
Unidad 5 Big Data#
Big Data no es simplemente una palabra de moda para «muchos datos». Es un campo de la tecnología y una revolución estratégica que se ocupa de los métodos, herramientas y marcos para capturar, almacenar, procesar y, lo más importante, analizar conjuntos de datos que son tan masivos y complejos que superan las capacidades del software tradicional. 🌊
El verdadero poder del Big Data no reside en la cantidad de información, sino en la capacidad de descubrir patrones, tendencias, correlaciones y conocimientos ocultos que antes eran invisibles. Estos conocimientos permiten a las organizaciones tomar decisiones más inteligentes, optimizar operaciones, predecir comportamientos y crear nuevas oportunidades de negocio.
Orígenes: El Camino Hacia el Diluvio de Datos#
El concepto no surgió de la noche a la mañana. Es el resultado de una evolución tecnológica que comenzó hace décadas.
La Era Digital (1990s): Con la popularización de internet y los ordenadores personales, las empresas comenzaron a acumular datos de clientes y transacciones en bases de datos relacionales. Nació el concepto de Data Warehousing (almacenamiento de datos) para centralizar esta información.
La Explosión de la Web (2000s): El auge de las redes sociales, los blogs y el comercio electrónico provocó una avalancha de datos no estructurados (texto, imágenes, clics). Las bases de datos tradicionales no estaban diseñadas para manejar esta variedad y volumen.
La Solución de Google (2003-2004): Google se enfrentaba a un problema monumental: cómo indexar toda la World Wide Web. Para resolverlo, desarrollaron y publicaron dos documentos revolucionarios: uno sobre un sistema de archivos distribuido (Google File System - GFS) y otro sobre un modelo de programación paralela (MapReduce). Estas tecnologías permitían dividir una tarea masiva entre miles de ordenadores económicos.
El Nacimiento de Hadoop (2006): Inspirados por los documentos de Google, los ingenieros Doug Cutting y Mike Cafarella crearon Apache Hadoop, un proyecto de código abierto que implementaba los conceptos de GFS y MapReduce. Esto democratizó el poder del procesamiento distribuido, permitiendo a cualquier empresa (no solo a Google) construir sus propias plataformas de Big Data.
Las 5 V’s del Big Data: Las Dimensiones de la Complejidad#
Para comprender la naturaleza del Big Data, el modelo de las 5 V’s es fundamental. Cada “V” representa un desafío y una dimensión única.
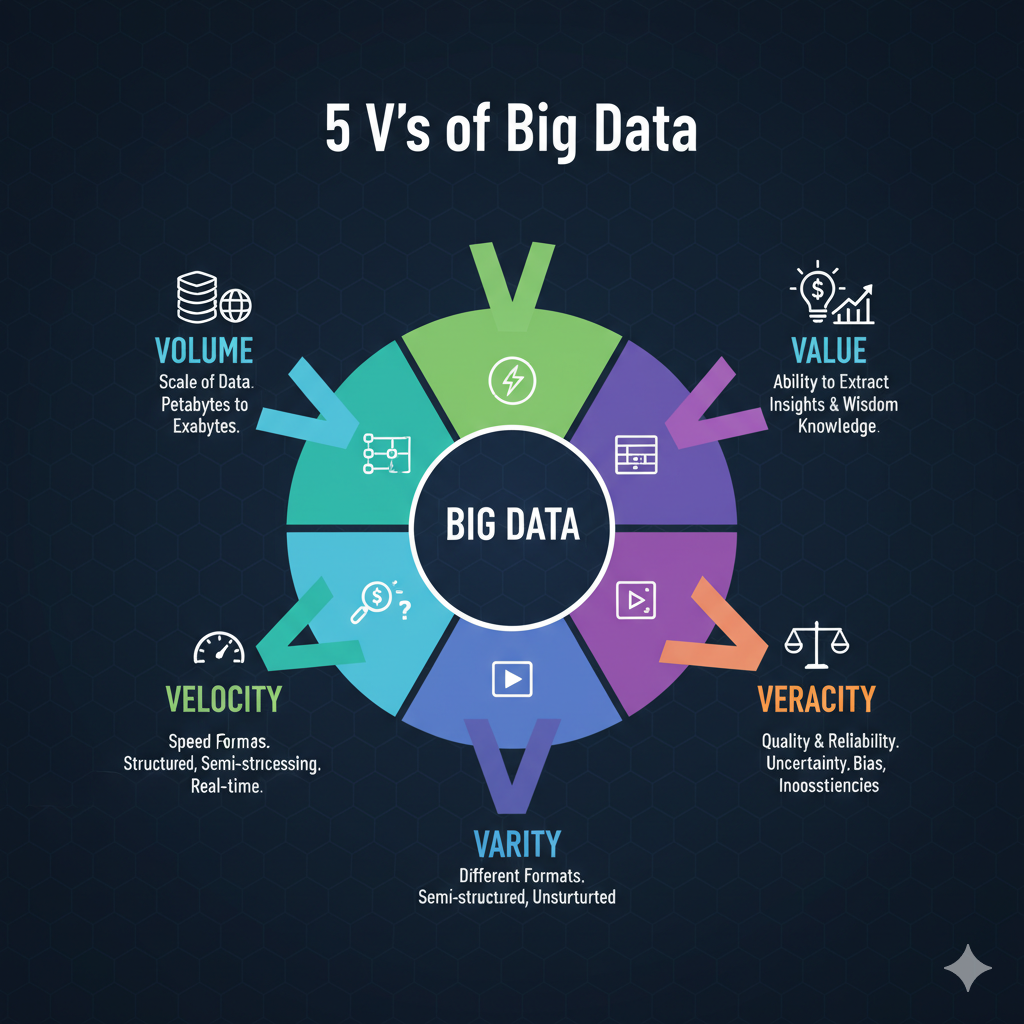
1. Volumen (Volume) 📊#
Se refiere a la escala monumental de los datos. Ya no hablamos de Megabytes o Gigabytes, sino de Terabytes, Petabytes, Exabytes y más allá.
Fuentes: Datos de sensores de la «Internet de las Cosas» (IoT), transacciones financieras globales, registros de actividad de redes sociales, datos genómicos, videos de alta definición, etc.
Desafío: ¿Cómo almacenamos de forma económica y accesible esta cantidad masiva de información? Los sistemas de almacenamiento distribuido como HDFS (Hadoop Distributed File System) o servicios en la nube son la respuesta.
2. Velocidad (Velocity) ⚡#
Mide la rapidez con la que se generan y se deben procesar los datos. El análisis en tiempo real es crucial para muchas aplicaciones modernas.
Fuentes: Transmisiones de datos de mercados bursátiles, detección de fraudes en transacciones con tarjetas de crédito, análisis de clics en un sitio web, monitoreo de redes sociales para tendencias virales.
Desafío: Se necesitan tecnologías de streaming como Apache Kafka, Spark Streaming o Flink para ingerir y procesar datos «al vuelo» a medida que llegan, en lugar de esperar a almacenarlos primero.
3. Variedad (Variety) 🎭#
Describe la diversidad de formatos de datos. El Big Data abarca mucho más que simples tablas numéricas.
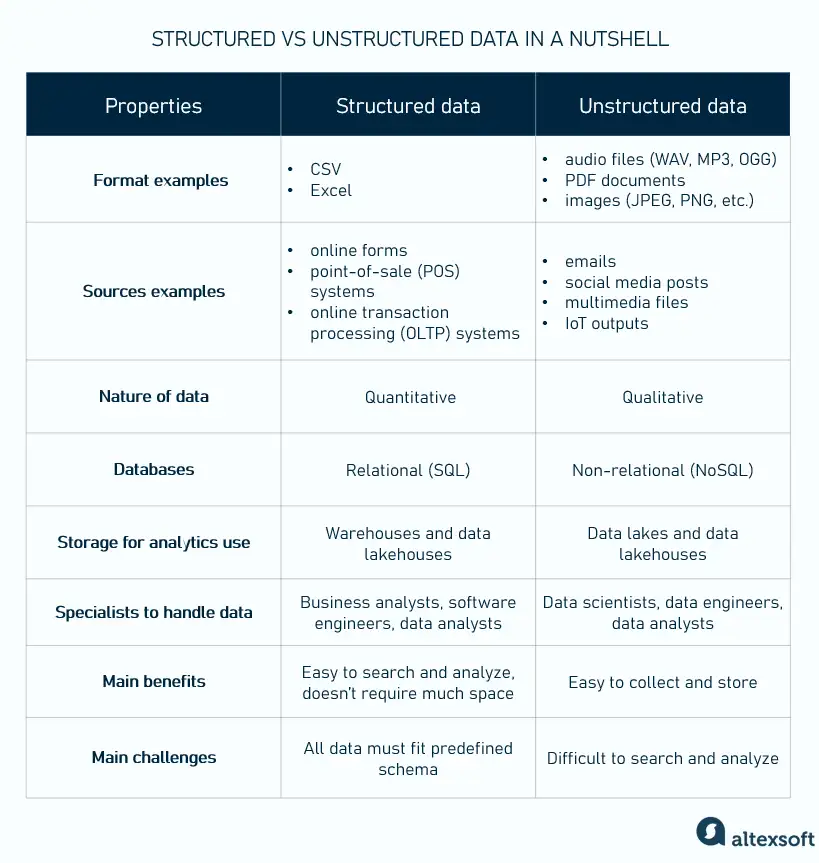
Datos Estructurados: Altamente organizados en filas y columnas, como una hoja de cálculo o una base de datos SQL.
Datos Semi-estructurados: No se ajustan a un modelo de datos formal pero contienen etiquetas o marcadores para separar elementos, como archivos JSON, XML o correos electrónicos.
Datos No Estructurados: Forman más del 80% de los datos del mundo. No tienen una estructura interna predefinida. Incluyen texto libre, imágenes, videos, archivos de audio y publicaciones en redes sociales.
Desafío: Se requieren herramientas flexibles como las bases de datos NoSQL (por ejemplo, MongoDB para documentos o Cassandra para columnas anchas) y técnicas de procesamiento de lenguaje natural (NLP) o visión por computadora para extraer significado de estos formatos.
4. Veracidad (Veracity) 🤔#
Se refiere a la calidad, fiabilidad y precisión de los datos. La información puede ser ruidosa, incompleta, ambigua o inconsistente. «Basura entra, basura sale»: si los datos no son fiables, los análisis tampoco lo serán.
Fuentes de Incertidumbre: Errores humanos en la entrada de datos, fallos en sensores, datos faltantes, sarcasmo o noticias falsas en redes sociales.
Desafío: Requiere procesos robustos de limpieza de datos (Data Cleaning), gobernanza de datos (Data Governance) y validación para asegurar que se está trabajando con información de alta calidad.
5. Valor (Value) 💎#
Esta es la V más crítica. El objetivo final de recolectar, almacenar y analizar Big Data es extraer valor tangible. El valor puede ser económico, social, estratégico o científico.
Ejemplos de Valor:
Comercial: Aumentar las ventas a través de recomendaciones personalizadas (Amazon, Netflix).
Operacional: Optimizar rutas de entrega para ahorrar combustible (UPS, FedEx).
Científico: Acelerar la investigación genómica para descubrir curas para enfermedades.
Social: Predecir brotes de enfermedades analizando búsquedas en internet o publicaciones en redes sociales.
Desafío: No se trata solo de tener la tecnología, sino de hacer las preguntas correctas y tener la experiencia analítica (científicos de datos) para convertir los datos brutos en conocimiento accionable.
Aplicaciones en el Mundo Real#
El Big Data está transformando prácticamente todas las industrias:
Comercio y Marketing: Análisis del comportamiento del cliente para crear campañas publicitarias personalizadas, optimizar precios y gestionar inventarios.
Salud y Medicina: Medicina de precisión basada en el genoma del paciente, predicción de epidemias, análisis de imágenes médicas para diagnósticos más rápidos y precisos.
Finanzas: Detección de fraudes en tiempo real, análisis de riesgo crediticio, trading algorítmico de alta frecuencia.
Ciudades Inteligentes (Smart Cities): Optimización del tráfico mediante el análisis de datos de sensores y GPS, gestión eficiente de la energía y los residuos, mejora de la seguridad pública.
Industria y Manufactura (Industria 4.0): Mantenimiento predictivo de maquinaria analizando datos de sensores para prever fallos antes de que ocurran.
Los Grandes Retos del Big Data#
A pesar de sus beneficios, trabajar con Big Data presenta desafíos significativos:
Almacenamiento e Infraestructura: El costo y la complejidad de mantener la infraestructura física o en la nube para almacenar y procesar petabytes de datos son altos.
Seguridad y Privacidad: Proteger grandes volúmenes de datos sensibles (personales, financieros, de salud) contra ciberataques y garantizar el cumplimiento de regulaciones como GDPR es un desafío monumental.
Calidad y Gobernanza de Datos: Asegurar la veracidad y consistencia de los datos a través de toda la organización es una tarea continua y compleja.
Escasez de Talento: Existe una alta demanda de profesionales con las habilidades necesarias (científicos de datos, ingenieros de datos, analistas) para construir y gestionar sistemas de Big Data y extraer valor de ellos.