass : str, optional
| fully qualified classname of value Writable class
| (e.g. "org.apache.hadoop.io.Text", None by default)
| keyConverter : str, optional
| fully qualified classname of key converter (None by default)
| valueConverter : str, optional
| fully qualified classname of value converter (None by default)
| conf : dict, optional
| Hadoop job configuration (None by default)
|
| See Also
| --------
| :meth:`SparkContext.newAPIHadoopFile`
| :meth:`RDD.saveAsHadoopDataset`
| :meth:`RDD.saveAsNewAPIHadoopDataset`
| :meth:`RDD.saveAsHadoopFile`
| :meth:`RDD.saveAsSequenceFile`
|
| Examples
| --------
| >>> import os
| >>> import tempfile
|
| Set the class of output format
|
| >>> output_format_class = "org.apache.hadoop.mapreduce.lib.output.SequenceFileOutputFormat"
|
| >>> with tempfile.TemporaryDirectory() as d:
| ... path = os.path.join(d, "hadoop_file")
| ...
| ... # Write a temporary Hadoop file
| ... rdd = sc.parallelize([(1, {3.0: "bb"}), (2, {1.0: "aa"}), (3, {2.0: "dd"})])
| ... rdd.saveAsNewAPIHadoopFile(path, output_format_class)
| ...
| ... # Load this Hadoop file as an RDD
| ... sorted(sc.sequenceFile(path).collect())
| [(1, {3.0: 'bb'}), (2, {1.0: 'aa'}), (3, {2.0: 'dd'})]
|
| saveAsPickleFile(self, path: str, batchSize: int = 10) -> None
| Save this RDD as a SequenceFile of serialized objects. The serializer
| used is :class:`pyspark.serializers.CPickleSerializer`, default batch size
| is 10.
|
| .. versionadded:: 1.1.0
|
| Parameters
| ----------
| path : str
| path to pickled file
| batchSize : int, optional, default 10
| the number of Python objects represented as a single Java object.
|
| See Also
| --------
| :meth:`SparkContext.pickleFile`
|
| Examples
| --------
| >>> import os
| >>> import tempfile
| >>> with tempfile.TemporaryDirectory() as d:
| ... path = os.path.join(d, "pickle_file")
| ...
| ... # Write a temporary pickled file
| ... sc.parallelize(range(10)).saveAsPickleFile(path, 3)
| ...
| ... # Load picked file as an RDD
| ... sorted(sc.pickleFile(path, 3).collect())
| [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
|
| saveAsSequenceFile(self: 'RDD[Tuple[K, V]]', path: str, compressionCodecClass: Optional[str] = None) -> None
| Output a Python RDD of key-value pairs (of form ``RDD[(K, V)]``) to any Hadoop file
| system, using the "org.apache.hadoop.io.Writable" types that we convert from the
| RDD's key and value types. The mechanism is as follows:
|
| 1. Pickle is used to convert pickled Python RDD into RDD of Java objects.
| 2. Keys and values of this Java RDD are converted to Writables and written out.
|
| .. versionadded:: 1.1.0
|
| Parameters
| ----------
| path : str
| path to sequence file
| compressionCodecClass : str, optional
| fully qualified classname of the compression codec class
| i.e. "org.apache.hadoop.io.compress.GzipCodec" (None by default)
|
| See Also
| --------
| :meth:`SparkContext.sequenceFile`
| :meth:`RDD.saveAsHadoopFile`
| :meth:`RDD.saveAsNewAPIHadoopFile`
| :meth:`RDD.saveAsHadoopDataset`
| :meth:`RDD.saveAsNewAPIHadoopDataset`
| :meth:`RDD.saveAsSequenceFile`
|
| Examples
| --------
| >>> import os
| >>> import tempfile
|
| Set the related classes
|
| >>> with tempfile.TemporaryDirectory() as d:
| ... path = os.path.join(d, "sequence_file")
| ...
| ... # Write a temporary sequence file
| ... rdd = sc.parallelize([(1, ""), (1, "a"), (3, "x")])
| ... rdd.saveAsSequenceFile(path)
| ...
| ... # Load this sequence file as an RDD
| ... loaded = sc.sequenceFile(path)
| ... sorted(loaded.collect())
| [(1, ''), (1, 'a'), (3, 'x')]
|
| saveAsTextFile(self, path: str, compressionCodecClass: Optional[str] = None) -> None
| Save this RDD as a text file, using string representations of elements.
|
| .. versionadded:: 0.7.0
|
| Parameters
| ----------
| path : str
| path to text file
| compressionCodecClass : str, optional
| fully qualified classname of the compression codec class
| i.e. "org.apache.hadoop.io.compress.GzipCodec" (None by default)
|
| See Also
| --------
| :meth:`SparkContext.textFile`
| :meth:`SparkContext.wholeTextFiles`
|
| Examples
| --------
| >>> import os
| >>> import tempfile
| >>> from fileinput import input
| >>> from glob import glob
| >>> with tempfile.TemporaryDirectory() as d1:
| ... path1 = os.path.join(d1, "text_file1")
| ...
| ... # Write a temporary text file
| ... sc.parallelize(range(10)).saveAsTextFile(path1)
| ...
| ... # Load text file as an RDD
| ... ''.join(sorted(input(glob(path1 + "/part-0000*"))))
| '0\n1\n2\n3\n4\n5\n6\n7\n8\n9\n'
|
| Empty lines are tolerated when saving to text files.
|
| >>> with tempfile.TemporaryDirectory() as d2:
| ... path2 = os.path.join(d2, "text2_file2")
| ...
| ... # Write another temporary text file
| ... sc.parallelize(['', 'foo', '', 'bar', '']).saveAsTextFile(path2)
| ...
| ... # Load text file as an RDD
| ... ''.join(sorted(input(glob(path2 + "/part-0000*"))))
| '\n\n\nbar\nfoo\n'
|
| Using compressionCodecClass
|
| >>> from fileinput import input, hook_compressed
| >>> with tempfile.TemporaryDirectory() as d3:
| ... path3 = os.path.join(d3, "text3")
| ... codec = "org.apache.hadoop.io.compress.GzipCodec"
| ...
| ... # Write another temporary text file with specified codec
| ... sc.parallelize(['foo', 'bar']).saveAsTextFile(path3, codec)
| ...
| ... # Load text file as an RDD
| ... result = sorted(input(glob(path3 + "/part*.gz"), openhook=hook_compressed))
| ... ''.join([r.decode('utf-8') if isinstance(r, bytes) else r for r in result])
| 'bar\nfoo\n'
|
| setName(self: 'RDD[T]', name: str) -> 'RDD[T]'
| Assign a name to this RDD.
|
| .. versionadded:: 1.0.0
|
| Parameters
| ----------
| name : str
| new name
|
| Returns
| -------
| :class:`RDD`
| the same :class:`RDD` with name updated
|
| See Also
| --------
| :meth:`RDD.name`
|
| Examples
| --------
| >>> rdd = sc.parallelize([1, 2])
| >>> rdd.setName('I am an RDD').name()
| 'I am an RDD'
|
| sortBy(self: 'RDD[T]', keyfunc: Callable[[~T], ForwardRef('S')], ascending: bool = True, numPartitions: Optional[int] = None) -> 'RDD[T]'
| Sorts this RDD by the given keyfunc
|
| .. versionadded:: 1.1.0
|
| Parameters
| ----------
| keyfunc : function
| a function to compute the key
| ascending : bool, optional, default True
| sort the keys in ascending or descending order
| numPartitions : int, optional
| the number of partitions in new :class:`RDD`
|
| Returns
| -------
| :class:`RDD`
| a new :class:`RDD`
|
| See Also
| --------
| :meth:`RDD.sortByKey`
| :meth:`pyspark.sql.DataFrame.sort`
|
| Examples
| --------
| >>> tmp = [('a', 1), ('b', 2), ('1', 3), ('d', 4), ('2', 5)]
| >>> sc.parallelize(tmp).sortBy(lambda x: x[0]).collect()
| [('1', 3), ('2', 5), ('a', 1), ('b', 2), ('d', 4)]
| >>> sc.parallelize(tmp).sortBy(lambda x: x[1]).collect()
| [('a', 1), ('b', 2), ('1', 3), ('d', 4), ('2', 5)]
|
| sortByKey(self: 'RDD[Tuple[K, V]]', ascending: Optional[bool] = True, numPartitions: Optional[int] = None, keyfunc: Callable[[Any], Any] = <function RDD.<lambda> at 0x7d0ad465b880>) -> 'RDD[Tuple[K, V]]'
| Sorts this RDD, which is assumed to consist of (key, value) pairs.
|
| .. versionadded:: 0.9.1
|
| Parameters
| ----------
| ascending : bool, optional, default True
| sort the keys in ascending or descending order
| numPartitions : int, optional
| the number of partitions in new :class:`RDD`
| keyfunc : function, optional, default identity mapping
| a function to compute the key
|
| Returns
| -------
| :class:`RDD`
| a new :class:`RDD`
|
| See Also
| --------
| :meth:`RDD.sortBy`
| :meth:`pyspark.sql.DataFrame.sort`
|
| Examples
| --------
| >>> tmp = [('a', 1), ('b', 2), ('1', 3), ('d', 4), ('2', 5)]
| >>> sc.parallelize(tmp).sortByKey().first()
| ('1', 3)
| >>> sc.parallelize(tmp).sortByKey(True, 1).collect()
| [('1', 3), ('2', 5), ('a', 1), ('b', 2), ('d', 4)]
| >>> sc.parallelize(tmp).sortByKey(True, 2).collect()
| [('1', 3), ('2', 5), ('a', 1), ('b', 2), ('d', 4)]
| >>> tmp2 = [('Mary', 1), ('had', 2), ('a', 3), ('little', 4), ('lamb', 5)]
| >>> tmp2.extend([('whose', 6), ('fleece', 7), ('was', 8), ('white', 9)])
| >>> sc.parallelize(tmp2).sortByKey(True, 3, keyfunc=lambda k: k.lower()).collect()
| [('a', 3), ('fleece', 7), ('had', 2), ('lamb', 5),...('white', 9), ('whose', 6)]
|
| stats(self: 'RDD[NumberOrArray]') -> pyspark.statcounter.StatCounter
| Return a :class:`StatCounter` object that captures the mean, variance
| and count of the RDD's elements in one operation.
|
| .. versionadded:: 0.9.1
|
| Returns
| -------
| :class:`StatCounter`
| a :class:`StatCounter` capturing the mean, variance and count of all elements
|
| See Also
| --------
| :meth:`RDD.stdev`
| :meth:`RDD.sampleStdev`
| :meth:`RDD.variance`
| :meth:`RDD.sampleVariance`
| :meth:`RDD.histogram`
| :meth:`pyspark.sql.DataFrame.stat`
|
| stdev(self: 'RDD[NumberOrArray]') -> float
| Compute the standard deviation of this RDD's elements.
|
| .. versionadded:: 0.9.1
|
| Returns
| -------
| float
| the standard deviation of all elements
|
| See Also
| --------
| :meth:`RDD.stats`
| :meth:`RDD.sampleStdev`
| :meth:`RDD.variance`
| :meth:`RDD.sampleVariance`
|
| Examples
| --------
| >>> sc.parallelize([1, 2, 3]).stdev()
| 0.816...
|
| subtract(self: 'RDD[T]', other: 'RDD[T]', numPartitions: Optional[int] = None) -> 'RDD[T]'
| Return each value in `self` that is not contained in `other`.
|
| .. versionadded:: 0.9.1
|
| Parameters
| ----------
| other : :class:`RDD`
| another :class:`RDD`
| numPartitions : int, optional
| the number of partitions in new :class:`RDD`
|
| Returns
| -------
| :class:`RDD`
| a :class:`RDD` with the elements from this that are not in `other`
|
| See Also
| --------
| :meth:`RDD.subtractByKey`
|
| Examples
| --------
| >>> rdd1 = sc.parallelize([("a", 1), ("b", 4), ("b", 5), ("a", 3)])
| >>> rdd2 = sc.parallelize([("a", 3), ("c", None)])
| >>> sorted(rdd1.subtract(rdd2).collect())
| [('a', 1), ('b', 4), ('b', 5)]
|
| subtractByKey(self: 'RDD[Tuple[K, V]]', other: 'RDD[Tuple[K, Any]]', numPartitions: Optional[int] = None) -> 'RDD[Tuple[K, V]]'
| Return each (key, value) pair in `self` that has no pair with matching
| key in `other`.
|
| .. versionadded:: 0.9.1
|
| Parameters
| ----------
| other : :class:`RDD`
| another :class:`RDD`
| numPartitions : int, optional
| the number of partitions in new :class:`RDD`
|
| Returns
| -------
| :class:`RDD`
| a :class:`RDD` with the pairs from this whose keys are not in `other`
|
| See Also
| --------
| :meth:`RDD.subtract`
|
| Examples
| --------
| >>> rdd1 = sc.parallelize([("a", 1), ("b", 4), ("b", 5), ("a", 2)])
| >>> rdd2 = sc.parallelize([("a", 3), ("c", None)])
| >>> sorted(rdd1.subtractByKey(rdd2).collect())
| [('b', 4), ('b', 5)]
|
| sum(self: 'RDD[NumberOrArray]') -> 'NumberOrArray'
| Add up the elements in this RDD.
|
| .. versionadded:: 0.7.0
|
| Returns
| -------
| float, int, or complex
| the sum of all elements
|
| See Also
| --------
| :meth:`RDD.mean`
| :meth:`RDD.sumApprox`
|
| Examples
| --------
| >>> sc.parallelize([1.0, 2.0, 3.0]).sum()
| 6.0
|
| sumApprox(self: 'RDD[Union[float, int]]', timeout: int, confidence: float = 0.95) -> pyspark.rdd.BoundedFloat
| Approximate operation to return the sum within a timeout
| or meet the confidence.
|
| .. versionadded:: 1.2.0
|
| Parameters
| ----------
| timeout : int
| maximum time to wait for the job, in milliseconds
| confidence : float
| the desired statistical confidence in the result
|
| Returns
| -------
| :class:`BoundedFloat`
| a potentially incomplete result, with error bounds
|
| See Also
| --------
| :meth:`RDD.sum`
|
| Examples
| --------
| >>> rdd = sc.parallelize(range(1000), 10)
| >>> r = sum(range(1000))
| >>> abs(rdd.sumApprox(1000) - r) / r < 0.05
| True
|
| take(self: 'RDD[T]', num: int) -> List[~T]
| Take the first num elements of the RDD.
|
| It works by first scanning one partition, and use the results from
| that partition to estimate the number of additional partitions needed
| to satisfy the limit.
|
| Translated from the Scala implementation in RDD#take().
|
| .. versionadded:: 0.7.0
|
| Parameters
| ----------
| num : int
| first number of elements
|
| Returns
| -------
| list
| the first `num` elements
|
| See Also
| --------
| :meth:`RDD.first`
| :meth:`pyspark.sql.DataFrame.take`
|
| Notes
| -----
| This method should only be used if the resulting array is expected
| to be small, as all the data is loaded into the driver's memory.
|
| Examples
| --------
| >>> sc.parallelize([2, 3, 4, 5, 6]).cache().take(2)
| [2, 3]
| >>> sc.parallelize([2, 3, 4, 5, 6]).take(10)
| [2, 3, 4, 5, 6]
| >>> sc.parallelize(range(100), 100).filter(lambda x: x > 90).take(3)
| [91, 92, 93]
|
| takeOrdered(self: 'RDD[T]', num: int, key: Optional[Callable[[~T], ForwardRef('S')]] = None) -> List[~T]
| Get the N elements from an RDD ordered in ascending order or as
| specified by the optional key function.
|
| .. versionadded:: 1.0.0
|
| Parameters
| ----------
| num : int
| top N
| key : function, optional
| a function used to generate key for comparing
|
| Returns
| -------
| list
| the top N elements
|
| See Also
| --------
| :meth:`RDD.top`
| :meth:`RDD.max`
| :meth:`RDD.min`
|
| Notes
| -----
| This method should only be used if the resulting array is expected
| to be small, as all the data is loaded into the driver's memory.
|
| Examples
| --------
| >>> sc.parallelize([10, 1, 2, 9, 3, 4, 5, 6, 7]).takeOrdered(6)
| [1, 2, 3, 4, 5, 6]
| >>> sc.parallelize([10, 1, 2, 9, 3, 4, 5, 6, 7], 2).takeOrdered(6, key=lambda x: -x)
| [10, 9, 7, 6, 5, 4]
| >>> sc.emptyRDD().takeOrdered(3)
| []
|
| takeSample(self: 'RDD[T]', withReplacement: bool, num: int, seed: Optional[int] = None) -> List[~T]
| Return a fixed-size sampled subset of this RDD.
|
| .. versionadded:: 1.3.0
|
| Parameters
| ----------
| withReplacement : bool
| whether sampling is done with replacement
| num : int
| size of the returned sample
| seed : int, optional
| random seed
|
| Returns
| -------
| list
| a fixed-size sampled subset of this :class:`RDD` in an array
|
| See Also
| --------
| :meth:`RDD.sample`
|
| Notes
| -----
| This method should only be used if the resulting array is expected
| to be small, as all the data is loaded into the driver's memory.
|
| Examples
| --------
| >>> import sys
| >>> rdd = sc.parallelize(range(0, 10))
| >>> len(rdd.takeSample(True, 20, 1))
| 20
| >>> len(rdd.takeSample(False, 5, 2))
| 5
| >>> len(rdd.takeSample(False, 15, 3))
| 10
| >>> sc.range(0, 10).takeSample(False, sys.maxsize)
| Traceback (most recent call last):
| ...
| ValueError: Sample size cannot be greater than ...
|
| toDF(self: 'RDD[Any]', schema: Optional[Any] = None, sampleRatio: Optional[float] = None) -> 'DataFrame'
|
| toDebugString(self) -> Optional[bytes]
| A description of this RDD and its recursive dependencies for debugging.
|
| .. versionadded:: 1.0.0
|
| Returns
| -------
| bytes
| debugging information of this :class:`RDD`
|
| Examples
| --------
| >>> rdd = sc.range(5)
| >>> rdd.toDebugString()
| b'...PythonRDD...ParallelCollectionRDD...'
|
| toLocalIterator(self: 'RDD[T]', prefetchPartitions: bool = False) -> Iterator[~T]
| Return an iterator that contains all of the elements in this RDD.
| The iterator will consume as much memory as the largest partition in this RDD.
| With prefetch it may consume up to the memory of the 2 largest partitions.
|
| .. versionadded:: 1.3.0
|
| Parameters
| ----------
| prefetchPartitions : bool, optional
| If Spark should pre-fetch the next partition
| before it is needed.
|
| Returns
| -------
| :class:`collections.abc.Iterator`
| an iterator that contains all of the elements in this :class:`RDD`
|
| See Also
| --------
| :meth:`RDD.collect`
| :meth:`pyspark.sql.DataFrame.toLocalIterator`
|
| Examples
| --------
| >>> rdd = sc.parallelize(range(10))
| >>> [x for x in rdd.toLocalIterator()]
| [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
|
| top(self: 'RDD[T]', num: int, key: Optional[Callable[[~T], ForwardRef('S')]] = None) -> List[~T]
| Get the top N elements from an RDD.
|
| .. versionadded:: 1.0.0
|
| Parameters
| ----------
| num : int
| top N
| key : function, optional
| a function used to generate key for comparing
|
| Returns
| -------
| list
| the top N elements
|
| See Also
| --------
| :meth:`RDD.takeOrdered`
| :meth:`RDD.max`
| :meth:`RDD.min`
|
| Notes
| -----
| This method should only be used if the resulting array is expected
| to be small, as all the data is loaded into the driver's memory.
|
| It returns the list sorted in descending order.
|
| Examples
| --------
| >>> sc.parallelize([10, 4, 2, 12, 3]).top(1)
| [12]
| >>> sc.parallelize([2, 3, 4, 5, 6], 2).top(2)
| [6, 5]
| >>> sc.parallelize([10, 4, 2, 12, 3]).top(3, key=str)
| [4, 3, 2]
|
| treeAggregate(self: 'RDD[T]', zeroValue: ~U, seqOp: Callable[[~U, ~T], ~U], combOp: Callable[[~U, ~U], ~U], depth: int = 2) -> ~U
| Aggregates the elements of this RDD in a multi-level tree
| pattern.
|
| .. versionadded:: 1.3.0
|
| Parameters
| ----------
| zeroValue : U
| the initial value for the accumulated result of each partition
| seqOp : function
| a function used to accumulate results within a partition
| combOp : function
| an associative function used to combine results from different partitions
| depth : int, optional, default 2
| suggested depth of the tree
|
| Returns
| -------
| U
| the aggregated result
|
| See Also
| --------
| :meth:`RDD.aggregate`
| :meth:`RDD.treeReduce`
|
| Examples
| --------
| >>> add = lambda x, y: x + y
| >>> rdd = sc.parallelize([-5, -4, -3, -2, -1, 1, 2, 3, 4], 10)
| >>> rdd.treeAggregate(0, add, add)
| -5
| >>> rdd.treeAggregate(0, add, add, 1)
| -5
| >>> rdd.treeAggregate(0, add, add, 2)
| -5
| >>> rdd.treeAggregate(0, add, add, 5)
| -5
| >>> rdd.treeAggregate(0, add, add, 10)
| -5
|
| treeReduce(self: 'RDD[T]', f: Callable[[~T, ~T], ~T], depth: int = 2) -> ~T
| Reduces the elements of this RDD in a multi-level tree pattern.
|
| .. versionadded:: 1.3.0
|
| Parameters
| ----------
| f : function
| the reduce function
| depth : int, optional, default 2
| suggested depth of the tree (default: 2)
|
| Returns
| -------
| T
| the aggregated result
|
| See Also
| --------
| :meth:`RDD.reduce`
| :meth:`RDD.aggregate`
| :meth:`RDD.treeAggregate`
|
| Examples
| --------
| >>> add = lambda x, y: x + y
| >>> rdd = sc.parallelize([-5, -4, -3, -2, -1, 1, 2, 3, 4], 10)
| >>> rdd.treeReduce(add)
| -5
| >>> rdd.treeReduce(add, 1)
| -5
| >>> rdd.treeReduce(add, 2)
| -5
| >>> rdd.treeReduce(add, 5)
| -5
| >>> rdd.treeReduce(add, 10)
| -5
|
| union(self: 'RDD[T]', other: 'RDD[U]') -> 'RDD[Union[T, U]]'
| Return the union of this RDD and another one.
|
| .. versionadded:: 0.7.0
|
| Parameters
| ----------
| other : :class:`RDD`
| another :class:`RDD`
|
| Returns
| -------
| :class:`RDD`
| the union of this :class:`RDD` and another one
|
| See Also
| --------
| :meth:`SparkContext.union`
| :meth:`pyspark.sql.DataFrame.union`
|
| Examples
| --------
| >>> rdd = sc.parallelize([1, 1, 2, 3])
| >>> rdd.union(rdd).collect()
| [1, 1, 2, 3, 1, 1, 2, 3]
|
| unpersist(self: 'RDD[T]', blocking: bool = False) -> 'RDD[T]'
| Mark the RDD as non-persistent, and remove all blocks for it from
| memory and disk.
|
| .. versionadded:: 0.9.1
|
| Parameters
| ----------
| blocking : bool, optional, default False
| whether to block until all blocks are deleted
|
| .. versionadded:: 3.0.0
|
| Returns
| -------
| :class:`RDD`
| The same :class:`RDD`
|
| See Also
| --------
| :meth:`RDD.cache`
| :meth:`RDD.persist`
| :meth:`RDD.getStorageLevel`
|
| Examples
| --------
| >>> rdd = sc.range(5)
| >>> rdd.is_cached
| False
| >>> _ = rdd.unpersist()
| >>> rdd.is_cached
| False
| >>> _ = rdd.cache()
| >>> rdd.is_cached
| True
| >>> _ = rdd.unpersist()
| >>> rdd.is_cached
| False
| >>> _ = rdd.unpersist()
|
| values(self: 'RDD[Tuple[K, V]]') -> 'RDD[V]'
| Return an RDD with the values of each tuple.
|
| .. versionadded:: 0.7.0
|
| Returns
| -------
| :class:`RDD`
| a :class:`RDD` only containing the values
|
| See Also
| --------
| :meth:`RDD.keys`
|
| Examples
| --------
| >>> rdd = sc.parallelize([(1, 2), (3, 4)]).values()
| >>> rdd.collect()
| [2, 4]
|
| variance(self: 'RDD[NumberOrArray]') -> float
| Compute the variance of this RDD's elements.
|
| .. versionadded:: 0.9.1
|
| Returns
| -------
| float
| the variance of all elements
|
| See Also
| --------
| :meth:`RDD.stats`
| :meth:`RDD.sampleVariance`
| :meth:`RDD.stdev`
| :meth:`RDD.sampleStdev`
|
| Examples
| --------
| >>> sc.parallelize([1, 2, 3]).variance()
| 0.666...
|
| withResources(self: 'RDD[T]', profile: pyspark.resource.profile.ResourceProfile) -> 'RDD[T]'
| Specify a :class:`pyspark.resource.ResourceProfile` to use when calculating this RDD.
| This is only supported on certain cluster managers and currently requires dynamic
| allocation to be enabled. It will result in new executors with the resources specified
| being acquired to calculate the RDD.
|
| .. versionadded:: 3.1.0
|
| Parameters
| ----------
| profile : :class:`pyspark.resource.ResourceProfile`
| a resource profile
|
| Returns
| -------
| :class:`RDD`
| the same :class:`RDD` with user specified profile
|
| See Also
| --------
| :meth:`RDD.getResourceProfile`
|
| Notes
| -----
| This API is experimental
|
| zip(self: 'RDD[T]', other: 'RDD[U]') -> 'RDD[Tuple[T, U]]'
| Zips this RDD with another one, returning key-value pairs with the
| first element in each RDD second element in each RDD, etc. Assumes
| that the two RDDs have the same number of partitions and the same
| number of elements in each partition (e.g. one was made through
| a map on the other).
|
| .. versionadded:: 1.0.0
|
| Parameters
| ----------
| other : :class:`RDD`
| another :class:`RDD`
|
| Returns
| -------
| :class:`RDD`
| a :class:`RDD` containing the zipped key-value pairs
|
| See Also
| --------
| :meth:`RDD.zipWithIndex`
| :meth:`RDD.zipWithUniqueId`
|
| Examples
| --------
| >>> rdd1 = sc.parallelize(range(0,5))
| >>> rdd2 = sc.parallelize(range(1000, 1005))
| >>> rdd1.zip(rdd2).collect()
| [(0, 1000), (1, 1001), (2, 1002), (3, 1003), (4, 1004)]
|
| zipWithIndex(self: 'RDD[T]') -> 'RDD[Tuple[T, int]]'
| Zips this RDD with its element indices.
|
| The ordering is first based on the partition index and then the
| ordering of items within each partition. So the first item in
| the first partition gets index 0, and the last item in the last
| partition receives the largest index.
|
| This method needs to trigger a spark job when this RDD contains
| more than one partitions.
|
| .. versionadded:: 1.2.0
|
| Returns
| -------
| :class:`RDD`
| a :class:`RDD` containing the zipped key-index pairs
|
| See Also
| --------
| :meth:`RDD.zip`
| :meth:`RDD.zipWithUniqueId`
|
| Examples
| --------
| >>> sc.parallelize(["a", "b", "c", "d"], 3).zipWithIndex().collect()
| [('a', 0), ('b', 1), ('c', 2), ('d', 3)]
|
| zipWithUniqueId(self: 'RDD[T]') -> 'RDD[Tuple[T, int]]'
| Zips this RDD with generated unique Long ids.
|
| Items in the kth partition will get ids k, n+k, 2*n+k, ..., where
| n is the number of partitions. So there may exist gaps, but this
| method won't trigger a spark job, which is different from
| :meth:`zipWithIndex`.
|
| .. versionadded:: 1.2.0
|
| Returns
| -------
| :class:`RDD`
| a :class:`RDD` containing the zipped key-UniqueId pairs
|
| See Also
| --------
| :meth:`RDD.zip`
| :meth:`RDD.zipWithIndex`
|
| Examples
| --------
| >>> sc.parallelize(["a", "b", "c", "d", "e"], 3).zipWithUniqueId().collect()
| [('a', 0), ('b', 1), ('c', 4), ('d', 2), ('e', 5)]
|
| ----------------------------------------------------------------------
| Readonly properties inherited from RDD:
|
| context
| The :class:`SparkContext` that this RDD was created on.
|
| .. versionadded:: 0.7.0
|
| Returns
| -------
| :class:`SparkContext`
| The :class:`SparkContext` that this RDD was created on
|
| Examples
| --------
| >>> rdd = sc.range(5)
| >>> rdd.context
| <SparkContext ...>
| >>> rdd.context is sc
| True
|
| ----------------------------------------------------------------------
| Data descriptors inherited from RDD:
|
| __dict__
| dictionary for instance variables
|
| __weakref__
| list of weak references to the object
|
| ----------------------------------------------------------------------
| Class methods inherited from typing.Generic:
|
| __class_getitem__(...)
| Parameterizes a generic class.
|
| At least, parameterizing a generic class is the *main* thing this
| method does. For example, for some generic class `Foo`, this is called
| when we do `Foo[int]` - there, with `cls=Foo` and `params=int`.
|
| However, note that this method is also called when defining generic
| classes in the first place with `class Foo[T]: ...`.
|
| __init_subclass__(...)
| Function to initialize subclasses.
# Veamos en cuántas particiones se dividirá el RDD utilizando la función getNumPartitions()
xrangeRDD.getNumPartitions()
8
(3c): Restar uno de cada valor usando map#
Hasta ahora, hemos creado un conjunto de datos distribuidos que se divide en muchas particiones, donde cada partición se almacena en una sola máquina en nuestro clúster. Veamos qué sucede cuando realizamos una operación básica en el conjunto de datos. Muchas operaciones útiles de análisis de datos se pueden especificar como «hacer algo a cada elemento en el conjunto de datos». Estas operaciones paralelas de datos son convenientes porque cada elemento en el conjunto de datos se puede procesar individualmente: la operación en una entrada no afecta las operaciones en ninguna de las otras entradas. Por lo tanto, Spark puede paralelizar la operación.#
map(f), la transformación más común de Spark, es un ejemplo de esto: aplica una función f a cada elemento en el conjunto de datos y genera el conjunto de datos resultante. Cuando ejecutas map() en un conjunto de datos, se lanza una sola etapa de tareas. Una etapa es un grupo de tareas que realizan el mismo cálculo, pero con datos de entrada diferentes. Se lanza una tarea para cada partición, como se muestra en el ejemplo a continuación. Una tarea es una unidad de ejecución que se ejecuta en una sola máquina. Cuando ejecutamos map(f) dentro de una partición, una nueva tarea aplica f a todas las entradas en una partición en particular y genera una nueva partición. En este ejemplo, el conjunto de datos se divide en cuatro particiones, por lo que se lanzan cuatro tareas map().#
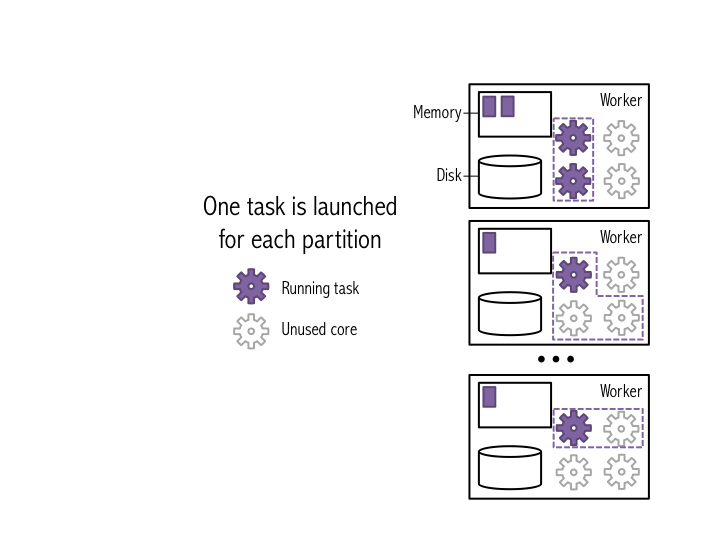
La figura a continuación muestra cómo funcionaría esto en el conjunto de datos más pequeño de las figuras anteriores. Ten en cuenta que se lanza una tarea para cada partición.#
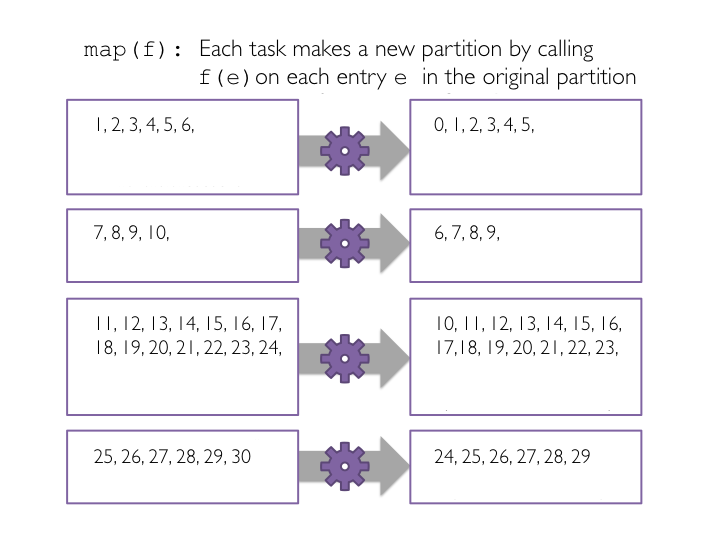
Al aplicar la transformación map(), cada elemento en el RDD principal se asignará a un elemento en el nuevo RDD. Entonces, si el RDD principal tiene veinte elementos, el nuevo RDD también tendrá veinte elementos.#
Ahora usaremos map() para restar uno de cada valor en el RDD base que acabamos de crear. Primero, definimos una función de Python llamada sub() que restará uno del entero de entrada. En segundo lugar, pasaremos cada elemento en el RDD base a una transformación map() que aplica la función sub() a cada elemento. Y finalmente, imprimimos la jerarquía de transformación del RDD usando toDebugString().#
# Crear subfunción para restar 1
def sub(value):
""""Subtracts one from `value`.
Args:
value (int): A number.
Returns:
int: `value` minus one.
"""
return (value - 1)
# Transformar xrangeRDD a través de la transformación map usando la subfunción
# Debido a que map es una transformación y Spark usa lazy evaluation, ningún job, stage,
# o tareas serán lanzadas cuando ejecutemos este código.
subRDD = xrangeRDD.map(sub)
# Veamos la jerarquía de transformación RDD
print(subRDD.toDebugString())
b'(8) PythonRDD[5] at RDD at PythonRDD.scala:53 []\n | ParallelCollectionRDD[0] at readRDDFromFile at PythonRDD.scala:289 []'
(3d) Realizar la acción collect para ver los resultados#
El método collect() es la primera operación de acción que hemos encontrado. Las operaciones de acción hacen que Spark realice las operaciones de transformación (perezosa) necesarias para calcular el RDD devuelto por la acción. En nuestro ejemplo, esto significa que ahora se lanzarán tareas para realizar las operaciones de parallelize, map y collect.#
En este ejemplo, el conjunto de datos se divide en cuatro particiones, por lo que se lanzan cuatro tareas collect(). Cada tarea recoge las entradas en su partición y envía el resultado al SparkContext, que crea una lista de los valores, como se muestra en la figura a continuación.#
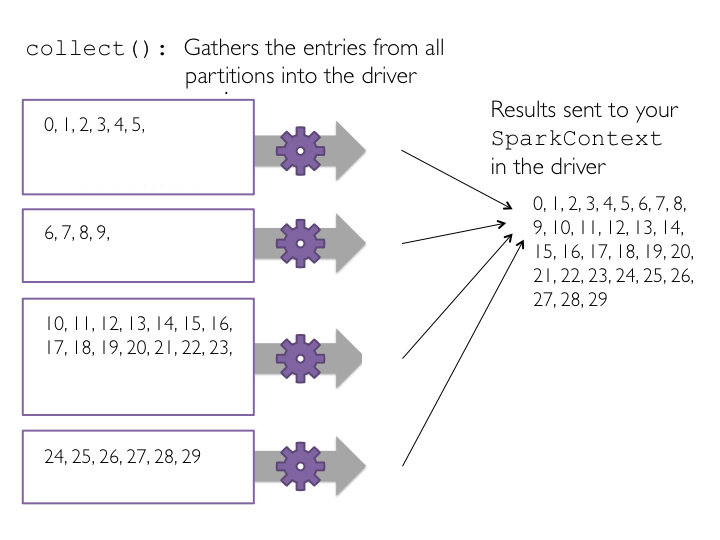
Las figuras anteriores mostraban lo que sucedería si ejecutáramos collect() en un conjunto de datos de ejemplo pequeño con solo cuatro particiones.#
Ahora ejecutemos collect() en subRDD.#
# Recojamos los datos
print(subRDD.collect())
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 100, 101, 102, 103, 104, 105, 106, 107, 108, 109, 110, 111, 112, 113, 114, 115, 116, 117, 118, 119, 120, 121, 122, 123, 124, 125, 126, 127, 128, 129, 130, 131, 132, 133, 134, 135, 136, 137, 138, 139, 140, 141, 142, 143, 144, 145, 146, 147, 148, 149, 150, 151, 152, 153, 154, 155, 156, 157, 158, 159, 160, 161, 162, 163, 164, 165, 166, 167, 168, 169, 170, 171, 172, 173, 174, 175, 176, 177, 178, 179, 180, 181, 182, 183, 184, 185, 186, 187, 188, 189, 190, 191, 192, 193, 194, 195, 196, 197, 198, 199, 200, 201, 202, 203, 204, 205, 206, 207, 208, 209, 210, 211, 212, 213, 214, 215, 216, 217, 218, 219, 220, 221, 222, 223, 224, 225, 226, 227, 228, 229, 230, 231, 232, 233, 234, 235, 236, 237, 238, 239, 240, 241, 242, 243, 244, 245, 246, 247, 248, 249, 250, 251, 252, 253, 254, 255, 256, 257, 258, 259, 260, 261, 262, 263, 264, 265, 266, 267, 268, 269, 270, 271, 272, 273, 274, 275, 276, 277, 278, 279, 280, 281, 282, 283, 284, 285, 286, 287, 288, 289, 290, 291, 292, 293, 294, 295, 296, 297, 298, 299, 300, 301, 302, 303, 304, 305, 306, 307, 308, 309, 310, 311, 312, 313, 314, 315, 316, 317, 318, 319, 320, 321, 322, 323, 324, 325, 326, 327, 328, 329, 330, 331, 332, 333, 334, 335, 336, 337, 338, 339, 340, 341, 342, 343, 344, 345, 346, 347, 348, 349, 350, 351, 352, 353, 354, 355, 356, 357, 358, 359, 360, 361, 362, 363, 364, 365, 366, 367, 368, 369, 370, 371, 372, 373, 374, 375, 376, 377, 378, 379, 380, 381, 382, 383, 384, 385, 386, 387, 388, 389, 390, 391, 392, 393, 394, 395, 396, 397, 398, 399, 400, 401, 402, 403, 404, 405, 406, 407, 408, 409, 410, 411, 412, 413, 414, 415, 416, 417, 418, 419, 420, 421, 422, 423, 424, 425, 426, 427, 428, 429, 430, 431, 432, 433, 434, 435, 436, 437, 438, 439, 440, 441, 442, 443, 444, 445, 446, 447, 448, 449, 450, 451, 452, 453, 454, 455, 456, 457, 458, 459, 460, 461, 462, 463, 464, 465, 466, 467, 468, 469, 470, 471, 472, 473, 474, 475, 476, 477, 478, 479, 480, 481, 482, 483, 484, 485, 486, 487, 488, 489, 490, 491, 492, 493, 494, 495, 496, 497, 498, 499, 500, 501, 502, 503, 504, 505, 506, 507, 508, 509, 510, 511, 512, 513, 514, 515, 516, 517, 518, 519, 520, 521, 522, 523, 524, 525, 526, 527, 528, 529, 530, 531, 532, 533, 534, 535, 536, 537, 538, 539, 540, 541, 542, 543, 544, 545, 546, 547, 548, 549, 550, 551, 552, 553, 554, 555, 556, 557, 558, 559, 560, 561, 562, 563, 564, 565, 566, 567, 568, 569, 570, 571, 572, 573, 574, 575, 576, 577, 578, 579, 580, 581, 582, 583, 584, 585, 586, 587, 588, 589, 590, 591, 592, 593, 594, 595, 596, 597, 598, 599, 600, 601, 602, 603, 604, 605, 606, 607, 608, 609, 610, 611, 612, 613, 614, 615, 616, 617, 618, 619, 620, 621, 622, 623, 624, 625, 626, 627, 628, 629, 630, 631, 632, 633, 634, 635, 636, 637, 638, 639, 640, 641, 642, 643, 644, 645, 646, 647, 648, 649, 650, 651, 652, 653, 654, 655, 656, 657, 658, 659, 660, 661, 662, 663, 664, 665, 666, 667, 668, 669, 670, 671, 672, 673, 674, 675, 676, 677, 678, 679, 680, 681, 682, 683, 684, 685, 686, 687, 688, 689, 690, 691, 692, 693, 694, 695, 696, 697, 698, 699, 700, 701, 702, 703, 704, 705, 706, 707, 708, 709, 710, 711, 712, 713, 714, 715, 716, 717, 718, 719, 720, 721, 722, 723, 724, 725, 726, 727, 728, 729, 730, 731, 732, 733, 734, 735, 736, 737, 738, 739, 740, 741, 742, 743, 744, 745, 746, 747, 748, 749, 750, 751, 752, 753, 754, 755, 756, 757, 758, 759, 760, 761, 762, 763, 764, 765, 766, 767, 768, 769, 770, 771, 772, 773, 774, 775, 776, 777, 778, 779, 780, 781, 782, 783, 784, 785, 786, 787, 788, 789, 790, 791, 792, 793, 794, 795, 796, 797, 798, 799, 800, 801, 802, 803, 804, 805, 806, 807, 808, 809, 810, 811, 812, 813, 814, 815, 816, 817, 818, 819, 820, 821, 822, 823, 824, 825, 826, 827, 828, 829, 830, 831, 832, 833, 834, 835, 836, 837, 838, 839, 840, 841, 842, 843, 844, 845, 846, 847, 848, 849, 850, 851, 852, 853, 854, 855, 856, 857, 858, 859, 860, 861, 862, 863, 864, 865, 866, 867, 868, 869, 870, 871, 872, 873, 874, 875, 876, 877, 878, 879, 880, 881, 882, 883, 884, 885, 886, 887, 888, 889, 890, 891, 892, 893, 894, 895, 896, 897, 898, 899, 900, 901, 902, 903, 904, 905, 906, 907, 908, 909, 910, 911, 912, 913, 914, 915, 916, 917, 918, 919, 920, 921, 922, 923, 924, 925, 926, 927, 928, 929, 930, 931, 932, 933, 934, 935, 936, 937, 938, 939, 940, 941, 942, 943, 944, 945, 946, 947, 948, 949, 950, 951, 952, 953, 954, 955, 956, 957, 958, 959, 960, 961, 962, 963, 964, 965, 966, 967, 968, 969, 970, 971, 972, 973, 974, 975, 976, 977, 978, 979, 980, 981, 982, 983, 984, 985, 986, 987, 988, 989, 990, 991, 992, 993, 994, 995, 996, 997, 998, 999, 1000, 1001, 1002, 1003, 1004, 1005, 1006, 1007, 1008, 1009, 1010, 1011, 1012, 1013, 1014, 1015, 1016, 1017, 1018, 1019, 1020, 1021, 1022, 1023, 1024, 1025, 1026, 1027, 1028, 1029, 1030, 1031, 1032, 1033, 1034, 1035, 1036, 1037, 1038, 1039, 1040, 1041, 1042, 1043, 1044, 1045, 1046, 1047, 1048, 1049, 1050, 1051, 1052, 1053, 1054, 1055, 1056, 1057, 1058, 1059, 1060, 1061, 1062, 1063, 1064, 1065, 1066, 1067, 1068, 1069, 1070, 1071, 1072, 1073, 1074, 1075, 1076, 1077, 1078, 1079, 1080, 1081, 1082, 1083, 1084, 1085, 1086, 1087, 1088, 1089, 1090, 1091, 1092, 1093, 1094, 1095, 1096, 1097, 1098, 1099, 1100, 1101, 1102, 1103, 1104, 1105, 1106, 1107, 1108, 1109, 1110, 1111, 1112, 1113, 1114, 1115, 1116, 1117, 1118, 1119, 1120, 1121, 1122, 1123, 1124, 1125, 1126, 1127, 1128, 1129, 1130, 1131, 1132, 1133, 1134, 1135, 1136, 1137, 1138, 1139, 1140, 1141, 1142, 1143, 1144, 1145, 1146, 1147, 1148, 1149, 1150, 1151, 1152, 1153, 1154, 1155, 1156, 1157, 1158, 1159, 1160, 1161, 1162, 1163, 1164, 1165, 1166, 1167, 1168, 1169, 1170, 1171, 1172, 1173, 1174, 1175, 1176, 1177, 1178, 1179, 1180, 1181, 1182, 1183, 1184, 1185, 1186, 1187, 1188, 1189, 1190, 1191, 1192, 1193, 1194, 1195, 1196, 1197, 1198, 1199, 1200, 1201, 1202, 1203, 1204, 1205, 1206, 1207, 1208, 1209, 1210, 1211, 1212, 1213, 1214, 1215, 1216, 1217, 1218, 1219, 1220, 1221, 1222, 1223, 1224, 1225, 1226, 1227, 1228, 1229, 1230, 1231, 1232, 1233, 1234, 1235, 1236, 1237, 1238, 1239, 1240, 1241, 1242, 1243, 1244, 1245, 1246, 1247, 1248, 1249, 1250, 1251, 1252, 1253, 1254, 1255, 1256, 1257, 1258, 1259, 1260, 1261, 1262, 1263, 1264, 1265, 1266, 1267, 1268, 1269, 1270, 1271, 1272, 1273, 1274, 1275, 1276, 1277, 1278, 1279, 1280, 1281, 1282, 1283, 1284, 1285, 1286, 1287, 1288, 1289, 1290, 1291, 1292, 1293, 1294, 1295, 1296, 1297, 1298, 1299, 1300, 1301, 1302, 1303, 1304, 1305, 1306, 1307, 1308, 1309, 1310, 1311, 1312, 1313, 1314, 1315, 1316, 1317, 1318, 1319, 1320, 1321, 1322, 1323, 1324, 1325, 1326, 1327, 1328, 1329, 1330, 1331, 1332, 1333, 1334, 1335, 1336, 1337, 1338, 1339, 1340, 1341, 1342, 1343, 1344, 1345, 1346, 1347, 1348, 1349, 1350, 1351, 1352, 1353, 1354, 1355, 1356, 1357, 1358, 1359, 1360, 1361, 1362, 1363, 1364, 1365, 1366, 1367, 1368, 1369, 1370, 1371, 1372, 1373, 1374, 1375, 1376, 1377, 1378, 1379, 1380, 1381, 1382, 1383, 1384, 1385, 1386, 1387, 1388, 1389, 1390, 1391, 1392, 1393, 1394, 1395, 1396, 1397, 1398, 1399, 1400, 1401, 1402, 1403, 1404, 1405, 1406, 1407, 1408, 1409, 1410, 1411, 1412, 1413, 1414, 1415, 1416, 1417, 1418, 1419, 1420, 1421, 1422, 1423, 1424, 1425, 1426, 1427, 1428, 1429, 1430, 1431, 1432, 1433, 1434, 1435, 1436, 1437, 1438, 1439, 1440, 1441, 1442, 1443, 1444, 1445, 1446, 1447, 1448, 1449, 1450, 1451, 1452, 1453, 1454, 1455, 1456, 1457, 1458, 1459, 1460, 1461, 1462, 1463, 1464, 1465, 1466, 1467, 1468, 1469, 1470, 1471, 1472, 1473, 1474, 1475, 1476, 1477, 1478, 1479, 1480, 1481, 1482, 1483, 1484, 1485, 1486, 1487, 1488, 1489, 1490, 1491, 1492, 1493, 1494, 1495, 1496, 1497, 1498, 1499, 1500, 1501, 1502, 1503, 1504, 1505, 1506, 1507, 1508, 1509, 1510, 1511, 1512, 1513, 1514, 1515, 1516, 1517, 1518, 1519, 1520, 1521, 1522, 1523, 1524, 1525, 1526, 1527, 1528, 1529, 1530, 1531, 1532, 1533, 1534, 1535, 1536, 1537, 1538, 1539, 1540, 1541, 1542, 1543, 1544, 1545, 1546, 1547, 1548, 1549, 1550, 1551, 1552, 1553, 1554, 1555, 1556, 1557, 1558, 1559, 1560, 1561, 1562, 1563, 1564, 1565, 1566, 1567, 1568, 1569, 1570, 1571, 1572, 1573, 1574, 1575, 1576, 1577, 1578, 1579, 1580, 1581, 1582, 1583, 1584, 1585, 1586, 1587, 1588, 1589, 1590, 1591, 1592, 1593, 1594, 1595, 1596, 1597, 1598, 1599, 1600, 1601, 1602, 1603, 1604, 1605, 1606, 1607, 1608, 1609, 1610, 1611, 1612, 1613, 1614, 1615, 1616, 1617, 1618, 1619, 1620, 1621, 1622, 1623, 1624, 1625, 1626, 1627, 1628, 1629, 1630, 1631, 1632, 1633, 1634, 1635, 1636, 1637, 1638, 1639, 1640, 1641, 1642, 1643, 1644, 1645, 1646, 1647, 1648, 1649, 1650, 1651, 1652, 1653, 1654, 1655, 1656, 1657, 1658, 1659, 1660, 1661, 1662, 1663, 1664, 1665, 1666, 1667, 1668, 1669, 1670, 1671, 1672, 1673, 1674, 1675, 1676, 1677, 1678, 1679, 1680, 1681, 1682, 1683, 1684, 1685, 1686, 1687, 1688, 1689, 1690, 1691, 1692, 1693, 1694, 1695, 1696, 1697, 1698, 1699, 1700, 1701, 1702, 1703, 1704, 1705, 1706, 1707, 1708, 1709, 1710, 1711, 1712, 1713, 1714, 1715, 1716, 1717, 1718, 1719, 1720, 1721, 1722, 1723, 1724, 1725, 1726, 1727, 1728, 1729, 1730, 1731, 1732, 1733, 1734, 1735, 1736, 1737, 1738, 1739, 1740, 1741, 1742, 1743, 1744, 1745, 1746, 1747, 1748, 1749, 1750, 1751, 1752, 1753, 1754, 1755, 1756, 1757, 1758, 1759, 1760, 1761, 1762, 1763, 1764, 1765, 1766, 1767, 1768, 1769, 1770, 1771, 1772, 1773, 1774, 1775, 1776, 1777, 1778, 1779, 1780, 1781, 1782, 1783, 1784, 1785, 1786, 1787, 1788, 1789, 1790, 1791, 1792, 1793, 1794, 1795, 1796, 1797, 1798, 1799, 1800, 1801, 1802, 1803, 1804, 1805, 1806, 1807, 1808, 1809, 1810, 1811, 1812, 1813, 1814, 1815, 1816, 1817, 1818, 1819, 1820, 1821, 1822, 1823, 1824, 1825, 1826, 1827, 1828, 1829, 1830, 1831, 1832, 1833, 1834, 1835, 1836, 1837, 1838, 1839, 1840, 1841, 1842, 1843, 1844, 1845, 1846, 1847, 1848, 1849, 1850, 1851, 1852, 1853, 1854, 1855, 1856, 1857, 1858, 1859, 1860, 1861, 1862, 1863, 1864, 1865, 1866, 1867, 1868, 1869, 1870, 1871, 1872, 1873, 1874, 1875, 1876, 1877, 1878, 1879, 1880, 1881, 1882, 1883, 1884, 1885, 1886, 1887, 1888, 1889, 1890, 1891, 1892, 1893, 1894, 1895, 1896, 1897, 1898, 1899, 1900, 1901, 1902, 1903, 1904, 1905, 1906, 1907, 1908, 1909, 1910, 1911, 1912, 1913, 1914, 1915, 1916, 1917, 1918, 1919, 1920, 1921, 1922, 1923, 1924, 1925, 1926, 1927, 1928, 1929, 1930, 1931, 1932, 1933, 1934, 1935, 1936, 1937, 1938, 1939, 1940, 1941, 1942, 1943, 1944, 1945, 1946, 1947, 1948, 1949, 1950, 1951, 1952, 1953, 1954, 1955, 1956, 1957, 1958, 1959, 1960, 1961, 1962, 1963, 1964, 1965, 1966, 1967, 1968, 1969, 1970, 1971, 1972, 1973, 1974, 1975, 1976, 1977, 1978, 1979, 1980, 1981, 1982, 1983, 1984, 1985, 1986, 1987, 1988, 1989, 1990, 1991, 1992, 1993, 1994, 1995, 1996, 1997, 1998, 1999, 2000, 2001, 2002, 2003, 2004, 2005, 2006, 2007, 2008, 2009, 2010, 2011, 2012, 2013, 2014, 2015, 2016, 2017, 2018, 2019, 2020, 2021, 2022, 2023, 2024, 2025, 2026, 2027, 2028, 2029, 2030, 2031, 2032, 2033, 2034, 2035, 2036, 2037, 2038, 2039, 2040, 2041, 2042, 2043, 2044, 2045, 2046, 2047, 2048, 2049, 2050, 2051, 2052, 2053, 2054, 2055, 2056, 2057, 2058, 2059, 2060, 2061, 2062, 2063, 2064, 2065, 2066, 2067, 2068, 2069, 2070, 2071, 2072, 2073, 2074, 2075, 2076, 2077, 2078, 2079, 2080, 2081, 2082, 2083, 2084, 2085, 2086, 2087, 2088, 2089, 2090, 2091, 2092, 2093, 2094, 2095, 2096, 2097, 2098, 2099, 2100, 2101, 2102, 2103, 2104, 2105, 2106, 2107, 2108, 2109, 2110, 2111, 2112, 2113, 2114, 2115, 2116, 2117, 2118, 2119, 2120, 2121, 2122, 2123, 2124, 2125, 2126, 2127, 2128, 2129, 2130, 2131, 2132, 2133, 2134, 2135, 2136, 2137, 2138, 2139, 2140, 2141, 2142, 2143, 2144, 2145, 2146, 2147, 2148, 2149, 2150, 2151, 2152, 2153, 2154, 2155, 2156, 2157, 2158, 2159, 2160, 2161, 2162, 2163, 2164, 2165, 2166, 2167, 2168, 2169, 2170, 2171, 2172, 2173, 2174, 2175, 2176, 2177, 2178, 2179, 2180, 2181, 2182, 2183, 2184, 2185, 2186, 2187, 2188, 2189, 2190, 2191, 2192, 2193, 2194, 2195, 2196, 2197, 2198, 2199, 2200, 2201, 2202, 2203, 2204, 2205, 2206, 2207, 2208, 2209, 2210, 2211, 2212, 2213, 2214, 2215, 2216, 2217, 2218, 2219, 2220, 2221, 2222, 2223, 2224, 2225, 2226, 2227, 2228, 2229, 2230, 2231, 2232, 2233, 2234, 2235, 2236, 2237, 2238, 2239, 2240, 2241, 2242, 2243, 2244, 2245, 2246, 2247, 2248, 2249, 2250, 2251, 2252, 2253, 2254, 2255, 2256, 2257, 2258, 2259, 2260, 2261, 2262, 2263, 2264, 2265, 2266, 2267, 2268, 2269, 2270, 2271, 2272, 2273, 2274, 2275, 2276, 2277, 2278, 2279, 2280, 2281, 2282, 2283, 2284, 2285, 2286, 2287, 2288, 2289, 2290, 2291, 2292, 2293, 2294, 2295, 2296, 2297, 2298, 2299, 2300, 2301, 2302, 2303, 2304, 2305, 2306, 2307, 2308, 2309, 2310, 2311, 2312, 2313, 2314, 2315, 2316, 2317, 2318, 2319, 2320, 2321, 2322, 2323, 2324, 2325, 2326, 2327, 2328, 2329, 2330, 2331, 2332, 2333, 2334, 2335, 2336, 2337, 2338, 2339, 2340, 2341, 2342, 2343, 2344, 2345, 2346, 2347, 2348, 2349, 2350, 2351, 2352, 2353, 2354, 2355, 2356, 2357, 2358, 2359, 2360, 2361, 2362, 2363, 2364, 2365, 2366, 2367, 2368, 2369, 2370, 2371, 2372, 2373, 2374, 2375, 2376, 2377, 2378, 2379, 2380, 2381, 2382, 2383, 2384, 2385, 2386, 2387, 2388, 2389, 2390, 2391, 2392, 2393, 2394, 2395, 2396, 2397, 2398, 2399, 2400, 2401, 2402, 2403, 2404, 2405, 2406, 2407, 2408, 2409, 2410, 2411, 2412, 2413, 2414, 2415, 2416, 2417, 2418, 2419, 2420, 2421, 2422, 2423, 2424, 2425, 2426, 2427, 2428, 2429, 2430, 2431, 2432, 2433, 2434, 2435, 2436, 2437, 2438, 2439, 2440, 2441, 2442, 2443, 2444, 2445, 2446, 2447, 2448, 2449, 2450, 2451, 2452, 2453, 2454, 2455, 2456, 2457, 2458, 2459, 2460, 2461, 2462, 2463, 2464, 2465, 2466, 2467, 2468, 2469, 2470, 2471, 2472, 2473, 2474, 2475, 2476, 2477, 2478, 2479, 2480, 2481, 2482, 2483, 2484, 2485, 2486, 2487, 2488, 2489, 2490, 2491, 2492, 2493, 2494, 2495, 2496, 2497, 2498, 2499, 2500, 2501, 2502, 2503, 2504, 2505, 2506, 2507, 2508, 2509, 2510, 2511, 2512, 2513, 2514, 2515, 2516, 2517, 2518, 2519, 2520, 2521, 2522, 2523, 2524, 2525, 2526, 2527, 2528, 2529, 2530, 2531, 2532, 2533, 2534, 2535, 2536, 2537, 2538, 2539, 2540, 2541, 2542, 2543, 2544, 2545, 2546, 2547, 2548, 2549, 2550, 2551, 2552, 2553, 2554, 2555, 2556, 2557, 2558, 2559, 2560, 2561, 2562, 2563, 2564, 2565, 2566, 2567, 2568, 2569, 2570, 2571, 2572, 2573, 2574, 2575, 2576, 2577, 2578, 2579, 2580, 2581, 2582, 2583, 2584, 2585, 2586, 2587, 2588, 2589, 2590, 2591, 2592, 2593, 2594, 2595, 2596, 2597, 2598, 2599, 2600, 2601, 2602, 2603, 2604, 2605, 2606, 2607, 2608, 2609, 2610, 2611, 2612, 2613, 2614, 2615, 2616, 2617, 2618, 2619, 2620, 2621, 2622, 2623, 2624, 2625, 2626, 2627, 2628, 2629, 2630, 2631, 2632, 2633, 2634, 2635, 2636, 2637, 2638, 2639, 2640, 2641, 2642, 2643, 2644, 2645, 2646, 2647, 2648, 2649, 2650, 2651, 2652, 2653, 2654, 2655, 2656, 2657, 2658, 2659, 2660, 2661, 2662, 2663, 2664, 2665, 2666, 2667, 2668, 2669, 2670, 2671, 2672, 2673, 2674, 2675, 2676, 2677, 2678, 2679, 2680, 2681, 2682, 2683, 2684, 2685, 2686, 2687, 2688, 2689, 2690, 2691, 2692, 2693, 2694, 2695, 2696, 2697, 2698, 2699, 2700, 2701, 2702, 2703, 2704, 2705, 2706, 2707, 2708, 2709, 2710, 2711, 2712, 2713, 2714, 2715, 2716, 2717, 2718, 2719, 2720, 2721, 2722, 2723, 2724, 2725, 2726, 2727, 2728, 2729, 2730, 2731, 2732, 2733, 2734, 2735, 2736, 2737, 2738, 2739, 2740, 2741, 2742, 2743, 2744, 2745, 2746, 2747, 2748, 2749, 2750, 2751, 2752, 2753, 2754, 2755, 2756, 2757, 2758, 2759, 2760, 2761, 2762, 2763, 2764, 2765, 2766, 2767, 2768, 2769, 2770, 2771, 2772, 2773, 2774, 2775, 2776, 2777, 2778, 2779, 2780, 2781, 2782, 2783, 2784, 2785, 2786, 2787, 2788, 2789, 2790, 2791, 2792, 2793, 2794, 2795, 2796, 2797, 2798, 2799, 2800, 2801, 2802, 2803, 2804, 2805, 2806, 2807, 2808, 2809, 2810, 2811, 2812, 2813, 2814, 2815, 2816, 2817, 2818, 2819, 2820, 2821, 2822, 2823, 2824, 2825, 2826, 2827, 2828, 2829, 2830, 2831, 2832, 2833, 2834, 2835, 2836, 2837, 2838, 2839, 2840, 2841, 2842, 2843, 2844, 2845, 2846, 2847, 2848, 2849, 2850, 2851, 2852, 2853, 2854, 2855, 2856, 2857, 2858, 2859, 2860, 2861, 2862, 2863, 2864, 2865, 2866, 2867, 2868, 2869, 2870, 2871, 2872, 2873, 2874, 2875, 2876, 2877, 2878, 2879, 2880, 2881, 2882, 2883, 2884, 2885, 2886, 2887, 2888, 2889, 2890, 2891, 2892, 2893, 2894, 2895, 2896, 2897, 2898, 2899, 2900, 2901, 2902, 2903, 2904, 2905, 2906, 2907, 2908, 2909, 2910, 2911, 2912, 2913, 2914, 2915, 2916, 2917, 2918, 2919, 2920, 2921, 2922, 2923, 2924, 2925, 2926, 2927, 2928, 2929, 2930, 2931, 2932, 2933, 2934, 2935, 2936, 2937, 2938, 2939, 2940, 2941, 2942, 2943, 2944, 2945, 2946, 2947, 2948, 2949, 2950, 2951, 2952, 2953, 2954, 2955, 2956, 2957, 2958, 2959, 2960, 2961, 2962, 2963, 2964, 2965, 2966, 2967, 2968, 2969, 2970, 2971, 2972, 2973, 2974, 2975, 2976, 2977, 2978, 2979, 2980, 2981, 2982, 2983, 2984, 2985, 2986, 2987, 2988, 2989, 2990, 2991, 2992, 2993, 2994, 2995, 2996, 2997, 2998, 2999, 3000, 3001, 3002, 3003, 3004, 3005, 3006, 3007, 3008, 3009, 3010, 3011, 3012, 3013, 3014, 3015, 3016, 3017, 3018, 3019, 3020, 3021, 3022, 3023, 3024, 3025, 3026, 3027, 3028, 3029, 3030, 3031, 3032, 3033, 3034, 3035, 3036, 3037, 3038, 3039, 3040, 3041, 3042, 3043, 3044, 3045, 3046, 3047, 3048, 3049, 3050, 3051, 3052, 3053, 3054, 3055, 3056, 3057, 3058, 3059, 3060, 3061, 3062, 3063, 3064, 3065, 3066, 3067, 3068, 3069, 3070, 3071, 3072, 3073, 3074, 3075, 3076, 3077, 3078, 3079, 3080, 3081, 3082, 3083, 3084, 3085, 3086, 3087, 3088, 3089, 3090, 3091, 3092, 3093, 3094, 3095, 3096, 3097, 3098, 3099, 3100, 3101, 3102, 3103, 3104, 3105, 3106, 3107, 3108, 3109, 3110, 3111, 3112, 3113, 3114, 3115, 3116, 3117, 3118, 3119, 3120, 3121, 3122, 3123, 3124, 3125, 3126, 3127, 3128, 3129, 3130, 3131, 3132, 3133, 3134, 3135, 3136, 3137, 3138, 3139, 3140, 3141, 3142, 3143, 3144, 3145, 3146, 3147, 3148, 3149, 3150, 3151, 3152, 3153, 3154, 3155, 3156, 3157, 3158, 3159, 3160, 3161, 3162, 3163, 3164, 3165, 3166, 3167, 3168, 3169, 3170, 3171, 3172, 3173, 3174, 3175, 3176, 3177, 3178, 3179, 3180, 3181, 3182, 3183, 3184, 3185, 3186, 3187, 3188, 3189, 3190, 3191, 3192, 3193, 3194, 3195, 3196, 3197, 3198, 3199, 3200, 3201, 3202, 3203, 3204, 3205, 3206, 3207, 3208, 3209, 3210, 3211, 3212, 3213, 3214, 3215, 3216, 3217, 3218, 3219, 3220, 3221, 3222, 3223, 3224, 3225, 3226, 3227, 3228, 3229, 3230, 3231, 3232, 3233, 3234, 3235, 3236, 3237, 3238, 3239, 3240, 3241, 3242, 3243, 3244, 3245, 3246, 3247, 3248, 3249, 3250, 3251, 3252, 3253, 3254, 3255, 3256, 3257, 3258, 3259, 3260, 3261, 3262, 3263, 3264, 3265, 3266, 3267, 3268, 3269, 3270, 3271, 3272, 3273, 3274, 3275, 3276, 3277, 3278, 3279, 3280, 3281, 3282, 3283, 3284, 3285, 3286, 3287, 3288, 3289, 3290, 3291, 3292, 3293, 3294, 3295, 3296, 3297, 3298, 3299, 3300, 3301, 3302, 3303, 3304, 3305, 3306, 3307, 3308, 3309, 3310, 3311, 3312, 3313, 3314, 3315, 3316, 3317, 3318, 3319, 3320, 3321, 3322, 3323, 3324, 3325, 3326, 3327, 3328, 3329, 3330, 3331, 3332, 3333, 3334, 3335, 3336, 3337, 3338, 3339, 3340, 3341, 3342, 3343, 3344, 3345, 3346, 3347, 3348, 3349, 3350, 3351, 3352, 3353, 3354, 3355, 3356, 3357, 3358, 3359, 3360, 3361, 3362, 3363, 3364, 3365, 3366, 3367, 3368, 3369, 3370, 3371, 3372, 3373, 3374, 3375, 3376, 3377, 3378, 3379, 3380, 3381, 3382, 3383, 3384, 3385, 3386, 3387, 3388, 3389, 3390, 3391, 3392, 3393, 3394, 3395, 3396, 3397, 3398, 3399, 3400, 3401, 3402, 3403, 3404, 3405, 3406, 3407, 3408, 3409, 3410, 3411, 3412, 3413, 3414, 3415, 3416, 3417, 3418, 3419, 3420, 3421, 3422, 3423, 3424, 3425, 3426, 3427, 3428, 3429, 3430, 3431, 3432, 3433, 3434, 3435, 3436, 3437, 3438, 3439, 3440, 3441, 3442, 3443, 3444, 3445, 3446, 3447, 3448, 3449, 3450, 3451, 3452, 3453, 3454, 3455, 3456, 3457, 3458, 3459, 3460, 3461, 3462, 3463, 3464, 3465, 3466, 3467, 3468, 3469, 3470, 3471, 3472, 3473, 3474, 3475, 3476, 3477, 3478, 3479, 3480, 3481, 3482, 3483, 3484, 3485, 3486, 3487, 3488, 3489, 3490, 3491, 3492, 3493, 3494, 3495, 3496, 3497, 3498, 3499, 3500, 3501, 3502, 3503, 3504, 3505, 3506, 3507, 3508, 3509, 3510, 3511, 3512, 3513, 3514, 3515, 3516, 3517, 3518, 3519, 3520, 3521, 3522, 3523, 3524, 3525, 3526, 3527, 3528, 3529, 3530, 3531, 3532, 3533, 3534, 3535, 3536, 3537, 3538, 3539, 3540, 3541, 3542, 3543, 3544, 3545, 3546, 3547, 3548, 3549, 3550, 3551, 3552, 3553, 3554, 3555, 3556, 3557, 3558, 3559, 3560, 3561, 3562, 3563, 3564, 3565, 3566, 3567, 3568, 3569, 3570, 3571, 3572, 3573, 3574, 3575, 3576, 3577, 3578, 3579, 3580, 3581, 3582, 3583, 3584, 3585, 3586, 3587, 3588, 3589, 3590, 3591, 3592, 3593, 3594, 3595, 3596, 3597, 3598, 3599, 3600, 3601, 3602, 3603, 3604, 3605, 3606, 3607, 3608, 3609, 3610, 3611, 3612, 3613, 3614, 3615, 3616, 3617, 3618, 3619, 3620, 3621, 3622, 3623, 3624, 3625, 3626, 3627, 3628, 3629, 3630, 3631, 3632, 3633, 3634, 3635, 3636, 3637, 3638, 3639, 3640, 3641, 3642, 3643, 3644, 3645, 3646, 3647, 3648, 3649, 3650, 3651, 3652, 3653, 3654, 3655, 3656, 3657, 3658, 3659, 3660, 3661, 3662, 3663, 3664, 3665, 3666, 3667, 3668, 3669, 3670, 3671, 3672, 3673, 3674, 3675, 3676, 3677, 3678, 3679, 3680, 3681, 3682, 3683, 3684, 3685, 3686, 3687, 3688, 3689, 3690, 3691, 3692, 3693, 3694, 3695, 3696, 3697, 3698, 3699, 3700, 3701, 3702, 3703, 3704, 3705, 3706, 3707, 3708, 3709, 3710, 3711, 3712, 3713, 3714, 3715, 3716, 3717, 3718, 3719, 3720, 3721, 3722, 3723, 3724, 3725, 3726, 3727, 3728, 3729, 3730, 3731, 3732, 3733, 3734, 3735, 3736, 3737, 3738, 3739, 3740, 3741, 3742, 3743, 3744, 3745, 3746, 3747, 3748, 3749, 3750, 3751, 3752, 3753, 3754, 3755, 3756, 3757, 3758, 3759, 3760, 3761, 3762, 3763, 3764, 3765, 3766, 3767, 3768, 3769, 3770, 3771, 3772, 3773, 3774, 3775, 3776, 3777, 3778, 3779, 3780, 3781, 3782, 3783, 3784, 3785, 3786, 3787, 3788, 3789, 3790, 3791, 3792, 3793, 3794, 3795, 3796, 3797, 3798, 3799, 3800, 3801, 3802, 3803, 3804, 3805, 3806, 3807, 3808, 3809, 3810, 3811, 3812, 3813, 3814, 3815, 3816, 3817, 3818, 3819, 3820, 3821, 3822, 3823, 3824, 3825, 3826, 3827, 3828, 3829, 3830, 3831, 3832, 3833, 3834, 3835, 3836, 3837, 3838, 3839, 3840, 3841, 3842, 3843, 3844, 3845, 3846, 3847, 3848, 3849, 3850, 3851, 3852, 3853, 3854, 3855, 3856, 3857, 3858, 3859, 3860, 3861, 3862, 3863, 3864, 3865, 3866, 3867, 3868, 3869, 3870, 3871, 3872, 3873, 3874, 3875, 3876, 3877, 3878, 3879, 3880, 3881, 3882, 3883, 3884, 3885, 3886, 3887, 3888, 3889, 3890, 3891, 3892, 3893, 3894, 3895, 3896, 3897, 3898, 3899, 3900, 3901, 3902, 3903, 3904, 3905, 3906, 3907, 3908, 3909, 3910, 3911, 3912, 3913, 3914, 3915, 3916, 3917, 3918, 3919, 3920, 3921, 3922, 3923, 3924, 3925, 3926, 3927, 3928, 3929, 3930, 3931, 3932, 3933, 3934, 3935, 3936, 3937, 3938, 3939, 3940, 3941, 3942, 3943, 3944, 3945, 3946, 3947, 3948, 3949, 3950, 3951, 3952, 3953, 3954, 3955, 3956, 3957, 3958, 3959, 3960, 3961, 3962, 3963, 3964, 3965, 3966, 3967, 3968, 3969, 3970, 3971, 3972, 3973, 3974, 3975, 3976, 3977, 3978, 3979, 3980, 3981, 3982, 3983, 3984, 3985, 3986, 3987, 3988, 3989, 3990, 3991, 3992, 3993, 3994, 3995, 3996, 3997, 3998, 3999, 4000, 4001, 4002, 4003, 4004, 4005, 4006, 4007, 4008, 4009, 4010, 4011, 4012, 4013, 4014, 4015, 4016, 4017, 4018, 4019, 4020, 4021, 4022, 4023, 4024, 4025, 4026, 4027, 4028, 4029, 4030, 4031, 4032, 4033, 4034, 4035, 4036, 4037, 4038, 4039, 4040, 4041, 4042, 4043, 4044, 4045, 4046, 4047, 4048, 4049, 4050, 4051, 4052, 4053, 4054, 4055, 4056, 4057, 4058, 4059, 4060, 4061, 4062, 4063, 4064, 4065, 4066, 4067, 4068, 4069, 4070, 4071, 4072, 4073, 4074, 4075, 4076, 4077, 4078, 4079, 4080, 4081, 4082, 4083, 4084, 4085, 4086, 4087, 4088, 4089, 4090, 4091, 4092, 4093, 4094, 4095, 4096, 4097, 4098, 4099, 4100, 4101, 4102, 4103, 4104, 4105, 4106, 4107, 4108, 4109, 4110, 4111, 4112, 4113, 4114, 4115, 4116, 4117, 4118, 4119, 4120, 4121, 4122, 4123, 4124, 4125, 4126, 4127, 4128, 4129, 4130, 4131, 4132, 4133, 4134, 4135, 4136, 4137, 4138, 4139, 4140, 4141, 4142, 4143, 4144, 4145, 4146, 4147, 4148, 4149, 4150, 4151, 4152, 4153, 4154, 4155, 4156, 4157, 4158, 4159, 4160, 4161, 4162, 4163, 4164, 4165, 4166, 4167, 4168, 4169, 4170, 4171, 4172, 4173, 4174, 4175, 4176, 4177, 4178, 4179, 4180, 4181, 4182, 4183, 4184, 4185, 4186, 4187, 4188, 4189, 4190, 4191, 4192, 4193, 4194, 4195, 4196, 4197, 4198, 4199, 4200, 4201, 4202, 4203, 4204, 4205, 4206, 4207, 4208, 4209, 4210, 4211, 4212, 4213, 4214, 4215, 4216, 4217, 4218, 4219, 4220, 4221, 4222, 4223, 4224, 4225, 4226, 4227, 4228, 4229, 4230, 4231, 4232, 4233, 4234, 4235, 4236, 4237, 4238, 4239, 4240, 4241, 4242, 4243, 4244, 4245, 4246, 4247, 4248, 4249, 4250, 4251, 4252, 4253, 4254, 4255, 4256, 4257, 4258, 4259, 4260, 4261, 4262, 4263, 4264, 4265, 4266, 4267, 4268, 4269, 4270, 4271, 4272, 4273, 4274, 4275, 4276, 4277, 4278, 4279, 4280, 4281, 4282, 4283, 4284, 4285, 4286, 4287, 4288, 4289, 4290, 4291, 4292, 4293, 4294, 4295, 4296, 4297, 4298, 4299, 4300, 4301, 4302, 4303, 4304, 4305, 4306, 4307, 4308, 4309, 4310, 4311, 4312, 4313, 4314, 4315, 4316, 4317, 4318, 4319, 4320, 4321, 4322, 4323, 4324, 4325, 4326, 4327, 4328, 4329, 4330, 4331, 4332, 4333, 4334, 4335, 4336, 4337, 4338, 4339, 4340, 4341, 4342, 4343, 4344, 4345, 4346, 4347, 4348, 4349, 4350, 4351, 4352, 4353, 4354, 4355, 4356, 4357, 4358, 4359, 4360, 4361, 4362, 4363, 4364, 4365, 4366, 4367, 4368, 4369, 4370, 4371, 4372, 4373, 4374, 4375, 4376, 4377, 4378, 4379, 4380, 4381, 4382, 4383, 4384, 4385, 4386, 4387, 4388, 4389, 4390, 4391, 4392, 4393, 4394, 4395, 4396, 4397, 4398, 4399, 4400, 4401, 4402, 4403, 4404, 4405, 4406, 4407, 4408, 4409, 4410, 4411, 4412, 4413, 4414, 4415, 4416, 4417, 4418, 4419, 4420, 4421, 4422, 4423, 4424, 4425, 4426, 4427, 4428, 4429, 4430, 4431, 4432, 4433, 4434, 4435, 4436, 4437, 4438, 4439, 4440, 4441, 4442, 4443, 4444, 4445, 4446, 4447, 4448, 4449, 4450, 4451, 4452, 4453, 4454, 4455, 4456, 4457, 4458, 4459, 4460, 4461, 4462, 4463, 4464, 4465, 4466, 4467, 4468, 4469, 4470, 4471, 4472, 4473, 4474, 4475, 4476, 4477, 4478, 4479, 4480, 4481, 4482, 4483, 4484, 4485, 4486, 4487, 4488, 4489, 4490, 4491, 4492, 4493, 4494, 4495, 4496, 4497, 4498, 4499, 4500, 4501, 4502, 4503, 4504, 4505, 4506, 4507, 4508, 4509, 4510, 4511, 4512, 4513, 4514, 4515, 4516, 4517, 4518, 4519, 4520, 4521, 4522, 4523, 4524, 4525, 4526, 4527, 4528, 4529, 4530, 4531, 4532, 4533, 4534, 4535, 4536, 4537, 4538, 4539, 4540, 4541, 4542, 4543, 4544, 4545, 4546, 4547, 4548, 4549, 4550, 4551, 4552, 4553, 4554, 4555, 4556, 4557, 4558, 4559, 4560, 4561, 4562, 4563, 4564, 4565, 4566, 4567, 4568, 4569, 4570, 4571, 4572, 4573, 4574, 4575, 4576, 4577, 4578, 4579, 4580, 4581, 4582, 4583, 4584, 4585, 4586, 4587, 4588, 4589, 4590, 4591, 4592, 4593, 4594, 4595, 4596, 4597, 4598, 4599, 4600, 4601, 4602, 4603, 4604, 4605, 4606, 4607, 4608, 4609, 4610, 4611, 4612, 4613, 4614, 4615, 4616, 4617, 4618, 4619, 4620, 4621, 4622, 4623, 4624, 4625, 4626, 4627, 4628, 4629, 4630, 4631, 4632, 4633, 4634, 4635, 4636, 4637, 4638, 4639, 4640, 4641, 4642, 4643, 4644, 4645, 4646, 4647, 4648, 4649, 4650, 4651, 4652, 4653, 4654, 4655, 4656, 4657, 4658, 4659, 4660, 4661, 4662, 4663, 4664, 4665, 4666, 4667, 4668, 4669, 4670, 4671, 4672, 4673, 4674, 4675, 4676, 4677, 4678, 4679, 4680, 4681, 4682, 4683, 4684, 4685, 4686, 4687, 4688, 4689, 4690, 4691, 4692, 4693, 4694, 4695, 4696, 4697, 4698, 4699, 4700, 4701, 4702, 4703, 4704, 4705, 4706, 4707, 4708, 4709, 4710, 4711, 4712, 4713, 4714, 4715, 4716, 4717, 4718, 4719, 4720, 4721, 4722, 4723, 4724, 4725, 4726, 4727, 4728, 4729, 4730, 4731, 4732, 4733, 4734, 4735, 4736, 4737, 4738, 4739, 4740, 4741, 4742, 4743, 4744, 4745, 4746, 4747, 4748, 4749, 4750, 4751, 4752, 4753, 4754, 4755, 4756, 4757, 4758, 4759, 4760, 4761, 4762, 4763, 4764, 4765, 4766, 4767, 4768, 4769, 4770, 4771, 4772, 4773, 4774, 4775, 4776, 4777, 4778, 4779, 4780, 4781, 4782, 4783, 4784, 4785, 4786, 4787, 4788, 4789, 4790, 4791, 4792, 4793, 4794, 4795, 4796, 4797, 4798, 4799, 4800, 4801, 4802, 4803, 4804, 4805, 4806, 4807, 4808, 4809, 4810, 4811, 4812, 4813, 4814, 4815, 4816, 4817, 4818, 4819, 4820, 4821, 4822, 4823, 4824, 4825, 4826, 4827, 4828, 4829, 4830, 4831, 4832, 4833, 4834, 4835, 4836, 4837, 4838, 4839, 4840, 4841, 4842, 4843, 4844, 4845, 4846, 4847, 4848, 4849, 4850, 4851, 4852, 4853, 4854, 4855, 4856, 4857, 4858, 4859, 4860, 4861, 4862, 4863, 4864, 4865, 4866, 4867, 4868, 4869, 4870, 4871, 4872, 4873, 4874, 4875, 4876, 4877, 4878, 4879, 4880, 4881, 4882, 4883, 4884, 4885, 4886, 4887, 4888, 4889, 4890, 4891, 4892, 4893, 4894, 4895, 4896, 4897, 4898, 4899, 4900, 4901, 4902, 4903, 4904, 4905, 4906, 4907, 4908, 4909, 4910, 4911, 4912, 4913, 4914, 4915, 4916, 4917, 4918, 4919, 4920, 4921, 4922, 4923, 4924, 4925, 4926, 4927, 4928, 4929, 4930, 4931, 4932, 4933, 4934, 4935, 4936, 4937, 4938, 4939, 4940, 4941, 4942, 4943, 4944, 4945, 4946, 4947, 4948, 4949, 4950, 4951, 4952, 4953, 4954, 4955, 4956, 4957, 4958, 4959, 4960, 4961, 4962, 4963, 4964, 4965, 4966, 4967, 4968, 4969, 4970, 4971, 4972, 4973, 4974, 4975, 4976, 4977, 4978, 4979, 4980, 4981, 4982, 4983, 4984, 4985, 4986, 4987, 4988, 4989, 4990, 4991, 4992, 4993, 4994, 4995, 4996, 4997, 4998, 4999, 5000, 5001, 5002, 5003, 5004, 5005, 5006, 5007, 5008, 5009, 5010, 5011, 5012, 5013, 5014, 5015, 5016, 5017, 5018, 5019, 5020, 5021, 5022, 5023, 5024, 5025, 5026, 5027, 5028, 5029, 5030, 5031, 5032, 5033, 5034, 5035, 5036, 5037, 5038, 5039, 5040, 5041, 5042, 5043, 5044, 5045, 5046, 5047, 5048, 5049, 5050, 5051, 5052, 5053, 5054, 5055, 5056, 5057, 5058, 5059, 5060, 5061, 5062, 5063, 5064, 5065, 5066, 5067, 5068, 5069, 5070, 5071, 5072, 5073, 5074, 5075, 5076, 5077, 5078, 5079, 5080, 5081, 5082, 5083, 5084, 5085, 5086, 5087, 5088, 5089, 5090, 5091, 5092, 5093, 5094, 5095, 5096, 5097, 5098, 5099, 5100, 5101, 5102, 5103, 5104, 5105, 5106, 5107, 5108, 5109, 5110, 5111, 5112, 5113, 5114, 5115, 5116, 5117, 5118, 5119, 5120, 5121, 5122, 5123, 5124, 5125, 5126, 5127, 5128, 5129, 5130, 5131, 5132, 5133, 5134, 5135, 5136, 5137, 5138, 5139, 5140, 5141, 5142, 5143, 5144, 5145, 5146, 5147, 5148, 5149, 5150, 5151, 5152, 5153, 5154, 5155, 5156, 5157, 5158, 5159, 5160, 5161, 5162, 5163, 5164, 5165, 5166, 5167, 5168, 5169, 5170, 5171, 5172, 5173, 5174, 5175, 5176, 5177, 5178, 5179, 5180, 5181, 5182, 5183, 5184, 5185, 5186, 5187, 5188, 5189, 5190, 5191, 5192, 5193, 5194, 5195, 5196, 5197, 5198, 5199, 5200, 5201, 5202, 5203, 5204, 5205, 5206, 5207, 5208, 5209, 5210, 5211, 5212, 5213, 5214, 5215, 5216, 5217, 5218, 5219, 5220, 5221, 5222, 5223, 5224, 5225, 5226, 5227, 5228, 5229, 5230, 5231, 5232, 5233, 5234, 5235, 5236, 5237, 5238, 5239, 5240, 5241, 5242, 5243, 5244, 5245, 5246, 5247, 5248, 5249, 5250, 5251, 5252, 5253, 5254, 5255, 5256, 5257, 5258, 5259, 5260, 5261, 5262, 5263, 5264, 5265, 5266, 5267, 5268, 5269, 5270, 5271, 5272, 5273, 5274, 5275, 5276, 5277, 5278, 5279, 5280, 5281, 5282, 5283, 5284, 5285, 5286, 5287, 5288, 5289, 5290, 5291, 5292, 5293, 5294, 5295, 5296, 5297, 5298, 5299, 5300, 5301, 5302, 5303, 5304, 5305, 5306, 5307, 5308, 5309, 5310, 5311, 5312, 5313, 5314, 5315, 5316, 5317, 5318, 5319, 5320, 5321, 5322, 5323, 5324, 5325, 5326, 5327, 5328, 5329, 5330, 5331, 5332, 5333, 5334, 5335, 5336, 5337, 5338, 5339, 5340, 5341, 5342, 5343, 5344, 5345, 5346, 5347, 5348, 5349, 5350, 5351, 5352, 5353, 5354, 5355, 5356, 5357, 5358, 5359, 5360, 5361, 5362, 5363, 5364, 5365, 5366, 5367, 5368, 5369, 5370, 5371, 5372, 5373, 5374, 5375, 5376, 5377, 5378, 5379, 5380, 5381, 5382, 5383, 5384, 5385, 5386, 5387, 5388, 5389, 5390, 5391, 5392, 5393, 5394, 5395, 5396, 5397, 5398, 5399, 5400, 5401, 5402, 5403, 5404, 5405, 5406, 5407, 5408, 5409, 5410, 5411, 5412, 5413, 5414, 5415, 5416, 5417, 5418, 5419, 5420, 5421, 5422, 5423, 5424, 5425, 5426, 5427, 5428, 5429, 5430, 5431, 5432, 5433, 5434, 5435, 5436, 5437, 5438, 5439, 5440, 5441, 5442, 5443, 5444, 5445, 5446, 5447, 5448, 5449, 5450, 5451, 5452, 5453, 5454, 5455, 5456, 5457, 5458, 5459, 5460, 5461, 5462, 5463, 5464, 5465, 5466, 5467, 5468, 5469, 5470, 5471, 5472, 5473, 5474, 5475, 5476, 5477, 5478, 5479, 5480, 5481, 5482, 5483, 5484, 5485, 5486, 5487, 5488, 5489, 5490, 5491, 5492, 5493, 5494, 5495, 5496, 5497, 5498, 5499, 5500, 5501, 5502, 5503, 5504, 5505, 5506, 5507, 5508, 5509, 5510, 5511, 5512, 5513, 5514, 5515, 5516, 5517, 5518, 5519, 5520, 5521, 5522, 5523, 5524, 5525, 5526, 5527, 5528, 5529, 5530, 5531, 5532, 5533, 5534, 5535, 5536, 5537, 5538, 5539, 5540, 5541, 5542, 5543, 5544, 5545, 5546, 5547, 5548, 5549, 5550, 5551, 5552, 5553, 5554, 5555, 5556, 5557, 5558, 5559, 5560, 5561, 5562, 5563, 5564, 5565, 5566, 5567, 5568, 5569, 5570, 5571, 5572, 5573, 5574, 5575, 5576, 5577, 5578, 5579, 5580, 5581, 5582, 5583, 5584, 5585, 5586, 5587, 5588, 5589, 5590, 5591, 5592, 5593, 5594, 5595, 5596, 5597, 5598, 5599, 5600, 5601, 5602, 5603, 5604, 5605, 5606, 5607, 5608, 5609, 5610, 5611, 5612, 5613, 5614, 5615, 5616, 5617, 5618, 5619, 5620, 5621, 5622, 5623, 5624, 5625, 5626, 5627, 5628, 5629, 5630, 5631, 5632, 5633, 5634, 5635, 5636, 5637, 5638, 5639, 5640, 5641, 5642, 5643, 5644, 5645, 5646, 5647, 5648, 5649, 5650, 5651, 5652, 5653, 5654, 5655, 5656, 5657, 5658, 5659, 5660, 5661, 5662, 5663, 5664, 5665, 5666, 5667, 5668, 5669, 5670, 5671, 5672, 5673, 5674, 5675, 5676, 5677, 5678, 5679, 5680, 5681, 5682, 5683, 5684, 5685, 5686, 5687, 5688, 5689, 5690, 5691, 5692, 5693, 5694, 5695, 5696, 5697, 5698, 5699, 5700, 5701, 5702, 5703, 5704, 5705, 5706, 5707, 5708, 5709, 5710, 5711, 5712, 5713, 5714, 5715, 5716, 5717, 5718, 5719, 5720, 5721, 5722, 5723, 5724, 5725, 5726, 5727, 5728, 5729, 5730, 5731, 5732, 5733, 5734, 5735, 5736, 5737, 5738, 5739, 5740, 5741, 5742, 5743, 5744, 5745, 5746, 5747, 5748, 5749, 5750, 5751, 5752, 5753, 5754, 5755, 5756, 5757, 5758, 5759, 5760, 5761, 5762, 5763, 5764, 5765, 5766, 5767, 5768, 5769, 5770, 5771, 5772, 5773, 5774, 5775, 5776, 5777, 5778, 5779, 5780, 5781, 5782, 5783, 5784, 5785, 5786, 5787, 5788, 5789, 5790, 5791, 5792, 5793, 5794, 5795, 5796, 5797, 5798, 5799, 5800, 5801, 5802, 5803, 5804, 5805, 5806, 5807, 5808, 5809, 5810, 5811, 5812, 5813, 5814, 5815, 5816, 5817, 5818, 5819, 5820, 5821, 5822, 5823, 5824, 5825, 5826, 5827, 5828, 5829, 5830, 5831, 5832, 5833, 5834, 5835, 5836, 5837, 5838, 5839, 5840, 5841, 5842, 5843, 5844, 5845, 5846, 5847, 5848, 5849, 5850, 5851, 5852, 5853, 5854, 5855, 5856, 5857, 5858, 5859, 5860, 5861, 5862, 5863, 5864, 5865, 5866, 5867, 5868, 5869, 5870, 5871, 5872, 5873, 5874, 5875, 5876, 5877, 5878, 5879, 5880, 5881, 5882, 5883, 5884, 5885, 5886, 5887, 5888, 5889, 5890, 5891, 5892, 5893, 5894, 5895, 5896, 5897, 5898, 5899, 5900, 5901, 5902, 5903, 5904, 5905, 5906, 5907, 5908, 5909, 5910, 5911, 5912, 5913, 5914, 5915, 5916, 5917, 5918, 5919, 5920, 5921, 5922, 5923, 5924, 5925, 5926, 5927, 5928, 5929, 5930, 5931, 5932, 5933, 5934, 5935, 5936, 5937, 5938, 5939, 5940, 5941, 5942, 5943, 5944, 5945, 5946, 5947, 5948, 5949, 5950, 5951, 5952, 5953, 5954, 5955, 5956, 5957, 5958, 5959, 5960, 5961, 5962, 5963, 5964, 5965, 5966, 5967, 5968, 5969, 5970, 5971, 5972, 5973, 5974, 5975, 5976, 5977, 5978, 5979, 5980, 5981, 5982, 5983, 5984, 5985, 5986, 5987, 5988, 5989, 5990, 5991, 5992, 5993, 5994, 5995, 5996, 5997, 5998, 5999, 6000, 6001, 6002, 6003, 6004, 6005, 6006, 6007, 6008, 6009, 6010, 6011, 6012, 6013, 6014, 6015, 6016, 6017, 6018, 6019, 6020, 6021, 6022, 6023, 6024, 6025, 6026, 6027, 6028, 6029, 6030, 6031, 6032, 6033, 6034, 6035, 6036, 6037, 6038, 6039, 6040, 6041, 6042, 6043, 6044, 6045, 6046, 6047, 6048, 6049, 6050, 6051, 6052, 6053, 6054, 6055, 6056, 6057, 6058, 6059, 6060, 6061, 6062, 6063, 6064, 6065, 6066, 6067, 6068, 6069, 6070, 6071, 6072, 6073, 6074, 6075, 6076, 6077, 6078, 6079, 6080, 6081, 6082, 6083, 6084, 6085, 6086, 6087, 6088, 6089, 6090, 6091, 6092, 6093, 6094, 6095, 6096, 6097, 6098, 6099, 6100, 6101, 6102, 6103, 6104, 6105, 6106, 6107, 6108, 6109, 6110, 6111, 6112, 6113, 6114, 6115, 6116, 6117, 6118, 6119, 6120, 6121, 6122, 6123, 6124, 6125, 6126, 6127, 6128, 6129, 6130, 6131, 6132, 6133, 6134, 6135, 6136, 6137, 6138, 6139, 6140, 6141, 6142, 6143, 6144, 6145, 6146, 6147, 6148, 6149, 6150, 6151, 6152, 6153, 6154, 6155, 6156, 6157, 6158, 6159, 6160, 6161, 6162, 6163, 6164, 6165, 6166, 6167, 6168, 6169, 6170, 6171, 6172, 6173, 6174, 6175, 6176, 6177, 6178, 6179, 6180, 6181, 6182, 6183, 6184, 6185, 6186, 6187, 6188, 6189, 6190, 6191, 6192, 6193, 6194, 6195, 6196, 6197, 6198, 6199, 6200, 6201, 6202, 6203, 6204, 6205, 6206, 6207, 6208, 6209, 6210, 6211, 6212, 6213, 6214, 6215, 6216, 6217, 6218, 6219, 6220, 6221, 6222, 6223, 6224, 6225, 6226, 6227, 6228, 6229, 6230, 6231, 6232, 6233, 6234, 6235, 6236, 6237, 6238, 6239, 6240, 6241, 6242, 6243, 6244, 6245, 6246, 6247, 6248, 6249, 6250, 6251, 6252, 6253, 6254, 6255, 6256, 6257, 6258, 6259, 6260, 6261, 6262, 6263, 6264, 6265, 6266, 6267, 6268, 6269, 6270, 6271, 6272, 6273, 6274, 6275, 6276, 6277, 6278, 6279, 6280, 6281, 6282, 6283, 6284, 6285, 6286, 6287, 6288, 6289, 6290, 6291, 6292, 6293, 6294, 6295, 6296, 6297, 6298, 6299, 6300, 6301, 6302, 6303, 6304, 6305, 6306, 6307, 6308, 6309, 6310, 6311, 6312, 6313, 6314, 6315, 6316, 6317, 6318, 6319, 6320, 6321, 6322, 6323, 6324, 6325, 6326, 6327, 6328, 6329, 6330, 6331, 6332, 6333, 6334, 6335, 6336, 6337, 6338, 6339, 6340, 6341, 6342, 6343, 6344, 6345, 6346, 6347, 6348, 6349, 6350, 6351, 6352, 6353, 6354, 6355, 6356, 6357, 6358, 6359, 6360, 6361, 6362, 6363, 6364, 6365, 6366, 6367, 6368, 6369, 6370, 6371, 6372, 6373, 6374, 6375, 6376, 6377, 6378, 6379, 6380, 6381, 6382, 6383, 6384, 6385, 6386, 6387, 6388, 6389, 6390, 6391, 6392, 6393, 6394, 6395, 6396, 6397, 6398, 6399, 6400, 6401, 6402, 6403, 6404, 6405, 6406, 6407, 6408, 6409, 6410, 6411, 6412, 6413, 6414, 6415, 6416, 6417, 6418, 6419, 6420, 6421, 6422, 6423, 6424, 6425, 6426, 6427, 6428, 6429, 6430, 6431, 6432, 6433, 6434, 6435, 6436, 6437, 6438, 6439, 6440, 6441, 6442, 6443, 6444, 6445, 6446, 6447, 6448, 6449, 6450, 6451, 6452, 6453, 6454, 6455, 6456, 6457, 6458, 6459, 6460, 6461, 6462, 6463, 6464, 6465, 6466, 6467, 6468, 6469, 6470, 6471, 6472, 6473, 6474, 6475, 6476, 6477, 6478, 6479, 6480, 6481, 6482, 6483, 6484, 6485, 6486, 6487, 6488, 6489, 6490, 6491, 6492, 6493, 6494, 6495, 6496, 6497, 6498, 6499, 6500, 6501, 6502, 6503, 6504, 6505, 6506, 6507, 6508, 6509, 6510, 6511, 6512, 6513, 6514, 6515, 6516, 6517, 6518, 6519, 6520, 6521, 6522, 6523, 6524, 6525, 6526, 6527, 6528, 6529, 6530, 6531, 6532, 6533, 6534, 6535, 6536, 6537, 6538, 6539, 6540, 6541, 6542, 6543, 6544, 6545, 6546, 6547, 6548, 6549, 6550, 6551, 6552, 6553, 6554, 6555, 6556, 6557, 6558, 6559, 6560, 6561, 6562, 6563, 6564, 6565, 6566, 6567, 6568, 6569, 6570, 6571, 6572, 6573, 6574, 6575, 6576, 6577, 6578, 6579, 6580, 6581, 6582, 6583, 6584, 6585, 6586, 6587, 6588, 6589, 6590, 6591, 6592, 6593, 6594, 6595, 6596, 6597, 6598, 6599, 6600, 6601, 6602, 6603, 6604, 6605, 6606, 6607, 6608, 6609, 6610, 6611, 6612, 6613, 6614, 6615, 6616, 6617, 6618, 6619, 6620, 6621, 6622, 6623, 6624, 6625, 6626, 6627, 6628, 6629, 6630, 6631, 6632, 6633, 6634, 6635, 6636, 6637, 6638, 6639, 6640, 6641, 6642, 6643, 6644, 6645, 6646, 6647, 6648, 6649, 6650, 6651, 6652, 6653, 6654, 6655, 6656, 6657, 6658, 6659, 6660, 6661, 6662, 6663, 6664, 6665, 6666, 6667, 6668, 6669, 6670, 6671, 6672, 6673, 6674, 6675, 6676, 6677, 6678, 6679, 6680, 6681, 6682, 6683, 6684, 6685, 6686, 6687, 6688, 6689, 6690, 6691, 6692, 6693, 6694, 6695, 6696, 6697, 6698, 6699, 6700, 6701, 6702, 6703, 6704, 6705, 6706, 6707, 6708, 6709, 6710, 6711, 6712, 6713, 6714, 6715, 6716, 6717, 6718, 6719, 6720, 6721, 6722, 6723, 6724, 6725, 6726, 6727, 6728, 6729, 6730, 6731, 6732, 6733, 6734, 6735, 6736, 6737, 6738, 6739, 6740, 6741, 6742, 6743, 6744, 6745, 6746, 6747, 6748, 6749, 6750, 6751, 6752, 6753, 6754, 6755, 6756, 6757, 6758, 6759, 6760, 6761, 6762, 6763, 6764, 6765, 6766, 6767, 6768, 6769, 6770, 6771, 6772, 6773, 6774, 6775, 6776, 6777, 6778, 6779, 6780, 6781, 6782, 6783, 6784, 6785, 6786, 6787, 6788, 6789, 6790, 6791, 6792, 6793, 6794, 6795, 6796, 6797, 6798, 6799, 6800, 6801, 6802, 6803, 6804, 6805, 6806, 6807, 6808, 6809, 6810, 6811, 6812, 6813, 6814, 6815, 6816, 6817, 6818, 6819, 6820, 6821, 6822, 6823, 6824, 6825, 6826, 6827, 6828, 6829, 6830, 6831, 6832, 6833, 6834, 6835, 6836, 6837, 6838, 6839, 6840, 6841, 6842, 6843, 6844, 6845, 6846, 6847, 6848, 6849, 6850, 6851, 6852, 6853, 6854, 6855, 6856, 6857, 6858, 6859, 6860, 6861, 6862, 6863, 6864, 6865, 6866, 6867, 6868, 6869, 6870, 6871, 6872, 6873, 6874, 6875, 6876, 6877, 6878, 6879, 6880, 6881, 6882, 6883, 6884, 6885, 6886, 6887, 6888, 6889, 6890, 6891, 6892, 6893, 6894, 6895, 6896, 6897, 6898, 6899, 6900, 6901, 6902, 6903, 6904, 6905, 6906, 6907, 6908, 6909, 6910, 6911, 6912, 6913, 6914, 6915, 6916, 6917, 6918, 6919, 6920, 6921, 6922, 6923, 6924, 6925, 6926, 6927, 6928, 6929, 6930, 6931, 6932, 6933, 6934, 6935, 6936, 6937, 6938, 6939, 6940, 6941, 6942, 6943, 6944, 6945, 6946, 6947, 6948, 6949, 6950, 6951, 6952, 6953, 6954, 6955, 6956, 6957, 6958, 6959, 6960, 6961, 6962, 6963, 6964, 6965, 6966, 6967, 6968, 6969, 6970, 6971, 6972, 6973, 6974, 6975, 6976, 6977, 6978, 6979, 6980, 6981, 6982, 6983, 6984, 6985, 6986, 6987, 6988, 6989, 6990, 6991, 6992, 6993, 6994, 6995, 6996, 6997, 6998, 6999, 7000, 7001, 7002, 7003, 7004, 7005, 7006, 7007, 7008, 7009, 7010, 7011, 7012, 7013, 7014, 7015, 7016, 7017, 7018, 7019, 7020, 7021, 7022, 7023, 7024, 7025, 7026, 7027, 7028, 7029, 7030, 7031, 7032, 7033, 7034, 7035, 7036, 7037, 7038, 7039, 7040, 7041, 7042, 7043, 7044, 7045, 7046, 7047, 7048, 7049, 7050, 7051, 7052, 7053, 7054, 7055, 7056, 7057, 7058, 7059, 7060, 7061, 7062, 7063, 7064, 7065, 7066, 7067, 7068, 7069, 7070, 7071, 7072, 7073, 7074, 7075, 7076, 7077, 7078, 7079, 7080, 7081, 7082, 7083, 7084, 7085, 7086, 7087, 7088, 7089, 7090, 7091, 7092, 7093, 7094, 7095, 7096, 7097, 7098, 7099, 7100, 7101, 7102, 7103, 7104, 7105, 7106, 7107, 7108, 7109, 7110, 7111, 7112, 7113, 7114, 7115, 7116, 7117, 7118, 7119, 7120, 7121, 7122, 7123, 7124, 7125, 7126, 7127, 7128, 7129, 7130, 7131, 7132, 7133, 7134, 7135, 7136, 7137, 7138, 7139, 7140, 7141, 7142, 7143, 7144, 7145, 7146, 7147, 7148, 7149, 7150, 7151, 7152, 7153, 7154, 7155, 7156, 7157, 7158, 7159, 7160, 7161, 7162, 7163, 7164, 7165, 7166, 7167, 7168, 7169, 7170, 7171, 7172, 7173, 7174, 7175, 7176, 7177, 7178, 7179, 7180, 7181, 7182, 7183, 7184, 7185, 7186, 7187, 7188, 7189, 7190, 7191, 7192, 7193, 7194, 7195, 7196, 7197, 7198, 7199, 7200, 7201, 7202, 7203, 7204, 7205, 7206, 7207, 7208, 7209, 7210, 7211, 7212, 7213, 7214, 7215, 7216, 7217, 7218, 7219, 7220, 7221, 7222, 7223, 7224, 7225, 7226, 7227, 7228, 7229, 7230, 7231, 7232, 7233, 7234, 7235, 7236, 7237, 7238, 7239, 7240, 7241, 7242, 7243, 7244, 7245, 7246, 7247, 7248, 7249, 7250, 7251, 7252, 7253, 7254, 7255, 7256, 7257, 7258, 7259, 7260, 7261, 7262, 7263, 7264, 7265, 7266, 7267, 7268, 7269, 7270, 7271, 7272, 7273, 7274, 7275, 7276, 7277, 7278, 7279, 7280, 7281, 7282, 7283, 7284, 7285, 7286, 7287, 7288, 7289, 7290, 7291, 7292, 7293, 7294, 7295, 7296, 7297, 7298, 7299, 7300, 7301, 7302, 7303, 7304, 7305, 7306, 7307, 7308, 7309, 7310, 7311, 7312, 7313, 7314, 7315, 7316, 7317, 7318, 7319, 7320, 7321, 7322, 7323, 7324, 7325, 7326, 7327, 7328, 7329, 7330, 7331, 7332, 7333, 7334, 7335, 7336, 7337, 7338, 7339, 7340, 7341, 7342, 7343, 7344, 7345, 7346, 7347, 7348, 7349, 7350, 7351, 7352, 7353, 7354, 7355, 7356, 7357, 7358, 7359, 7360, 7361, 7362, 7363, 7364, 7365, 7366, 7367, 7368, 7369, 7370, 7371, 7372, 7373, 7374, 7375, 7376, 7377, 7378, 7379, 7380, 7381, 7382, 7383, 7384, 7385, 7386, 7387, 7388, 7389, 7390, 7391, 7392, 7393, 7394, 7395, 7396, 7397, 7398, 7399, 7400, 7401, 7402, 7403, 7404, 7405, 7406, 7407, 7408, 7409, 7410, 7411, 7412, 7413, 7414, 7415, 7416, 7417, 7418, 7419, 7420, 7421, 7422, 7423, 7424, 7425, 7426, 7427, 7428, 7429, 7430, 7431, 7432, 7433, 7434, 7435, 7436, 7437, 7438, 7439, 7440, 7441, 7442, 7443, 7444, 7445, 7446, 7447, 7448, 7449, 7450, 7451, 7452, 7453, 7454, 7455, 7456, 7457, 7458, 7459, 7460, 7461, 7462, 7463, 7464, 7465, 7466, 7467, 7468, 7469, 7470, 7471, 7472, 7473, 7474, 7475, 7476, 7477, 7478, 7479, 7480, 7481, 7482, 7483, 7484, 7485, 7486, 7487, 7488, 7489, 7490, 7491, 7492, 7493, 7494, 7495, 7496, 7497, 7498, 7499, 7500, 7501, 7502, 7503, 7504, 7505, 7506, 7507, 7508, 7509, 7510, 7511, 7512, 7513, 7514, 7515, 7516, 7517, 7518, 7519, 7520, 7521, 7522, 7523, 7524, 7525, 7526, 7527, 7528, 7529, 7530, 7531, 7532, 7533, 7534, 7535, 7536, 7537, 7538, 7539, 7540, 7541, 7542, 7543, 7544, 7545, 7546, 7547, 7548, 7549, 7550, 7551, 7552, 7553, 7554, 7555, 7556, 7557, 7558, 7559, 7560, 7561, 7562, 7563, 7564, 7565, 7566, 7567, 7568, 7569, 7570, 7571, 7572, 7573, 7574, 7575, 7576, 7577, 7578, 7579, 7580, 7581, 7582, 7583, 7584, 7585, 7586, 7587, 7588, 7589, 7590, 7591, 7592, 7593, 7594, 7595, 7596, 7597, 7598, 7599, 7600, 7601, 7602, 7603, 7604, 7605, 7606, 7607, 7608, 7609, 7610, 7611, 7612, 7613, 7614, 7615, 7616, 7617, 7618, 7619, 7620, 7621, 7622, 7623, 7624, 7625, 7626, 7627, 7628, 7629, 7630, 7631, 7632, 7633, 7634, 7635, 7636, 7637, 7638, 7639, 7640, 7641, 7642, 7643, 7644, 7645, 7646, 7647, 7648, 7649, 7650, 7651, 7652, 7653, 7654, 7655, 7656, 7657, 7658, 7659, 7660, 7661, 7662, 7663, 7664, 7665, 7666, 7667, 7668, 7669, 7670, 7671, 7672, 7673, 7674, 7675, 7676, 7677, 7678, 7679, 7680, 7681, 7682, 7683, 7684, 7685, 7686, 7687, 7688, 7689, 7690, 7691, 7692, 7693, 7694, 7695, 7696, 7697, 7698, 7699, 7700, 7701, 7702, 7703, 7704, 7705, 7706, 7707, 7708, 7709, 7710, 7711, 7712, 7713, 7714, 7715, 7716, 7717, 7718, 7719, 7720, 7721, 7722, 7723, 7724, 7725, 7726, 7727, 7728, 7729, 7730, 7731, 7732, 7733, 7734, 7735, 7736, 7737, 7738, 7739, 7740, 7741, 7742, 7743, 7744, 7745, 7746, 7747, 7748, 7749, 7750, 7751, 7752, 7753, 7754, 7755, 7756, 7757, 7758, 7759, 7760, 7761, 7762, 7763, 7764, 7765, 7766, 7767, 7768, 7769, 7770, 7771, 7772, 7773, 7774, 7775, 7776, 7777, 7778, 7779, 7780, 7781, 7782, 7783, 7784, 7785, 7786, 7787, 7788, 7789, 7790, 7791, 7792, 7793, 7794, 7795, 7796, 7797, 7798, 7799, 7800, 7801, 7802, 7803, 7804, 7805, 7806, 7807, 7808, 7809, 7810, 7811, 7812, 7813, 7814, 7815, 7816, 7817, 7818, 7819, 7820, 7821, 7822, 7823, 7824, 7825, 7826, 7827, 7828, 7829, 7830, 7831, 7832, 7833, 7834, 7835, 7836, 7837, 7838, 7839, 7840, 7841, 7842, 7843, 7844, 7845, 7846, 7847, 7848, 7849, 7850, 7851, 7852, 7853, 7854, 7855, 7856, 7857, 7858, 7859, 7860, 7861, 7862, 7863, 7864, 7865, 7866, 7867, 7868, 7869, 7870, 7871, 7872, 7873, 7874, 7875, 7876, 7877, 7878, 7879, 7880, 7881, 7882, 7883, 7884, 7885, 7886, 7887, 7888, 7889, 7890, 7891, 7892, 7893, 7894, 7895, 7896, 7897, 7898, 7899, 7900, 7901, 7902, 7903, 7904, 7905, 7906, 7907, 7908, 7909, 7910, 7911, 7912, 7913, 7914, 7915, 7916, 7917, 7918, 7919, 7920, 7921, 7922, 7923, 7924, 7925, 7926, 7927, 7928, 7929, 7930, 7931, 7932, 7933, 7934, 7935, 7936, 7937, 7938, 7939, 7940, 7941, 7942, 7943, 7944, 7945, 7946, 7947, 7948, 7949, 7950, 7951, 7952, 7953, 7954, 7955, 7956, 7957, 7958, 7959, 7960, 7961, 7962, 7963, 7964, 7965, 7966, 7967, 7968, 7969, 7970, 7971, 7972, 7973, 7974, 7975, 7976, 7977, 7978, 7979, 7980, 7981, 7982, 7983, 7984, 7985, 7986, 7987, 7988, 7989, 7990, 7991, 7992, 7993, 7994, 7995, 7996, 7997, 7998, 7999, 8000, 8001, 8002, 8003, 8004, 8005, 8006, 8007, 8008, 8009, 8010, 8011, 8012, 8013, 8014, 8015, 8016, 8017, 8018, 8019, 8020, 8021, 8022, 8023, 8024, 8025, 8026, 8027, 8028, 8029, 8030, 8031, 8032, 8033, 8034, 8035, 8036, 8037, 8038, 8039, 8040, 8041, 8042, 8043, 8044, 8045, 8046, 8047, 8048, 8049, 8050, 8051, 8052, 8053, 8054, 8055, 8056, 8057, 8058, 8059, 8060, 8061, 8062, 8063, 8064, 8065, 8066, 8067, 8068, 8069, 8070, 8071, 8072, 8073, 8074, 8075, 8076, 8077, 8078, 8079, 8080, 8081, 8082, 8083, 8084, 8085, 8086, 8087, 8088, 8089, 8090, 8091, 8092, 8093, 8094, 8095, 8096, 8097, 8098, 8099, 8100, 8101, 8102, 8103, 8104, 8105, 8106, 8107, 8108, 8109, 8110, 8111, 8112, 8113, 8114, 8115, 8116, 8117, 8118, 8119, 8120, 8121, 8122, 8123, 8124, 8125, 8126, 8127, 8128, 8129, 8130, 8131, 8132, 8133, 8134, 8135, 8136, 8137, 8138, 8139, 8140, 8141, 8142, 8143, 8144, 8145, 8146, 8147, 8148, 8149, 8150, 8151, 8152, 8153, 8154, 8155, 8156, 8157, 8158, 8159, 8160, 8161, 8162, 8163, 8164, 8165, 8166, 8167, 8168, 8169, 8170, 8171, 8172, 8173, 8174, 8175, 8176, 8177, 8178, 8179, 8180, 8181, 8182, 8183, 8184, 8185, 8186, 8187, 8188, 8189, 8190, 8191, 8192, 8193, 8194, 8195, 8196, 8197, 8198, 8199, 8200, 8201, 8202, 8203, 8204, 8205, 8206, 8207, 8208, 8209, 8210, 8211, 8212, 8213, 8214, 8215, 8216, 8217, 8218, 8219, 8220, 8221, 8222, 8223, 8224, 8225, 8226, 8227, 8228, 8229, 8230, 8231, 8232, 8233, 8234, 8235, 8236, 8237, 8238, 8239, 8240, 8241, 8242, 8243, 8244, 8245, 8246, 8247, 8248, 8249, 8250, 8251, 8252, 8253, 8254, 8255, 8256, 8257, 8258, 8259, 8260, 8261, 8262, 8263, 8264, 8265, 8266, 8267, 8268, 8269, 8270, 8271, 8272, 8273, 8274, 8275, 8276, 8277, 8278, 8279, 8280, 8281, 8282, 8283, 8284, 8285, 8286, 8287, 8288, 8289, 8290, 8291, 8292, 8293, 8294, 8295, 8296, 8297, 8298, 8299, 8300, 8301, 8302, 8303, 8304, 8305, 8306, 8307, 8308, 8309, 8310, 8311, 8312, 8313, 8314, 8315, 8316, 8317, 8318, 8319, 8320, 8321, 8322, 8323, 8324, 8325, 8326, 8327, 8328, 8329, 8330, 8331, 8332, 8333, 8334, 8335, 8336, 8337, 8338, 8339, 8340, 8341, 8342, 8343, 8344, 8345, 8346, 8347, 8348, 8349, 8350, 8351, 8352, 8353, 8354, 8355, 8356, 8357, 8358, 8359, 8360, 8361, 8362, 8363, 8364, 8365, 8366, 8367, 8368, 8369, 8370, 8371, 8372, 8373, 8374, 8375, 8376, 8377, 8378, 8379, 8380, 8381, 8382, 8383, 8384, 8385, 8386, 8387, 8388, 8389, 8390, 8391, 8392, 8393, 8394, 8395, 8396, 8397, 8398, 8399, 8400, 8401, 8402, 8403, 8404, 8405, 8406, 8407, 8408, 8409, 8410, 8411, 8412, 8413, 8414, 8415, 8416, 8417, 8418, 8419, 8420, 8421, 8422, 8423, 8424, 8425, 8426, 8427, 8428, 8429, 8430, 8431, 8432, 8433, 8434, 8435, 8436, 8437, 8438, 8439, 8440, 8441, 8442, 8443, 8444, 8445, 8446, 8447, 8448, 8449, 8450, 8451, 8452, 8453, 8454, 8455, 8456, 8457, 8458, 8459, 8460, 8461, 8462, 8463, 8464, 8465, 8466, 8467, 8468, 8469, 8470, 8471, 8472, 8473, 8474, 8475, 8476, 8477, 8478, 8479, 8480, 8481, 8482, 8483, 8484, 8485, 8486, 8487, 8488, 8489, 8490, 8491, 8492, 8493, 8494, 8495, 8496, 8497, 8498, 8499, 8500, 8501, 8502, 8503, 8504, 8505, 8506, 8507, 8508, 8509, 8510, 8511, 8512, 8513, 8514, 8515, 8516, 8517, 8518, 8519, 8520, 8521, 8522, 8523, 8524, 8525, 8526, 8527, 8528, 8529, 8530, 8531, 8532, 8533, 8534, 8535, 8536, 8537, 8538, 8539, 8540, 8541, 8542, 8543, 8544, 8545, 8546, 8547, 8548, 8549, 8550, 8551, 8552, 8553, 8554, 8555, 8556, 8557, 8558, 8559, 8560, 8561, 8562, 8563, 8564, 8565, 8566, 8567, 8568, 8569, 8570, 8571, 8572, 8573, 8574, 8575, 8576, 8577, 8578, 8579, 8580, 8581, 8582, 8583, 8584, 8585, 8586, 8587, 8588, 8589, 8590, 8591, 8592, 8593, 8594, 8595, 8596, 8597, 8598, 8599, 8600, 8601, 8602, 8603, 8604, 8605, 8606, 8607, 8608, 8609, 8610, 8611, 8612, 8613, 8614, 8615, 8616, 8617, 8618, 8619, 8620, 8621, 8622, 8623, 8624, 8625, 8626, 8627, 8628, 8629, 8630, 8631, 8632, 8633, 8634, 8635, 8636, 8637, 8638, 8639, 8640, 8641, 8642, 8643, 8644, 8645, 8646, 8647, 8648, 8649, 8650, 8651, 8652, 8653, 8654, 8655, 8656, 8657, 8658, 8659, 8660, 8661, 8662, 8663, 8664, 8665, 8666, 8667, 8668, 8669, 8670, 8671, 8672, 8673, 8674, 8675, 8676, 8677, 8678, 8679, 8680, 8681, 8682, 8683, 8684, 8685, 8686, 8687, 8688, 8689, 8690, 8691, 8692, 8693, 8694, 8695, 8696, 8697, 8698, 8699, 8700, 8701, 8702, 8703, 8704, 8705, 8706, 8707, 8708, 8709, 8710, 8711, 8712, 8713, 8714, 8715, 8716, 8717, 8718, 8719, 8720, 8721, 8722, 8723, 8724, 8725, 8726, 8727, 8728, 8729, 8730, 8731, 8732, 8733, 8734, 8735, 8736, 8737, 8738, 8739, 8740, 8741, 8742, 8743, 8744, 8745, 8746, 8747, 8748, 8749, 8750, 8751, 8752, 8753, 8754, 8755, 8756, 8757, 8758, 8759, 8760, 8761, 8762, 8763, 8764, 8765, 8766, 8767, 8768, 8769, 8770, 8771, 8772, 8773, 8774, 8775, 8776, 8777, 8778, 8779, 8780, 8781, 8782, 8783, 8784, 8785, 8786, 8787, 8788, 8789, 8790, 8791, 8792, 8793, 8794, 8795, 8796, 8797, 8798, 8799, 8800, 8801, 8802, 8803, 8804, 8805, 8806, 8807, 8808, 8809, 8810, 8811, 8812, 8813, 8814, 8815, 8816, 8817, 8818, 8819, 8820, 8821, 8822, 8823, 8824, 8825, 8826, 8827, 8828, 8829, 8830, 8831, 8832, 8833, 8834, 8835, 8836, 8837, 8838, 8839, 8840, 8841, 8842, 8843, 8844, 8845, 8846, 8847, 8848, 8849, 8850, 8851, 8852, 8853, 8854, 8855, 8856, 8857, 8858, 8859, 8860, 8861, 8862, 8863, 8864, 8865, 8866, 8867, 8868, 8869, 8870, 8871, 8872, 8873, 8874, 8875, 8876, 8877, 8878, 8879, 8880, 8881, 8882, 8883, 8884, 8885, 8886, 8887, 8888, 8889, 8890, 8891, 8892, 8893, 8894, 8895, 8896, 8897, 8898, 8899, 8900, 8901, 8902, 8903, 8904, 8905, 8906, 8907, 8908, 8909, 8910, 8911, 8912, 8913, 8914, 8915, 8916, 8917, 8918, 8919, 8920, 8921, 8922, 8923, 8924, 8925, 8926, 8927, 8928, 8929, 8930, 8931, 8932, 8933, 8934, 8935, 8936, 8937, 8938, 8939, 8940, 8941, 8942, 8943, 8944, 8945, 8946, 8947, 8948, 8949, 8950, 8951, 8952, 8953, 8954, 8955, 8956, 8957, 8958, 8959, 8960, 8961, 8962, 8963, 8964, 8965, 8966, 8967, 8968, 8969, 8970, 8971, 8972, 8973, 8974, 8975, 8976, 8977, 8978, 8979, 8980, 8981, 8982, 8983, 8984, 8985, 8986, 8987, 8988, 8989, 8990, 8991, 8992, 8993, 8994, 8995, 8996, 8997, 8998, 8999, 9000, 9001, 9002, 9003, 9004, 9005, 9006, 9007, 9008, 9009, 9010, 9011, 9012, 9013, 9014, 9015, 9016, 9017, 9018, 9019, 9020, 9021, 9022, 9023, 9024, 9025, 9026, 9027, 9028, 9029, 9030, 9031, 9032, 9033, 9034, 9035, 9036, 9037, 9038, 9039, 9040, 9041, 9042, 9043, 9044, 9045, 9046, 9047, 9048, 9049, 9050, 9051, 9052, 9053, 9054, 9055, 9056, 9057, 9058, 9059, 9060, 9061, 9062, 9063, 9064, 9065, 9066, 9067, 9068, 9069, 9070, 9071, 9072, 9073, 9074, 9075, 9076, 9077, 9078, 9079, 9080, 9081, 9082, 9083, 9084, 9085, 9086, 9087, 9088, 9089, 9090, 9091, 9092, 9093, 9094, 9095, 9096, 9097, 9098, 9099, 9100, 9101, 9102, 9103, 9104, 9105, 9106, 9107, 9108, 9109, 9110, 9111, 9112, 9113, 9114, 9115, 9116, 9117, 9118, 9119, 9120, 9121, 9122, 9123, 9124, 9125, 9126, 9127, 9128, 9129, 9130, 9131, 9132, 9133, 9134, 9135, 9136, 9137, 9138, 9139, 9140, 9141, 9142, 9143, 9144, 9145, 9146, 9147, 9148, 9149, 9150, 9151, 9152, 9153, 9154, 9155, 9156, 9157, 9158, 9159, 9160, 9161, 9162, 9163, 9164, 9165, 9166, 9167, 9168, 9169, 9170, 9171, 9172, 9173, 9174, 9175, 9176, 9177, 9178, 9179, 9180, 9181, 9182, 9183, 9184, 9185, 9186, 9187, 9188, 9189, 9190, 9191, 9192, 9193, 9194, 9195, 9196, 9197, 9198, 9199, 9200, 9201, 9202, 9203, 9204, 9205, 9206, 9207, 9208, 9209, 9210, 9211, 9212, 9213, 9214, 9215, 9216, 9217, 9218, 9219, 9220, 9221, 9222, 9223, 9224, 9225, 9226, 9227, 9228, 9229, 9230, 9231, 9232, 9233, 9234, 9235, 9236, 9237, 9238, 9239, 9240, 9241, 9242, 9243, 9244, 9245, 9246, 9247, 9248, 9249, 9250, 9251, 9252, 9253, 9254, 9255, 9256, 9257, 9258, 9259, 9260, 9261, 9262, 9263, 9264, 9265, 9266, 9267, 9268, 9269, 9270, 9271, 9272, 9273, 9274, 9275, 9276, 9277, 9278, 9279, 9280, 9281, 9282, 9283, 9284, 9285, 9286, 9287, 9288, 9289, 9290, 9291, 9292, 9293, 9294, 9295, 9296, 9297, 9298, 9299, 9300, 9301, 9302, 9303, 9304, 9305, 9306, 9307, 9308, 9309, 9310, 9311, 9312, 9313, 9314, 9315, 9316, 9317, 9318, 9319, 9320, 9321, 9322, 9323, 9324, 9325, 9326, 9327, 9328, 9329, 9330, 9331, 9332, 9333, 9334, 9335, 9336, 9337, 9338, 9339, 9340, 9341, 9342, 9343, 9344, 9345, 9346, 9347, 9348, 9349, 9350, 9351, 9352, 9353, 9354, 9355, 9356, 9357, 9358, 9359, 9360, 9361, 9362, 9363, 9364, 9365, 9366, 9367, 9368, 9369, 9370, 9371, 9372, 9373, 9374, 9375, 9376, 9377, 9378, 9379, 9380, 9381, 9382, 9383, 9384, 9385, 9386, 9387, 9388, 9389, 9390, 9391, 9392, 9393, 9394, 9395, 9396, 9397, 9398, 9399, 9400, 9401, 9402, 9403, 9404, 9405, 9406, 9407, 9408, 9409, 9410, 9411, 9412, 9413, 9414, 9415, 9416, 9417, 9418, 9419, 9420, 9421, 9422, 9423, 9424, 9425, 9426, 9427, 9428, 9429, 9430, 9431, 9432, 9433, 9434, 9435, 9436, 9437, 9438, 9439, 9440, 9441, 9442, 9443, 9444, 9445, 9446, 9447, 9448, 9449, 9450, 9451, 9452, 9453, 9454, 9455, 9456, 9457, 9458, 9459, 9460, 9461, 9462, 9463, 9464, 9465, 9466, 9467, 9468, 9469, 9470, 9471, 9472, 9473, 9474, 9475, 9476, 9477, 9478, 9479, 9480, 9481, 9482, 9483, 9484, 9485, 9486, 9487, 9488, 9489, 9490, 9491, 9492, 9493, 9494, 9495, 9496, 9497, 9498, 9499, 9500, 9501, 9502, 9503, 9504, 9505, 9506, 9507, 9508, 9509, 9510, 9511, 9512, 9513, 9514, 9515, 9516, 9517, 9518, 9519, 9520, 9521, 9522, 9523, 9524, 9525, 9526, 9527, 9528, 9529, 9530, 9531, 9532, 9533, 9534, 9535, 9536, 9537, 9538, 9539, 9540, 9541, 9542, 9543, 9544, 9545, 9546, 9547, 9548, 9549, 9550, 9551, 9552, 9553, 9554, 9555, 9556, 9557, 9558, 9559, 9560, 9561, 9562, 9563, 9564, 9565, 9566, 9567, 9568, 9569, 9570, 9571, 9572, 9573, 9574, 9575, 9576, 9577, 9578, 9579, 9580, 9581, 9582, 9583, 9584, 9585, 9586, 9587, 9588, 9589, 9590, 9591, 9592, 9593, 9594, 9595, 9596, 9597, 9598, 9599, 9600, 9601, 9602, 9603, 9604, 9605, 9606, 9607, 9608, 9609, 9610, 9611, 9612, 9613, 9614, 9615, 9616, 9617, 9618, 9619, 9620, 9621, 9622, 9623, 9624, 9625, 9626, 9627, 9628, 9629, 9630, 9631, 9632, 9633, 9634, 9635, 9636, 9637, 9638, 9639, 9640, 9641, 9642, 9643, 9644, 9645, 9646, 9647, 9648, 9649, 9650, 9651, 9652, 9653, 9654, 9655, 9656, 9657, 9658, 9659, 9660, 9661, 9662, 9663, 9664, 9665, 9666, 9667, 9668, 9669, 9670, 9671, 9672, 9673, 9674, 9675, 9676, 9677, 9678, 9679, 9680, 9681, 9682, 9683, 9684, 9685, 9686, 9687, 9688, 9689, 9690, 9691, 9692, 9693, 9694, 9695, 9696, 9697, 9698, 9699, 9700, 9701, 9702, 9703, 9704, 9705, 9706, 9707, 9708, 9709, 9710, 9711, 9712, 9713, 9714, 9715, 9716, 9717, 9718, 9719, 9720, 9721, 9722, 9723, 9724, 9725, 9726, 9727, 9728, 9729, 9730, 9731, 9732, 9733, 9734, 9735, 9736, 9737, 9738, 9739, 9740, 9741, 9742, 9743, 9744, 9745, 9746, 9747, 9748, 9749, 9750, 9751, 9752, 9753, 9754, 9755, 9756, 9757, 9758, 9759, 9760, 9761, 9762, 9763, 9764, 9765, 9766, 9767, 9768, 9769, 9770, 9771, 9772, 9773, 9774, 9775, 9776, 9777, 9778, 9779, 9780, 9781, 9782, 9783, 9784, 9785, 9786, 9787, 9788, 9789, 9790, 9791, 9792, 9793, 9794, 9795, 9796, 9797, 9798, 9799, 9800, 9801, 9802, 9803, 9804, 9805, 9806, 9807, 9808, 9809, 9810, 9811, 9812, 9813, 9814, 9815, 9816, 9817, 9818, 9819, 9820, 9821, 9822, 9823, 9824, 9825, 9826, 9827, 9828, 9829, 9830, 9831, 9832, 9833, 9834, 9835, 9836, 9837, 9838, 9839, 9840, 9841, 9842, 9843, 9844, 9845, 9846, 9847, 9848, 9849, 9850, 9851, 9852, 9853, 9854, 9855, 9856, 9857, 9858, 9859, 9860, 9861, 9862, 9863, 9864, 9865, 9866, 9867, 9868, 9869, 9870, 9871, 9872, 9873, 9874, 9875, 9876, 9877, 9878, 9879, 9880, 9881, 9882, 9883, 9884, 9885, 9886, 9887, 9888, 9889, 9890, 9891, 9892, 9893, 9894, 9895, 9896, 9897, 9898, 9899, 9900, 9901, 9902, 9903, 9904, 9905, 9906, 9907, 9908, 9909, 9910, 9911, 9912, 9913, 9914, 9915, 9916, 9917, 9918, 9919, 9920, 9921, 9922, 9923, 9924, 9925, 9926, 9927, 9928, 9929, 9930, 9931, 9932, 9933, 9934, 9935, 9936, 9937, 9938, 9939, 9940, 9941, 9942, 9943, 9944, 9945, 9946, 9947, 9948, 9949, 9950, 9951, 9952, 9953, 9954, 9955, 9956, 9957, 9958, 9959, 9960, 9961, 9962, 9963, 9964, 9965, 9966, 9967, 9968, 9969, 9970, 9971, 9972, 9973, 9974, 9975, 9976, 9977, 9978, 9979, 9980, 9981, 9982, 9983, 9984, 9985, 9986, 9987, 9988, 9989, 9990, 9991, 9992, 9993, 9994, 9995, 9996, 9997, 9998, 9999]
(3d) Realizar la acción count para ver los conteos#
Uno de los trabajos más básicos que podemos ejecutar es el trabajo count(), que contará el número de elementos en un RDD usando la acción count(). Dado que map() crea un nuevo RDD con el mismo número de elementos que el RDD inicial, esperamos que aplicar count() a cada RDD devuelva el mismo resultado.#
Ten en cuenta que, debido a que count() es una operación de acción, si no hubiéramos realizado una acción con collect(), Spark ahora realizaría las operaciones de transformación cuando ejecutáramos count().#
Cada tarea cuenta las entradas en su partición y envía el resultado a tu SparkContext, que suma todos los conteos. La figura a continuación muestra lo que sucedería si ejecutáramos count() en un conjunto de datos de ejemplo pequeño con solo cuatro particiones.#
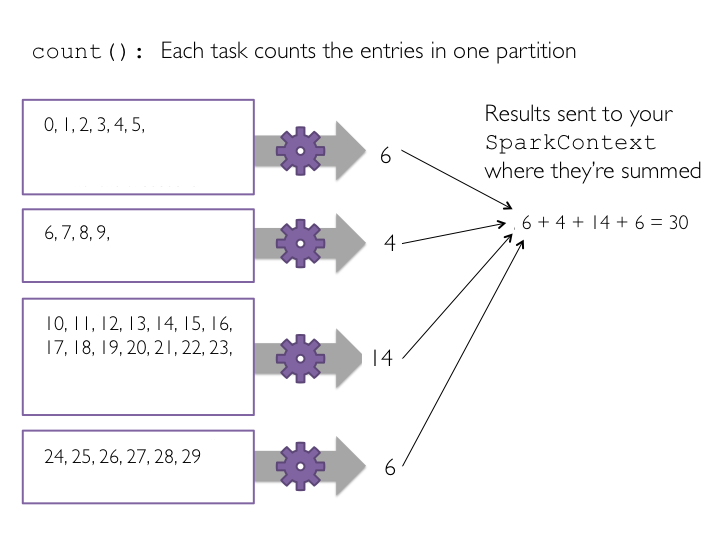
print(xrangeRDD.count())
print(subRDD.count())
10000
10000
(3e) Aplicar la transformación filter y ver los resultados con collect#
A continuación, crearemos un nuevo RDD que solo contenga los valores menores que diez utilizando la operación de datos paralelos filter(f). El método filter(f) es una operación de transformación que crea un nuevo RDD a partir del RDD de entrada aplicando la función de filtro f a cada elemento en el RDD principal y solo pasando aquellos elementos donde la función de filtro devuelve True. Los elementos que no devuelvan True serán descartados. Al igual que map(), filter se puede aplicar individualmente a cada entrada en el conjunto de datos, por lo que se paraleliza fácilmente usando Spark.#
La figura a continuación muestra cómo funcionaría esto en el conjunto de datos pequeño de cuatro particiones.#
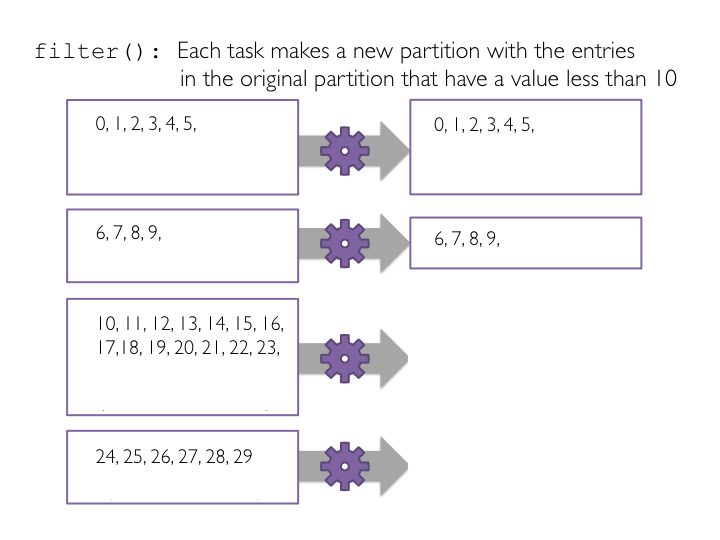
Para filtrar este conjunto de datos, definiremos una función llamada ten(), que devuelve True si la entrada es menor que 10 y False en caso contrario. Esta función se pasará a la transformación filter() como la función de filtro f.#
Para ver la lista filtrada de elementos menores que diez, necesitamos crear una nueva lista en el driver a partir de los datos distribuidos en los nodos ejecutores. Usamos el método collect() para devolver una lista que contenga todos los elementos en este RDD filtrado al programa driver.#
# Definir una función para filtrar un único valor
def ten(value):
"""Return whether value is below ten.
Args:
value (int): A number.
Returns:
bool: Whether `value` is less than ten.
"""
if (value < 10):
return True
else:
return False
# La función diez también podría escribirse de forma concisa como: def diez(valor): return valor < 10
# Pasa la función diez a la transformación filtro
# El filtro es una transformación por lo que no se ejecutan tareas
filteredRDD = subRDD.filter(ten)
# Ver los resultados usando collect()
# Recopilar es una acción y hace que se ejecute la transformación del filtro
print(filteredRDD.collect())
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
Part 4: Lambda Functions#
(4a) Uso de funciones lambda() en Python#
Python admite el uso de pequeñas funciones anónimas de una sola línea que no están vinculadas a un nombre en tiempo de ejecución. Tomadas de LISP, estas funciones lambda se pueden usar donde se requieran objetos de función. Están restringidas sintácticamente a una sola expresión. Recuerda que las funciones lambda son una cuestión de estilo y nunca son necesarias: semánticamente, son solo azúcar sintáctica para una definición de función normal. Siempre puedes definir una función normal por separado, pero usar una función lambda() es una forma equivalente y más compacta de codificación. Idealmente, deberías considerar usar funciones lambda donde quieras encapsular código no reutilizable sin llenar tu código con funciones de una sola línea.#
Aquí, en lugar de definir una función separada para la transformación filter(), usaremos una función lambda() en línea.#
lambdaRDD = subRDD.filter(lambda x: x < 10)
lambdaRDD.collect()
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
# Recojamos los valores pares menores que 10
evenRDD = lambdaRDD.filter(lambda x: x % 2 == 0)
evenRDD.collect()
[0, 2, 4, 6, 8]
Part 5: Additional RDD actions#
(5a) Otras acciones comunes#
Vamos a investigar las acciones adicionales: first(), take(), top(), takeOrdered() y reduce()#
Una cosa útil para hacer cuando tenemos un nuevo conjunto de datos es observar las primeras entradas para obtener una idea aproximada de la información disponible. En Spark, podemos hacerlo usando las acciones first(), take(), top() y takeOrdered(). Ten en cuenta que para las acciones first() y take(), los elementos que se devuelven dependen de cómo esté particionado el RDD.#
En lugar de usar la acción collect(), podemos usar la acción take(n) para devolver los primeros n elementos del RDD. La acción first() devuelve el primer elemento de un RDD y es equivalente a take(1).#
La acción takeOrdered() devuelve los primeros n elementos del RDD, usando su orden natural o un comparador personalizado. La ventaja clave de usar takeOrdered() en lugar de first() o take() es que takeOrdered() devuelve un resultado determinista, mientras que las otras dos acciones pueden devolver resultados diferentes, dependiendo del número de particiones o del entorno de ejecución. takeOrdered() devuelve la lista ordenada en orden ascendente. La acción top() es similar a takeOrdered(), excepto que devuelve la lista en orden descendente.#
La acción reduce() reduce los elementos de un RDD a un solo valor aplicando una función que toma dos parámetros y devuelve un solo valor. La función debe ser conmutativa y asociativa, ya que reduce() se aplica a nivel de partición y luego nuevamente para agregar resultados de particiones. Si estas reglas no se cumplen, los resultados de reduce() serán inconsistentes. Reducir localmente en las particiones hace que reduce() sea muy eficiente.#
# Obtengamos el primer elemento
print(filteredRDD.first())
# Los primeros 4
print(filteredRDD.take(4))
# Tenga en cuenta que está bien tomar más elementos que el RDD tiene
print(filteredRDD.take(12))
0
[0, 1, 2, 3]
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
# Recuperar los tres elementos más pequeños
print(filteredRDD.takeOrdered(3))
# Recuperar los cinco elementos más grandes
print(filteredRDD.top(5))
[0, 1, 2]
[9, 8, 7, 6, 5]
# Pasa una función lambda a takeOrdered para invertir el orden
filteredRDD.takeOrdered(4, lambda s: -s)
[9, 8, 7, 6]
# Obtener la función add de Python
from operator import add
# Suma eficientemente el RDD usando reduce
print(filteredRDD.reduce(add))
# Suma usando reduce con una función lambda
print(filteredRDD.reduce(lambda a, b: a + b))
# Tenga en cuenta que la resta no es a la vez asociativa y conmutativa
print(filteredRDD.reduce(lambda a, b: a - b))
print(filteredRDD.repartition(4).reduce(lambda a, b: a - b))
# Mientras que la suma es
print(filteredRDD.repartition(4).reduce(lambda a, b: a + b))
45
45
-45
-45
45
(5b) Acciones avanzadas#
Aquí hay dos acciones adicionales que son útiles para recuperar información de un RDD: takeSample() y countByValue()#
La acción takeSample() devuelve un array con una muestra aleatoria de elementos del conjunto de datos. Toma un argumento withReplacement, que especifica si está permitido seleccionar aleatoriamente el mismo elemento varias veces del RDD principal (por lo que cuando withReplacement=True, puedes obtener el mismo elemento varias veces). También toma un parámetro opcional seed que te permite especificar un valor de semilla para el generador de números aleatorios, de modo que se puedan obtener resultados reproducibles.#
La acción countByValue() devuelve el conteo de cada valor único en el RDD como un diccionario que asigna valores a conteos.#
# takeSample reutilización de elementos
print(filteredRDD.takeSample(withReplacement=True, num=6))
# takeSample without reuse
print(filteredRDD.takeSample(withReplacement=False, num=6))
[4, 7, 5, 8, 4, 9]
[4, 0, 8, 6, 2, 3]
# Establecer semilla para la previsibilidad
print(filteredRDD.takeSample(withReplacement=False, num=6, seed=500))
# Intenta volver a ejecutar esta celda y la celda de arriba -- los resultados de esta celda permanecerán constantes
# Use ctrl-enter para correr sin moverse a la siguiente celda
[6, 4, 0, 1, 3, 5]
# Crear nuevo RDD base para mostrar countByValue
repetitiveRDD = sc.parallelize([1, 2, 3, 1, 2, 3, 1, 2, 1, 2, 3, 3, 3, 4, 5, 4, 6])
print(repetitiveRDD.countByValue())
defaultdict(<class 'int'>, {1: 4, 2: 4, 3: 5, 4: 2, 5: 1, 6: 1})
Part 6: Additional RDD transformations#
(6a) flatMap#
Para demostrar flatMap(), primero emitiremos una palabra junto con su plural, y luego un rango que crece en longitud con cada operación subsiguiente.#
# Vamos a crear un nuevo RDD base a partir del cual trabajar
wordsList = ['cat', 'elephant', 'rat', 'rat', 'cat']
wordsRDD = sc.parallelize(wordsList, 4)
# Use map
singularAndPluralWordsRDDMap = wordsRDD.map(lambda x: (x, x + 's'))
# Use flatMap
singularAndPluralWordsRDD = wordsRDD.flatMap(lambda x: (x, x + 's'))
# Ver los resultados
print(singularAndPluralWordsRDDMap.collect())
print(singularAndPluralWordsRDD.collect())
# Ver el número de elementos en el RDD
print(singularAndPluralWordsRDDMap.count())
print(singularAndPluralWordsRDD.count())
[('cat', 'cats'), ('elephant', 'elephants'), ('rat', 'rats'), ('rat', 'rats'), ('cat', 'cats')]
['cat', 'cats', 'elephant', 'elephants', 'rat', 'rats', 'rat', 'rats', 'cat', 'cats']
5
10
simpleRDD = sc.parallelize([2, 3, 4])
print(simpleRDD.map(lambda x: range(1, x)).collect())
print(simpleRDD.flatMap(lambda x: range(1, x)).collect())
[range(1, 2), range(1, 3), range(1, 4)]
[1, 1, 2, 1, 2, 3]
(6b) groupByKey y reduceByKey#
Vamos a investigar las transformaciones adicionales: groupByKey() y reduceByKey().#
Ambas transformaciones operan en RDDs de pares. Un RDD de pares es un RDD donde cada elemento es una tupla de pares (clave, valor). Por ejemplo, sc.parallelize([('a', 1), ('a', 2), ('b', 1)]) crearía un RDD de pares donde las claves son “a”, “a”, “b” y los valores son 1, 2, 1.#
La transformación reduceByKey() reúne pares que tienen la misma clave y aplica una función a dos valores asociados a la vez. reduceByKey() opera aplicando primero la función dentro de cada partición por clave y luego a través de las particiones.#
Observa el diagrama a continuación para entender cómo funciona reduceByKey. Observa cómo se combinan los pares en la misma máquina con la misma clave (usando la función lambda pasada a reduceByKey) antes de que los datos se redistribuyan. Luego, la función lambda se llama nuevamente para reducir todos los valores de cada partición y producir un resultado final.#
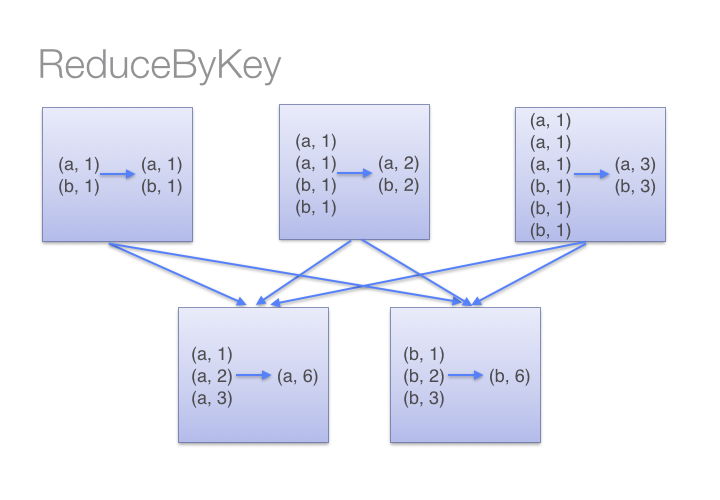
Por otro lado, al usar la transformación groupByKey(), todos los pares clave-valor se reorganizan, lo que provoca que se transfiera una gran cantidad de datos innecesarios a través de la red.#
Para determinar a qué máquina reorganizar un par, Spark llama a una función de particionamiento en la clave del par. Spark transfiere datos al disco cuando hay más datos reorganizados en una sola máquina ejecutora de los que pueden caber en memoria. Sin embargo, escribe los datos en el disco una clave a la vez, por lo que si una sola clave tiene más pares clave-valor de los que pueden caber en memoria, se produce una excepción de falta de memoria. Esto se manejará de manera más elegante en una versión posterior de Spark para que el trabajo aún pueda continuar, pero aún así debe evitarse. Cuando Spark necesita escribir en disco, el rendimiento se ve gravemente afectado.#
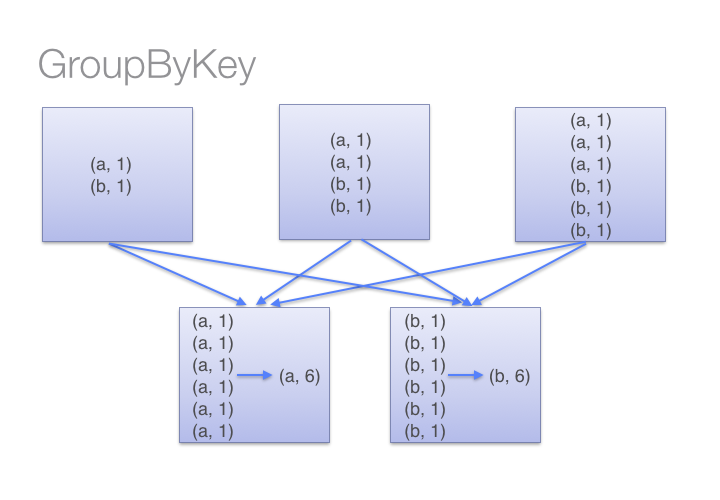
A medida que tu conjunto de datos crece, la diferencia en la cantidad de datos que necesitan ser reorganizados, entre las transformaciones reduceByKey() y groupByKey(), se vuelve cada vez más exagerada.#
Aquí hay más transformaciones que se prefieren sobre groupByKey():#
combineByKey() se puede usar cuando estás combinando elementos pero tu tipo de retorno difiere de tu tipo de valor de entrada.
foldByKey() combina los valores para cada clave utilizando una función asociativa y un «valor cero» neutral.
Ahora repasemos un ejemplo simple de groupByKey() y reduceByKey().#
pairRDD = sc.parallelize([('a', 1), ('a', 2), ('b', 1)])
# mapValues sólo se utiliza para mejorar el formato de impresión
print(pairRDD.groupByKey().mapValues(lambda x: list(x)).collect())
# Diferentes formas de sumar por tecla
print(pairRDD.groupByKey().map(lambda kv: (kv[0], sum(kv[1]))).collect())
# Usando mapValues, que se recomienda cuando la clave no cambia
print(pairRDD.groupByKey().mapValues(lambda x: sum(x)).collect())
# reduceByKey es más eficiente / escalable
print(pairRDD.reduceByKey(add).collect())
[('a', [1, 2]), ('b', [1])]
[('a', 3), ('b', 1)]
[('a', 3), ('b', 1)]
[('a', 3), ('b', 1)]
(6c) Transformaciones avanzadas [Opcional]#
Vamos a investigar las transformaciones avanzadas: mapPartitions() y mapPartitionsWithIndex()#
La transformación mapPartitions() utiliza una función que toma un iterador (para los elementos en esa partición específica) y devuelve un iterador. La función se aplica partición por partición.#
La transformación mapPartitionsWithIndex() utiliza una función que toma un índice de partición (piensa en esto como el número de partición) y un iterador (para los elementos en esa partición específica). Para cada par (índice, iterador) de partición, la función devuelve una tupla del mismo número de índice de partición y un iterador de los elementos transformados en esa partición.#
# mapPartitions toma una función que toma un iterador y devuelve un iterador
print(wordsRDD.collect())
itemsRDD = wordsRDD.mapPartitions(lambda iterator: [','.join(iterator)])
print(itemsRDD.collect())
['cat', 'elephant', 'rat', 'rat', 'cat']
['cat', 'elephant', 'rat', 'rat,cat']
itemsByPartRDD = wordsRDD.mapPartitionsWithIndex(lambda index, iterator: [(index, list(iterator))])
# Podemos ver que tres de los trabajadores (particiones) tienen un elemento y el cuarto trabajador tiene dos
# elementos, aunque las cosas no auguran nada bueno para la rata...
print(itemsByPartRDD.collect())
# Reejecutar sin devolver una lista (actúa más como flatMap)
itemsByPartRDD = wordsRDD.mapPartitionsWithIndex(lambda index, iterator: (index, list(iterator)))
print(itemsByPartRDD.collect())
[(0, ['cat']), (1, ['elephant']), (2, ['rat']), (3, ['rat', 'cat'])]
[0, ['cat'], 1, ['elephant'], 2, ['rat'], 3, ['rat', 'cat']]
Part 7: Caching RDDs and storage options#
(7a) Cacheo de RDDs#
Para mayor eficiencia, Spark mantiene tus RDDs en memoria. Al mantener el contenido en memoria, Spark puede acceder rápidamente a los datos. Sin embargo, la memoria es limitada, por lo que si intentas mantener demasiados RDDs en memoria, Spark eliminará automáticamente los RDDs de la memoria para hacer espacio para nuevos RDDs. Si luego haces referencia a uno de los RDDs, Spark lo recreará automáticamente, pero eso lleva tiempo.#
Entonces, si planeas usar un RDD más de una vez, deberías decirle a Spark que cachee ese RDD. Puedes usar la operación cache() para mantener el RDD en memoria. Sin embargo, si cacheas demasiados RDDs y Spark se queda sin memoria, eliminará primero el RDD menos utilizado recientemente (LRU). Nuevamente, el RDD se recreará automáticamente cuando se acceda a él.#
Puedes comprobar si un RDD está en caché utilizando el atributo is_cached, y puedes ver tu RDD en caché en la sección «Storage» de la interfaz web de Spark. Si haces clic en el nombre del RDD, puedes ver más información sobre dónde se almacena el RDD.#
# Nombrar el RDD
filteredRDD.setName('My Filtered RDD')
# Cache del RDD
filteredRDD.cache()
# Está en caché?
print(filteredRDD.is_cached)
True
(7b) Unpersist y opciones de almacenamiento#
Spark administra automáticamente los RDDs almacenados en memoria y los guardará en disco si se queda sin memoria. Para mayor eficiencia, una vez que hayas terminado de usar un RDD, puedes opcionalmente decirle a Spark que deje de almacenarlo en memoria utilizando el método unpersist() del RDD para informar a Spark que ya no necesitas el RDD en memoria.#
Puedes ver el conjunto de transformaciones que se aplicaron para crear un RDD utilizando el método toDebugString(), que proporcionará información de almacenamiento, y puedes consultar directamente la información de almacenamiento actual de un RDD utilizando la operación getStorageLevel().#
Avanzado: Spark proporciona muchas más opciones para gestionar cómo se almacenan los RDDs en memoria o incluso guardarlos en disco. Puedes explorar la API para la operación persist() de RDD utilizando el comando help() de Python. La operación persist(), opcionalmente, toma un objeto StorageLevel de pySpark.#
# Tenga en cuenta que toDebugString también proporciona información de almacenamiento
print(filteredRDD.toDebugString())
b'(8) My Filtered RDD PythonRDD[7] at collect at <ipython-input-36-bdec22de0542>:23 [Memory Serialized 1x Replicated]\n | ParallelCollectionRDD[0] at readRDDFromFile at PythonRDD.scala:289 [Memory Serialized 1x Replicated]'
# Si ya hemos terminado con el RDD podemos desempaquetarlo para que su memoria pueda ser recuperada
filteredRDD.unpersist()
# Nivel de almacenamiento para un RDD sin caché
print(filteredRDD.getStorageLevel())
filteredRDD.cache()
# Nivel de almacenamiento para un RDD en caché
print(filteredRDD.getStorageLevel())
Serialized 1x Replicated
Memory Serialized 1x Replicated