Manos a la obra! 👨💻#
Te damos la bienvenida a Colab
Si ya conoces Colab, mira este video para aprender sobre las tablas interactivas, la vista histórica de código ejecutado y la paleta de comandos.

¿Qué es Colab?
Colab, o “Colaboratory”, te permite escribir y ejecutar código de Python en tu navegador, con
Una configuración lista para que empieces a programar
Acceso gratuito a GPU
Facilidad para compartir
Seas estudiante, científico de datos o investigador de IA, Colab facilita tu trabajo. Mira este video introductorio sobre Colab para obtener más información, o bien comienza a usarlo más abajo.
Comandos básicos de Python#
# Imprimir un mensaje
print("Hola, mundo")
Hola, mundo
# Hacer cálculos básicos
segundos_en_un_dia = 24 * 60 * 60
segundos_en_un_dia
86400
type(segundos_en_un_dia)
int
# Variables
x = 10
y = 20
z = x + y
print(z)
30
# Listas
mi_lista = [1, 2, 3, 4, 5]
print(mi_lista)
[1, 2, 3, 4, 5]
# Bucles
for i in mi_lista:
print(i)
1
2
3
4
5
# Condicionales
if x < y:
print("x es menor que y")
else:
print("x no es menor que y")
x es menor que y
nombre = input("Ingresa tu nombre: ")
print("\n Hola "+nombre+" como estás?")
Ingresa tu nombre:
Hola como estás?
Ejercicio Práctico: Procesemos algo con Pandas#
Carguemos una base de datos#
El data set es el resultado de realizar un web scraping a una página web que contiene avisos de ventas de viviendas en Chile, y fue realizado con el fin de poder aprender su metodología.
Los datos que contiene son los valores de únicamente CASAS USADAS que se venden en la región metropolitana de Chile y que están publicado en el sitio web https://chilepropiedades.cl/ en la primera semana de mayo de 2020
import pandas as pd
df = pd.read_csv("https://raw.githubusercontent.com/BioAITeamLearning/Taller_introPython/main/data/Casas_RM_Mayo_2020_Con_Coordenadas.csv")
df.head()
| Comuna | Link | Tipo_Vivienda | N_Habitaciones | N_Baños | N_Estacionamientos | Total_Superficie_M2 | Superficie_Construida_M2 | Valor_UF | Valor_CLP | Dirección | Quién_Vende | Corredor | Latitud (Decimal) | Longitud (decimal) | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Calera de Tango | https://chilepropiedades.cl/ver-publicacion/ve... | Casa | 5.0 | 6.0 | 3 | 5000 | 440 | 12.2 | 351360000 | Calera de Tango, Queilen | Gabriela Mellado V. | Zenpro Propiedades | -33.6278 | -70.785 |
| 1 | Calera de Tango | https://chilepropiedades.cl/ver-publicacion/ve... | Casa | 6.0 | 6.0 | 6 | 5000 | 430 | 13.0 | 374400000 | Calera de Tango, Queilen | Gabriela Mellado V. | Zenpro Propiedades | -33.6278 | -70.785 |
| 2 | Calera de Tango | https://chilepropiedades.cl/ver-publicacion/ve... | Casa | 3.0 | 3.0 | No | 2027 | 140 | 10.3 | 296640000 | Calera de Tango, Avenida calera de tango con... | Alonso Baeza Rivera y Cía. Ltda. (Kennedy) | Alonso Baeza Rivera y Cía. Ltda. (Kennedy) | -33.6278 | -70.785 |
| 3 | Calera de Tango | https://chilepropiedades.cl/ver-publicacion/ve... | Casa | 8.0 | 6.0 | No | 5000 | 480 | 21.5 | 619200000 | Calera de Tango, Paradero 14 1/2/5 kilometros ... | RED Gestión Propiedades | Red Gestión Propiedades | -33.6278 | -70.785 |
| 4 | Calera de Tango | https://chilepropiedades.cl/ver-publicacion/ve... | Casa | 3.0 | 2.0 | 3 | 5000 | 196 | 9.1 | 262080000 | Calera de Tango, Condominio El Trébol de Caler... | Gabriela Mellado V. | Zenpro Propiedades | -33.6278 | -70.785 |
# Revisemos cada una de las caracteristicas.
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1139 entries, 0 to 1138
Data columns (total 15 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Comuna 1139 non-null object
1 Link 1139 non-null object
2 Tipo_Vivienda 1139 non-null object
3 N_Habitaciones 1131 non-null float64
4 N_Baños 1118 non-null float64
5 N_Estacionamientos 1067 non-null object
6 Total_Superficie_M2 1102 non-null object
7 Superficie_Construida_M2 1103 non-null object
8 Valor_UF 1139 non-null float64
9 Valor_CLP 1139 non-null int64
10 Dirección 1102 non-null object
11 Quién_Vende 1139 non-null object
12 Corredor 1139 non-null object
13 Latitud (Decimal) 1139 non-null float64
14 Longitud (decimal) 1139 non-null float64
dtypes: float64(5), int64(1), object(9)
memory usage: 133.6+ KB
# Revisemos las muestras que son NaN en la base de datos x columna
df.isna().sum()
Comuna 0
Link 0
Tipo_Vivienda 0
N_Habitaciones 8
N_Baños 21
N_Estacionamientos 72
Total_Superficie_M2 37
Superficie_Construida_M2 36
Valor_UF 0
Valor_CLP 0
Dirección 37
Quién_Vende 0
Corredor 0
Latitud (Decimal) 0
Longitud (decimal) 0
dtype: int64
Limpieza de datos#
# Eliminemos columnas que no necesitaremos
df.dropna(inplace=True)
# y quitemos la del enlace que no es útil
df.drop(['Link'],axis=1,inplace=True)
df.isna().sum()
Comuna 0
Tipo_Vivienda 0
N_Habitaciones 0
N_Baños 0
N_Estacionamientos 0
Total_Superficie_M2 0
Superficie_Construida_M2 0
Valor_UF 0
Valor_CLP 0
Dirección 0
Quién_Vende 0
Corredor 0
Latitud (Decimal) 0
Longitud (decimal) 0
dtype: int64
Visualización de datos en python#
Barras#
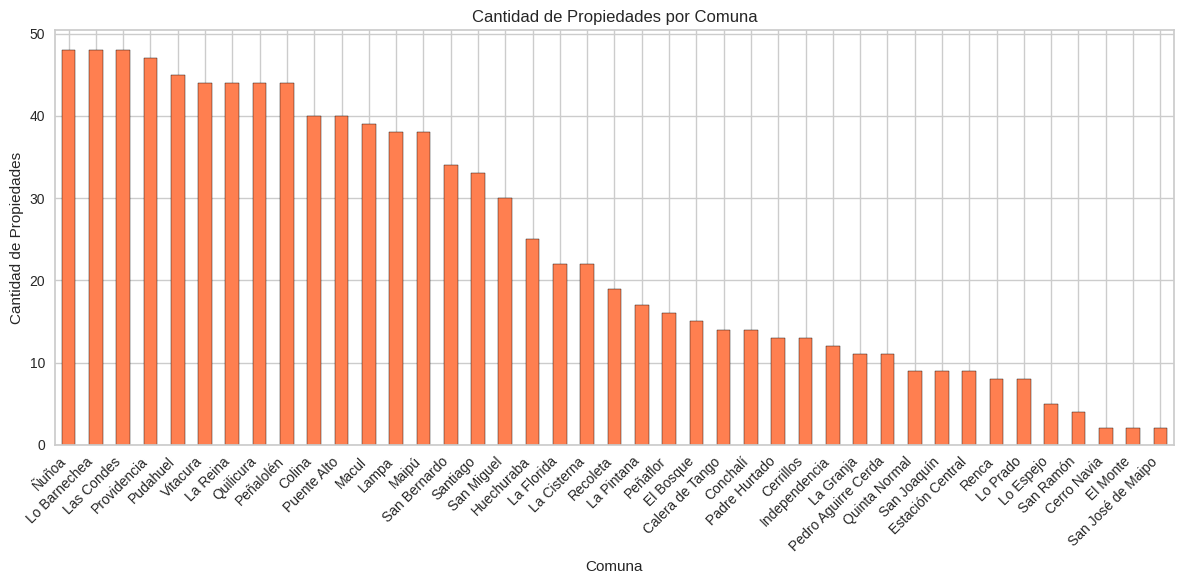
import matplotlib.pyplot as plt
import pandas as pd
plt.figure(figsize=(12, 6))
# Graficar la cantidad de casas por comuna
df['Comuna'].value_counts().plot(kind='bar', color='coral', edgecolor='black')
# Agregar algunos datos a la gráfica resultante
plt.title('Cantidad de Propiedades por Comuna')
plt.xlabel('Comuna')
plt.ylabel('Cantidad de Propiedades')
plt.xticks(rotation=45, ha='right')
plt.tight_layout()
plt.show()
Histograma#
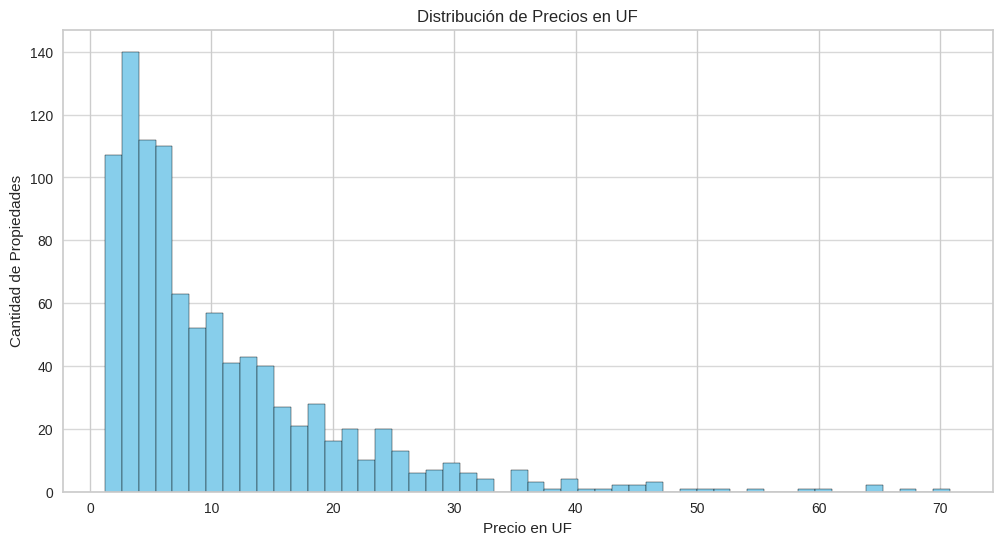
# Generamos la figura donde vamos a trabajar
plt.figure(figsize=(12, 6))
# Usamos pandas para graficar los datos de la columna en forma de histograma
df[' Valor_UF '].dropna().astype(float).plot(kind='hist', bins=50, color='skyblue', edgecolor='black')
# Agregamos información al gráfico para mejor visualización
plt.title('Distribución de Precios en UF')
plt.xlabel('Precio en UF')
plt.ylabel('Cantidad de Propiedades')
plt.grid(axis='y', alpha=0.75)
plt.show()
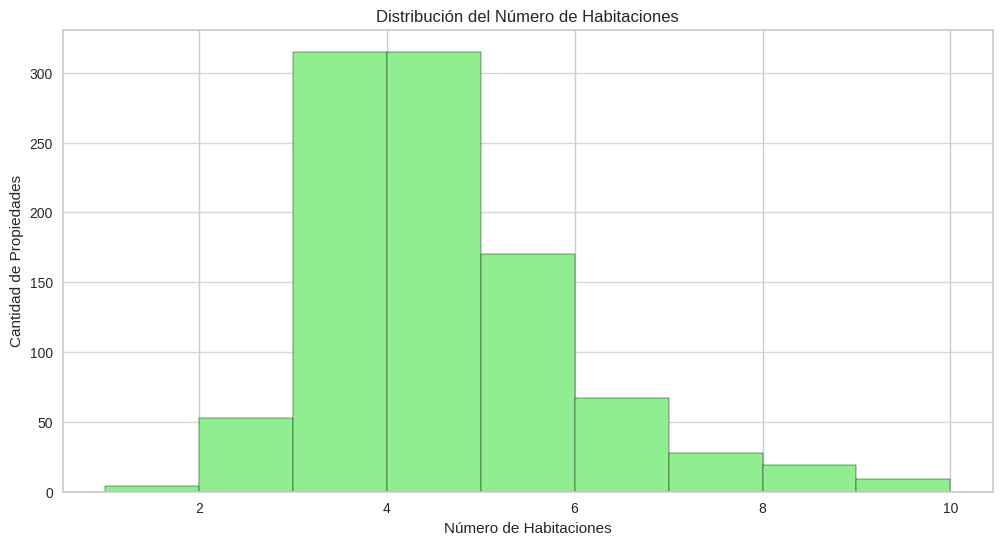
plt.figure(figsize=(12, 6))
# Graficar el histograma de la cantidad de habitaciones de las casas
df['N_Habitaciones'].dropna().astype(int).plot(kind='hist', bins=range(1,11), color='lightgreen', edgecolor='black')
# Agregar Información a la imágen
plt.title('Distribución del Número de Habitaciones')
plt.xlabel('Número de Habitaciones')
plt.ylabel('Cantidad de Propiedades')
plt.grid(axis='y', alpha=0.75)
plt.show()
Torta#
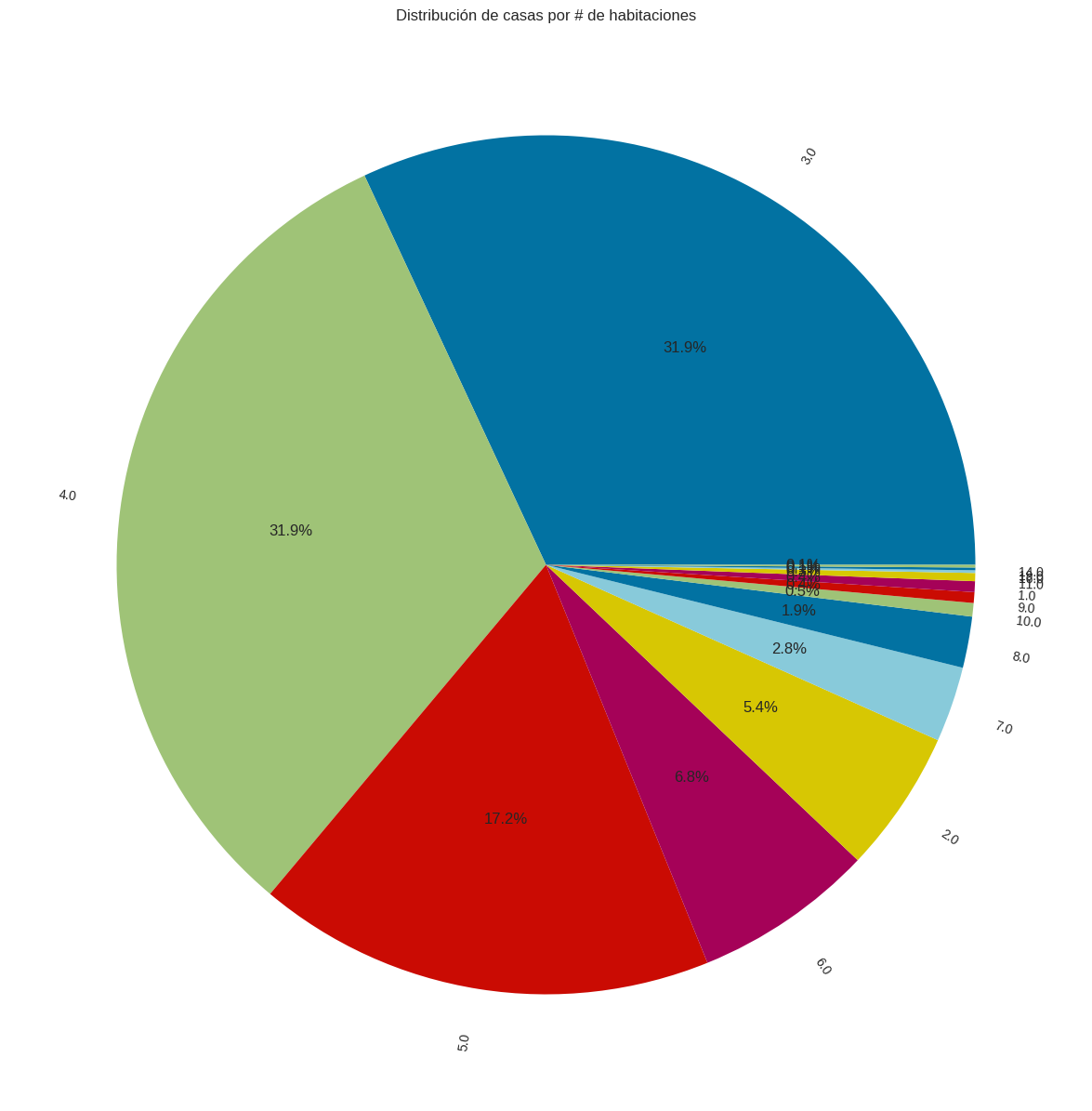
# Calculamos las frecuencias de cada tipo de vivienda
N_habs = df['N_Habitaciones'].value_counts()
plt.figure(figsize=(15, 15))
# Realizamos un gráfico de torta
plt.pie(N_habs, labels=N_habs.index, autopct='%1.1f%%',rotatelabels=True)
# Añadir información a la gráfica.
plt.title('Distribución de casas por # de habitaciones')
plt.show()
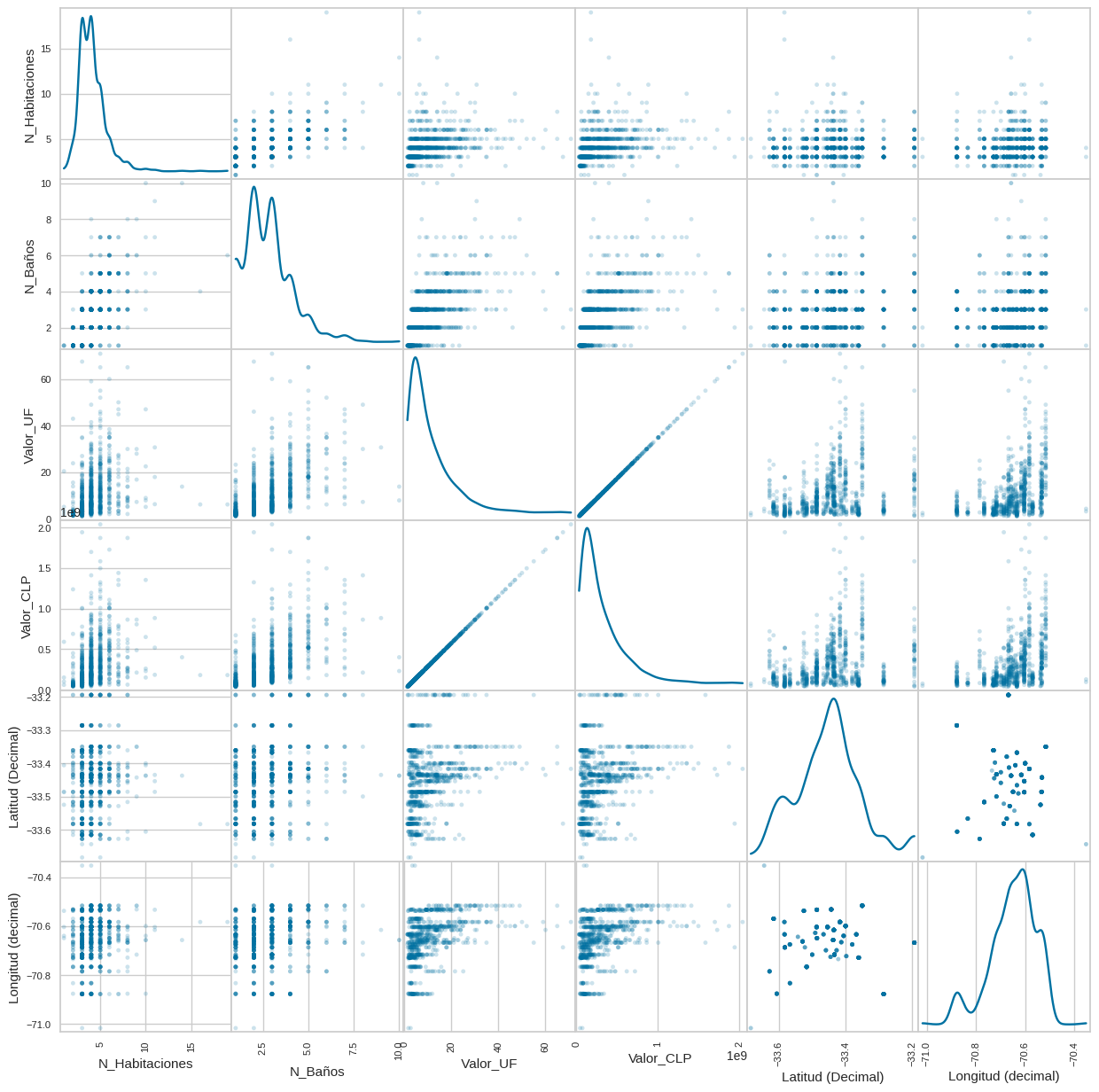
Scatter de caracteristicas#
from pandas.plotting import scatter_matrix
import matplotlib.pyplot as plt
# Seleccionamos solo las columnas numéricas del DataFrame
df_numeric = df.select_dtypes(include=['float64', 'int64'])
# Crea el scatter matrix
scatter_matrix(df_numeric, alpha=0.2, figsize=(15, 15), diagonal='kde')
plt.show()
Visualización de datos geográficos#
!pip install folium
Requirement already satisfied: folium in /usr/local/lib/python3.10/dist-packages (0.14.0)
Requirement already satisfied: branca>=0.6.0 in /usr/local/lib/python3.10/dist-packages (from folium) (0.7.1)
Requirement already satisfied: jinja2>=2.9 in /usr/local/lib/python3.10/dist-packages (from folium) (3.1.3)
Requirement already satisfied: numpy in /usr/local/lib/python3.10/dist-packages (from folium) (1.25.2)
Requirement already satisfied: requests in /usr/local/lib/python3.10/dist-packages (from folium) (2.31.0)
Requirement already satisfied: MarkupSafe>=2.0 in /usr/local/lib/python3.10/dist-packages (from jinja2>=2.9->folium) (2.1.5)
Requirement already satisfied: charset-normalizer<4,>=2 in /usr/local/lib/python3.10/dist-packages (from requests->folium) (3.3.2)
Requirement already satisfied: idna<4,>=2.5 in /usr/local/lib/python3.10/dist-packages (from requests->folium) (3.6)
Requirement already satisfied: urllib3<3,>=1.21.1 in /usr/local/lib/python3.10/dist-packages (from requests->folium) (2.0.7)
Requirement already satisfied: certifi>=2017.4.17 in /usr/local/lib/python3.10/dist-packages (from requests->folium) (2024.2.2)
import pandas as pd
# Convertimos a float las columnas necesarias
df['Latitud (Decimal)'] = pd.to_numeric(df['Latitud (Decimal)'], errors='coerce')
df['Longitud (decimal)'] = pd.to_numeric(df['Longitud (decimal)'], errors='coerce')
df['N_Habitaciones'] = pd.to_numeric(df['N_Habitaciones'], errors='coerce')
# Agrupamos por comuna para sumar las habitaciones y calcular la latitud y longitud promedio
df_grouped = df.groupby('Comuna').agg({
'N_Habitaciones': 'count',
'Latitud (Decimal)': 'mean',
'Longitud (decimal)': 'mean'
}).reset_index()
import folium
# Crear el mapa base, centrado en una ubicación general de la Región Metropolitana
mapa = folium.Map(location=[-33.45, -70.65], zoom_start=11)
# Añadir marcadores para cada comuna
for _, row in df_grouped.iterrows():
folium.Marker(
location=[row['Latitud (Decimal)'], row['Longitud (decimal)']],
popup=f"{row['Comuna']}: {row['N_Habitaciones']} casas",
icon=folium.Icon(color='blue', icon='info-sign')
).add_to(mapa)
# Guardar el mapa en un archivo HTML
mapa.save('mapa_habitaciones_por_comuna.html')
mapa
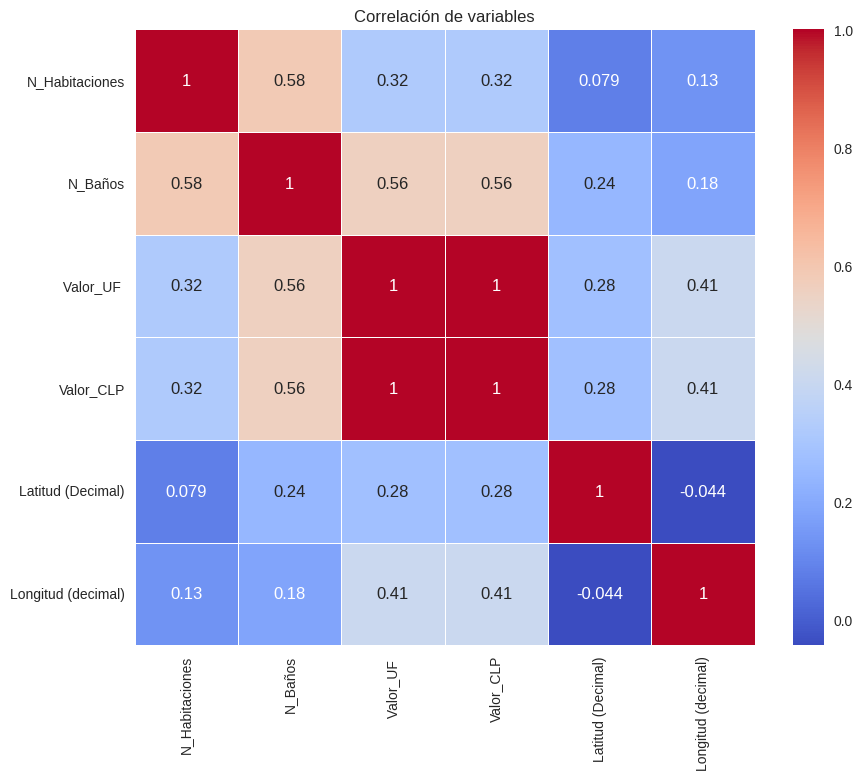
Análisis de correlación de las variables#
corr = df.corr()
corr
<ipython-input-353-4381f08f6434>:1: FutureWarning: The default value of numeric_only in DataFrame.corr is deprecated. In a future version, it will default to False. Select only valid columns or specify the value of numeric_only to silence this warning.
corr = df.corr()
| N_Habitaciones | N_Baños | Valor_UF | Valor_CLP | Latitud (Decimal) | Longitud (decimal) | |
|---|---|---|---|---|---|---|
| N_Habitaciones | 1.000000 | 0.584381 | 0.322528 | 0.322528 | 0.078896 | 0.134136 |
| N_Baños | 0.584381 | 1.000000 | 0.558939 | 0.558935 | 0.242203 | 0.181163 |
| Valor_UF | 0.322528 | 0.558939 | 1.000000 | 1.000000 | 0.276380 | 0.408451 |
| Valor_CLP | 0.322528 | 0.558935 | 1.000000 | 1.000000 | 0.276366 | 0.408457 |
| Latitud (Decimal) | 0.078896 | 0.242203 | 0.276380 | 0.276366 | 1.000000 | -0.043786 |
| Longitud (decimal) | 0.134136 | 0.181163 | 0.408451 | 0.408457 | -0.043786 | 1.000000 |
Visualicemos un poco mejor esto#
import seaborn as sns
corr = df.corr()
plt.figure(figsize=(10, 8)) # Puedes ajustar el tamaño según tus necesidades
sns.heatmap(corr,
xticklabels=corr.columns,
yticklabels=corr.columns,
cmap='coolwarm', # Elige el mapa de colores que prefieras
annot=True, # Muestra los valores de correlación
linewidths=.5) # Ajusta el espaciado entre las celdas si es necesario
plt.title("Correlación de variables")
plt.show()
<ipython-input-354-74421bbed24f>:3: FutureWarning: The default value of numeric_only in DataFrame.corr is deprecated. In a future version, it will default to False. Select only valid columns or specify the value of numeric_only to silence this warning.
corr = df.corr()
Preparemos todo para entrenar un modelo de ML#
df.info()
<class 'pandas.core.frame.DataFrame'>
Int64Index: 986 entries, 0 to 1138
Data columns (total 14 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Comuna 986 non-null object
1 Tipo_Vivienda 986 non-null object
2 N_Habitaciones 986 non-null float64
3 N_Baños 986 non-null float64
4 N_Estacionamientos 986 non-null object
5 Total_Superficie_M2 986 non-null object
6 Superficie_Construida_M2 986 non-null object
7 Valor_UF 986 non-null float64
8 Valor_CLP 986 non-null int64
9 Dirección 986 non-null object
10 Quién_Vende 986 non-null object
11 Corredor 986 non-null object
12 Latitud (Decimal) 986 non-null float64
13 Longitud (decimal) 986 non-null float64
dtypes: float64(5), int64(1), object(8)
memory usage: 115.5+ KB
# Vamos a limpiar estas variables ya se supone que sean numéricas
variables_a_limpiar = ["N_Estacionamientos","Total_Superficie_M2","Superficie_Construida_M2"]
variables_a_limpiar
for variable in variables_a_limpiar:
df[variable] = pd.to_numeric(df[variable], errors='coerce')
# Eliminar las variables que no nos aportan información relevante y que son categoricas
df.drop(["Tipo_Vivienda","Corredor","Quién_Vende","Dirección"],axis=1,inplace=True)
# Rellenamos los campos NaN con 0
df.fillna(0, inplace=True)
df.info()
<class 'pandas.core.frame.DataFrame'>
Int64Index: 986 entries, 0 to 1138
Data columns (total 10 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Comuna 986 non-null object
1 N_Habitaciones 986 non-null float64
2 N_Baños 986 non-null float64
3 N_Estacionamientos 986 non-null float64
4 Total_Superficie_M2 986 non-null float64
5 Superficie_Construida_M2 986 non-null float64
6 Valor_UF 986 non-null float64
7 Valor_CLP 986 non-null int64
8 Latitud (Decimal) 986 non-null float64
9 Longitud (decimal) 986 non-null float64
dtypes: float64(8), int64(1), object(1)
memory usage: 84.7+ KB
Transformación de columnas categoricas#
# Realicemos el one-hot encoding
df_dummies = pd.get_dummies(df['Comuna'])
df_dummies.head()
| Calera de Tango | Cerrillos | Cerro Navia | Colina | Conchalí | El Bosque | El Monte | Estación Central | Huechuraba | Independencia | ... | Recoleta | Renca | San Bernardo | San Joaquín | San José de Maipo | San Miguel | San Ramón | Santiago | Vitacura | Ñuñoa | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 3 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 4 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
5 rows × 41 columns
# Agreguemos la información nueva a la tabla axistente
df_final = pd.concat([df.drop('Comuna',axis=1), df_dummies], axis=1)
df_final.head()
| N_Habitaciones | N_Baños | N_Estacionamientos | Total_Superficie_M2 | Superficie_Construida_M2 | Valor_UF | Valor_CLP | Latitud (Decimal) | Longitud (decimal) | Calera de Tango | ... | Recoleta | Renca | San Bernardo | San Joaquín | San José de Maipo | San Miguel | San Ramón | Santiago | Vitacura | Ñuñoa | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 5.0 | 6.0 | 3.0 | 5000.0 | 440.0 | 12.2 | 351360000 | -33.6278 | -70.785 | 1 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 6.0 | 6.0 | 6.0 | 5000.0 | 430.0 | 13.0 | 374400000 | -33.6278 | -70.785 | 1 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 3.0 | 3.0 | 0.0 | 2027.0 | 140.0 | 10.3 | 296640000 | -33.6278 | -70.785 | 1 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 3 | 8.0 | 6.0 | 0.0 | 5000.0 | 480.0 | 21.5 | 619200000 | -33.6278 | -70.785 | 1 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 4 | 3.0 | 2.0 | 3.0 | 5000.0 | 196.0 | 9.1 | 262080000 | -33.6278 | -70.785 | 1 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
5 rows × 50 columns
Dividamos Caracteristicas y Variable Objetivo#
#Variables independientes
x = df_final.drop(' Valor_UF ', axis=1)
#Variables dependientes
y = df_final[' Valor_UF '] # Nuestra variable objetivo es Unidad de Fomento (UF)
#división en conjunto de entrenamiento y test
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3, random_state=42)
print("Set de entrenamiento: ", x_train.shape)
print("Set de test: ", x_test.shape)
Set de entrenamiento: (690, 49)
Set de test: (296, 49)
Entrenar modelos de Machine learning#
Entrenamiento Decision Tree#
from sklearn.metrics import r2_score
from sklearn.tree import DecisionTreeRegressor
from sklearn.ensemble import RandomForestRegressor
#Inicializando el modelo
dtr = DecisionTreeRegressor(random_state=42, max_depth=5)
#Entrenamiento del modelo
dtr.fit(x_train, y_train)
DecisionTreeRegressor(max_depth=5, random_state=42)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
DecisionTreeRegressor(max_depth=5, random_state=42)
#Predicciones con el set de prueba
prediccion_dtr = dtr.predict(x_test)
# Imprimimos predicciones
prediccion_dtr
array([ 9.69177143, 1.94347368, 5.80548889, 11.71455 , 3.35825 ,
15.21857143, 11.71455 , 1.94347368, 6.629 , 9.69177143,
13.89 , 11.71455 , 20.14022222, 7.66089655, 3.35825 ,
18.37534783, 26.93915385, 5.80548889, 7.66089655, 5.01680769,
6.629 , 12.82755 , 2.75167797, 2.75167797, 6.629 ,
11.71455 , 4.16434091, 32.1945 , 5.01680769, 2.75167797,
12.82755 , 16.43182353, 5.80548889, 20.14022222, 18.37534783,
3.35825 , 29.87383333, 3.35825 , 11.71455 , 3.35825 ,
3.35825 , 7.66089655, 9.69177143, 6.629 , 10.676 ,
13.89 , 9.69177143, 15.21857143, 10.676 , 6.629 ,
2.75167797, 12.82755 , 1.94347368, 5.01680769, 12.82755 ,
6.629 , 13.89 , 4.16434091, 7.66089655, 20.14022222,
5.01680769, 8.85592 , 29.87383333, 32.1945 , 5.80548889,
29.87383333, 22.12208333, 4.16434091, 5.01680769, 22.12208333,
9.69177143, 26.93915385, 4.16434091, 1.94347368, 45.7225 ,
10.676 , 4.16434091, 1.94347368, 4.16434091, 1.94347368,
8.85592 , 15.21857143, 5.01680769, 9.69177143, 3.35825 ,
18.37534783, 29.87383333, 4.16434091, 2.75167797, 20.14022222,
6.629 , 1.94347368, 4.16434091, 9.69177143, 9.69177143,
5.01680769, 9.69177143, 5.01680769, 7.66089655, 24.20704762,
20.14022222, 3.35825 , 12.82755 , 29.87383333, 13.89 ,
6.629 , 7.66089655, 18.37534783, 3.35825 , 20.14022222,
10.676 , 1.94347368, 7.66089655, 26.93915385, 9.69177143,
3.35825 , 3.35825 , 12.82755 , 6.629 , 8.85592 ,
16.43182353, 10.676 , 7.66089655, 6.629 , 8.85592 ,
1.94347368, 12.82755 , 39.0098 , 1.94347368, 5.80548889,
13.89 , 13.89 , 24.20704762, 24.20704762, 2.75167797,
39.0098 , 5.01680769, 5.80548889, 18.37534783, 32.1945 ,
7.66089655, 10.676 , 11.71455 , 39.0098 , 18.37534783,
4.16434091, 4.16434091, 8.85592 , 22.12208333, 7.66089655,
1.94347368, 6.629 , 32.1945 , 13.89 , 12.82755 ,
10.676 , 4.16434091, 4.16434091, 2.75167797, 29.87383333,
1.94347368, 7.66089655, 5.80548889, 6.629 , 9.69177143,
3.35825 , 4.16434091, 6.629 , 16.43182353, 13.89 ,
11.71455 , 12.82755 , 26.93915385, 5.01680769, 12.82755 ,
1.94347368, 18.37534783, 6.629 , 9.69177143, 7.66089655,
1.94347368, 15.21857143, 8.85592 , 18.37534783, 1.94347368,
5.80548889, 32.1945 , 9.69177143, 12.82755 , 5.80548889,
4.16434091, 7.66089655, 4.16434091, 1.94347368, 16.43182353,
18.37534783, 1.94347368, 18.37534783, 2.75167797, 24.20704762,
3.35825 , 10.676 , 2.75167797, 12.82755 , 26.93915385,
2.75167797, 50.495 , 16.43182353, 5.80548889, 6.629 ,
24.20704762, 18.37534783, 16.43182353, 26.93915385, 6.629 ,
6.629 , 5.01680769, 6.629 , 2.75167797, 5.80548889,
5.80548889, 11.71455 , 4.16434091, 42.66333333, 11.71455 ,
18.37534783, 1.94347368, 3.35825 , 10.676 , 4.16434091,
34.93666667, 5.80548889, 2.75167797, 1.94347368, 7.66089655,
11.71455 , 1.94347368, 29.87383333, 3.35825 , 12.82755 ,
6.629 , 4.16434091, 8.85592 , 1.94347368, 6.629 ,
22.12208333, 16.43182353, 13.89 , 20.14022222, 4.16434091,
7.66089655, 8.85592 , 15.21857143, 8.85592 , 5.01680769,
10.676 , 29.87383333, 4.16434091, 5.80548889, 22.12208333,
13.89 , 6.629 , 18.37534783, 2.75167797, 9.69177143,
4.16434091, 20.14022222, 4.16434091, 6.629 , 13.89 ,
4.16434091, 1.94347368, 5.80548889, 5.01680769, 24.20704762,
13.89 , 2.75167797, 6.629 , 4.16434091, 8.85592 ,
7.66089655, 50.495 , 4.16434091, 7.66089655, 22.12208333,
13.89 , 6.629 , 3.35825 , 16.43182353, 1.94347368,
15.21857143, 4.16434091, 7.66089655, 11.71455 , 8.85592 ,
16.43182353])
Visualizar el error de predicciones#
from yellowbrick.regressor import PredictionError
fig, ax = plt.subplots(figsize=(8, 8))
pev = PredictionError(dtr)
pev.fit(x_train, y_train)
pev.score(x_test, y_test)
pev.poof()
/usr/local/lib/python3.10/dist-packages/sklearn/base.py:439: UserWarning: X does not have valid feature names, but DecisionTreeRegressor was fitted with feature names
warnings.warn(
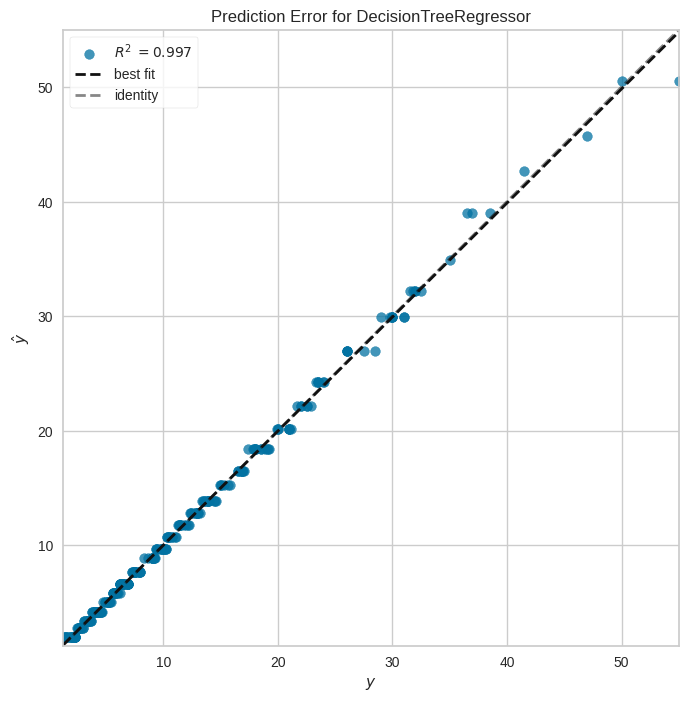
<Axes: title={'center': 'Prediction Error for DecisionTreeRegressor'}, xlabel='$y$', ylabel='$\\hat{y}$'>
# Revisemos la métrica de r^2
r2_score(y_test, prediccion_dtr)
0.9970209956128195
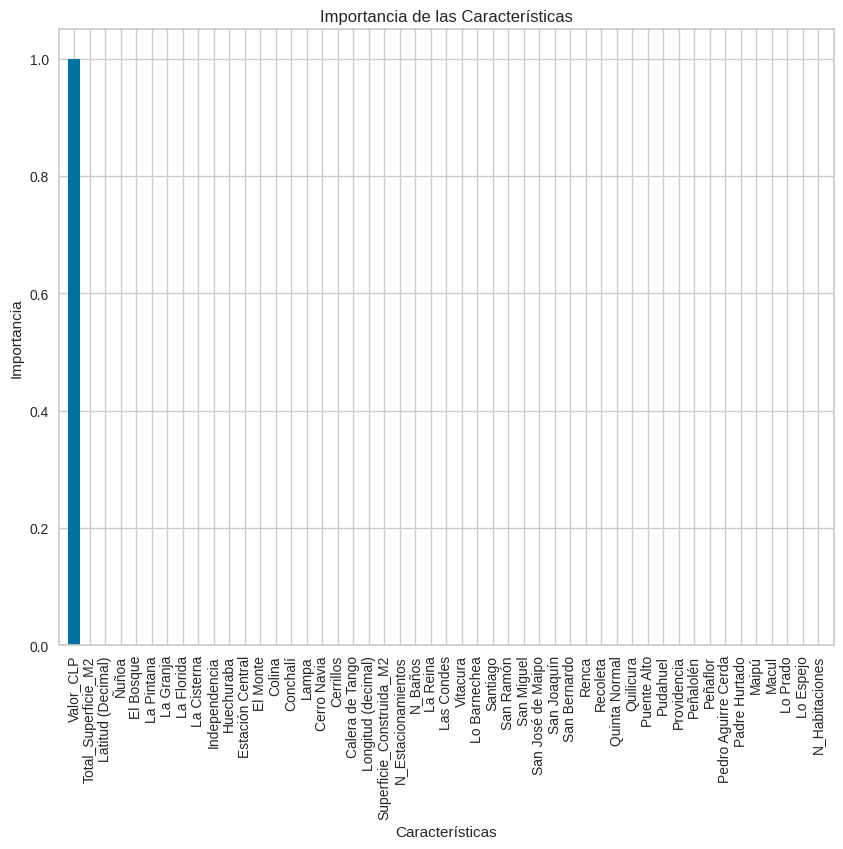
Realicemos un análisis de relevancia#
import numpy as np
import matplotlib.pyplot as plt
# Obteniendo la importancia de las características
importancias = dtr.feature_importances_
# Nombres de las características (asumiendo que x tiene nombres de columnas)
nombres_caracteristicas = x.columns
# Ordenamos las características por importancia (de mayor a menor)
indices_ordenados = np.argsort(importancias)[::-1]
# Visualización de la importancia de las características
plt.figure(figsize=(10, 8))
plt.title("Importancia de las Características")
plt.bar(range(x.shape[1]), importancias[indices_ordenados], color="b", align="center")
# Añadir nombres de las características como etiquetas en el eje x
plt.xticks(range(x.shape[1]), nombres_caracteristicas[indices_ordenados], rotation=90)
plt.xlim([-1, x.shape[1]])
plt.ylabel("Importancia")
plt.xlabel("Características")
plt.show()
Entrenamiento Random Forest#
# Definamos el modelo a usar
rf = RandomForestRegressor(random_state=42, max_depth=5, n_estimators=10)
# Entrenemos el modelo
rf.fit(x_train, y_train)
RandomForestRegressor(max_depth=5, n_estimators=10, random_state=42)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
RandomForestRegressor(max_depth=5, n_estimators=10, random_state=42)
# Realicemos predicciones con el conjunto de test
prediccion_rf = rf.predict(x_test)
# Revisemos la gráfica de error de predicción
fig, ax = plt.subplots(figsize=(8, 8))
pev = PredictionError(rf)
pev.fit(x_train, y_train)
pev.score(x_test, y_test)
pev.poof()
/usr/local/lib/python3.10/dist-packages/sklearn/base.py:439: UserWarning: X does not have valid feature names, but RandomForestRegressor was fitted with feature names
warnings.warn(
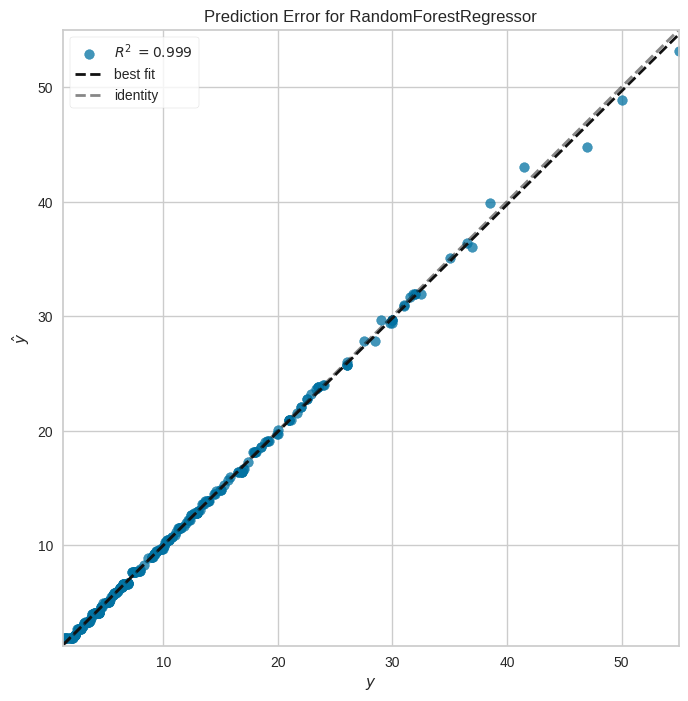
<Axes: title={'center': 'Prediction Error for RandomForestRegressor'}, xlabel='$y$', ylabel='$\\hat{y}$'>
# Analicemos la métrica de r^2
r2_score(y_test, prediccion_rf)
0.9989933865704962
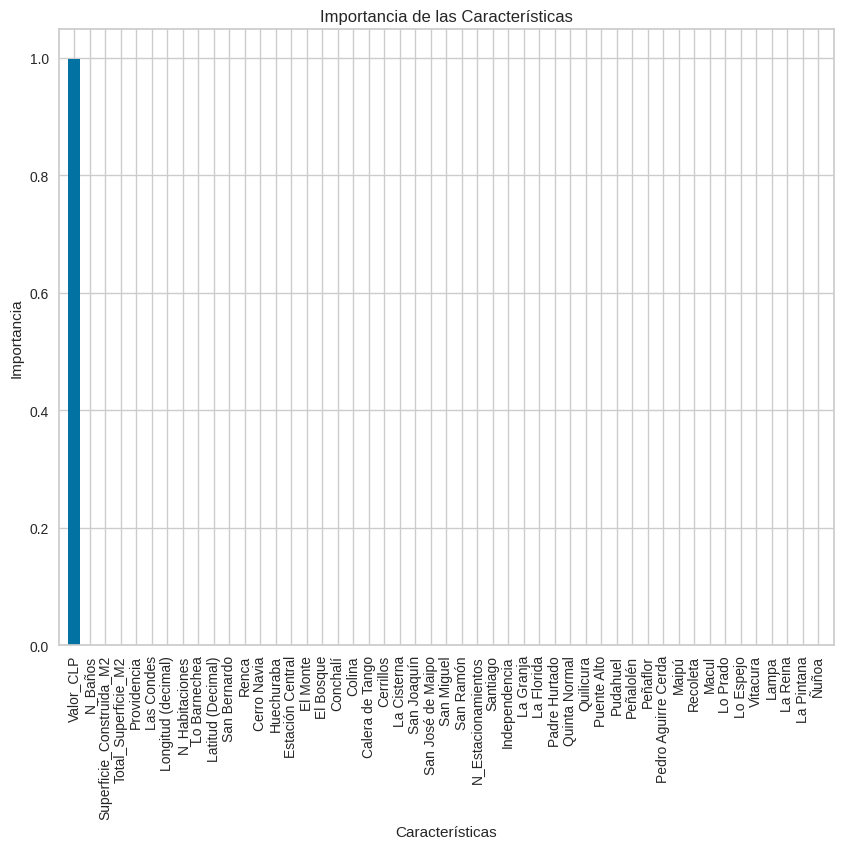
Realicemos análisis de relevancia del modelo#
import numpy as np
import matplotlib.pyplot as plt
# Obteniendo la importancia de las características
importancias = rf.feature_importances_
# Nombres de las características (asumiendo que x tiene nombres de columnas)
nombres_caracteristicas = x.columns
# Ordenamos las características por importancia (de mayor a menor)
indices_ordenados = np.argsort(importancias)[::-1]
# Visualización de la importancia de las características
plt.figure(figsize=(10, 8))
plt.title("Importancia de las Características")
plt.bar(range(x.shape[1]), importancias[indices_ordenados], color="b", align="center")
# Añadir nombres de las características como etiquetas en el eje x
plt.xticks(range(x.shape[1]), nombres_caracteristicas[indices_ordenados], rotation=90)
plt.xlim([-1, x.shape[1]])
plt.ylabel("Importancia")
plt.xlabel("Características")
plt.show()
Actividad#
Probemos eliminando la variable con más relevancia de la base de datos y re-entrenemos los modelos para ver su comportamiento…