
Manejo de archivos#
Lectura y escritura de archivos#
Manejo de archivos txt#
En diferentes aplicaciones es fundamental realizar manejo de archivos, tanto para el almacenamiento de información como para la carga de información de la aplicación general. Python ofrece un conjunto de funciones que hacen parte de la librería estándar y permiten la manipulación de archivos de texto plano. A continuación veremos el uso de las principales funciones.
Para abrir un archivo:
filepath = ‘ruta_del_archivo’
file = open(‘filepath/filename.txt’,’modo’)
Como se puede observar un archivo puede abrirse en diferentes modos:
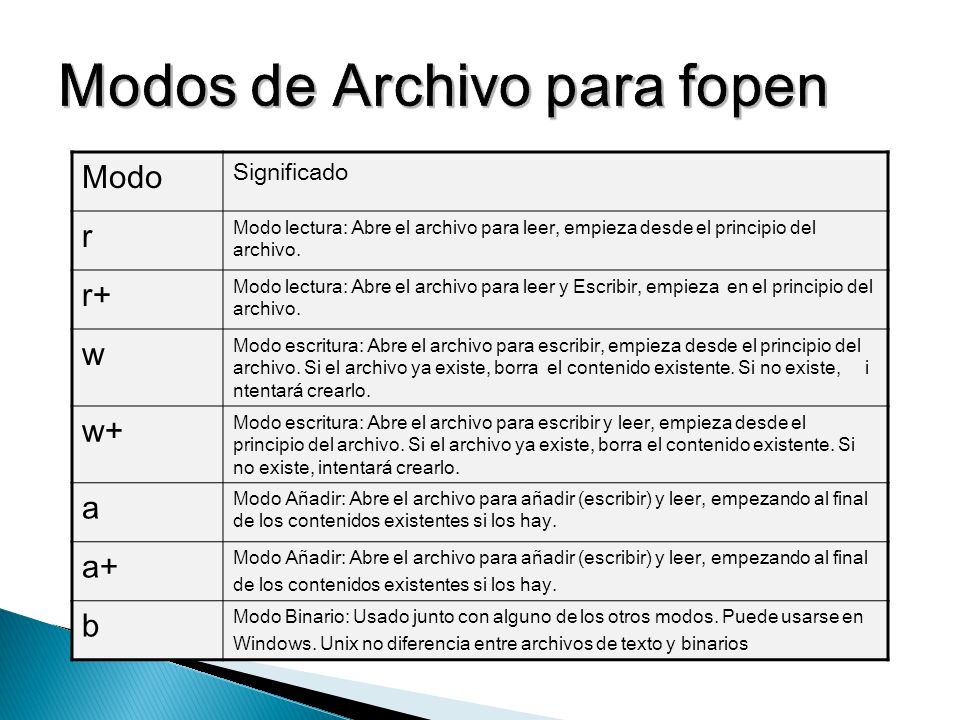
Para usar esta librería, en primer lugar crearemos un archivo desde cero, esto se puede hacer con los modos (x) o (w). Verifique cual es la diferencia entre ambos
# Crear un archivo
folder='sample_data'
fileName = 'miArchivo'
fileExtension= 'txt'
filePath = folder + '/' + fileName + '.' + fileExtension
open(filePath,'x')
<_io.TextIOWrapper name='sample_data/miArchivo.txt' mode='x' encoding='UTF-8'>
Podrá verificar que después de ejecutar las líneas anteriores se crea un archivo en la carpeta sample_data. A continuación abriremos el archivo en módulo (w) para escribir algo en él.
file = open(filePath,'w')
Ahora con el archivo abierto, podemos escribir la información que se contenga en otra estructura, por ejemplo una lista.
miLista = [‘Hola’,’mundo’]
miLista = ['Hola','mundo']
for i in range(10):
for palabra in miLista:
file.write(palabra+'\t')
file.write('\n')
Luego de procesar un archivo es necesario cerrarlo para que esté disponible para otras aplicaciones.
file.close()
En este momento haga el ejercicio de descargar el archivo y abrirlo desde su computador con un bloc de notas. Podra ver algo como lo siguiente:

A partir de este archivo se pueden agregar nuevas líneas, para ello utilizaremos el modo (a), supongamos la siguiente tupla:
miTupla = (‘Loren’,’ipsum’,’dolor’,’at’,’met’)
miTupla = ('Loren','ipsum','dolor','at','met')
file = open(filePath,'a')
for palabra in miTupla:
file.write(palabra+' ')
file.close()
Lectura de archivos#
Ahora que ya tenemos un archivo creado y con contenido podemos abrirlo para leerlo.
file = open(filePath,'r')
lista = list()
for linea in file:
#print(type(linea))
lista.append(linea)
print(linea)
file.close()
print(lista)
Hola mundo
Hola mundo
Hola mundo
Hola mundo
Hola mundo
Hola mundo
Hola mundo
Hola mundo
Hola mundo
Hola mundo
Loren ipsum dolor at met
['Hola\tmundo\t\n', 'Hola\tmundo\t\n', 'Hola\tmundo\t\n', 'Hola\tmundo\t\n', 'Hola\tmundo\t\n', 'Hola\tmundo\t\n', 'Hola\tmundo\t\n', 'Hola\tmundo\t\n', 'Hola\tmundo\t\n', 'Hola\tmundo\t\n', 'Loren ipsum dolor at met ']
Lecto - escritura de archivos#
Existen modos de lectoescritura como w+, r+ y a+
## Lecto - escritura de archivos
f=open(filePath,"r+")
x=f.readlines()
print(x)
print(type(x))
f.write("\n Esto es otra línea")
f.close()
['Hola\tmundo\t\n', 'Hola\tmundo\t\n', 'Hola\tmundo\t\n', 'Hola\tmundo\t\n', 'Hola\tmundo\t\n', 'Hola\tmundo\t\n', 'Hola\tmundo\t\n', 'Hola\tmundo\t\n', 'Hola\tmundo\t\n', 'Hola\tmundo\t\n', 'Loren ipsum dolor at met ']
<class 'list'>
##Leyendo archivos CSV
Los CSV corresponden con filas de datos separados por comas. Lo ideal para el trabajo con estos datos, es el uso de la librería Pandas. Para ello debe importarse dicha librería:
folder='sample_data'
fileName = 'mnist_test'
fileExtension= 'csv'
filePath = folder + '/' + fileName + '.' + fileExtension
f=open(filePath,'r')
x=f.readable()
import pandas as pd
Luego debe indicarse la ubicación del archivo. Acá en colab debe buscarse en la parte izquierda el ícono de la carpeta. Allí se encuentran los directorios propios del colab. Por defecto hay una carpeta con datos de prueba sample_data. En este directorio se pueden agregar otras bases de datos. De momento podemos cargar la base de datos denominada: california_housing_test.csv
# Indicar la ubicación de los archivos
filepath = 'sample_data/california_housing_test.csv'
# Importar los datos
data = pd.read_csv(filepath)
Luego, podemos verificar la existencia de estos datos.
# Imprimir algunas filas
print(data.iloc[:4])
longitude latitude housing_median_age total_rooms total_bedrooms \
0 -122.05 37.37 27.0 3885.0 661.0
1 -118.30 34.26 43.0 1510.0 310.0
2 -117.81 33.78 27.0 3589.0 507.0
3 -118.36 33.82 28.0 67.0 15.0
population households median_income median_house_value
0 1537.0 606.0 6.6085 344700.0
1 809.0 277.0 3.5990 176500.0
2 1484.0 495.0 5.7934 270500.0
3 49.0 11.0 6.1359 330000.0
Otras formas de abrir archivos con pandas involucran:
Uso de diferentes delimitadores#
data = pd.read_csv(filepath,sep=’\t’)
data = pd.read_csv(filepath,delim_whitespace=True)
No usar la primera fila que contiene los nombres#
data = pd.read_csv(filepath,header=None)
Especificar los nombres de las columnas#
data = pd.read_csv(filepath,names = [‘Nombre1’,’Nombre2’])
print(data.iloc[:3])
Manipulación de valores perdidos#
data = pd.read_csv(filepath,na_values=[‘NA,99])
Leyendo archivos JSON#
Estos archivos se utilizan ampliamente en APIs de sitios web. En apariencia son similares a los diccionarios de Python, pues almacenan los datos a manera de clave y valor. Al igual que en el caso de CSV la mejor alternativa para leer estos archivos es mediante Pandas. En este caso utilizaremos el archivo anscombe.json
import json
with open('sample_data/anscombe.json') as json_file:
data = json.load(json_file)
print(data)
[{'Series': 'I', 'X': 10.0, 'Y': 8.04}, {'Series': 'I', 'X': 8.0, 'Y': 6.95}, {'Series': 'I', 'X': 13.0, 'Y': 7.58}, {'Series': 'I', 'X': 9.0, 'Y': 8.81}, {'Series': 'I', 'X': 11.0, 'Y': 8.33}, {'Series': 'I', 'X': 14.0, 'Y': 9.96}, {'Series': 'I', 'X': 6.0, 'Y': 7.24}, {'Series': 'I', 'X': 4.0, 'Y': 4.26}, {'Series': 'I', 'X': 12.0, 'Y': 10.84}, {'Series': 'I', 'X': 7.0, 'Y': 4.81}, {'Series': 'I', 'X': 5.0, 'Y': 5.68}, {'Series': 'II', 'X': 10.0, 'Y': 9.14}, {'Series': 'II', 'X': 8.0, 'Y': 8.14}, {'Series': 'II', 'X': 13.0, 'Y': 8.74}, {'Series': 'II', 'X': 9.0, 'Y': 8.77}, {'Series': 'II', 'X': 11.0, 'Y': 9.26}, {'Series': 'II', 'X': 14.0, 'Y': 8.1}, {'Series': 'II', 'X': 6.0, 'Y': 6.13}, {'Series': 'II', 'X': 4.0, 'Y': 3.1}, {'Series': 'II', 'X': 12.0, 'Y': 9.13}, {'Series': 'II', 'X': 7.0, 'Y': 7.26}, {'Series': 'II', 'X': 5.0, 'Y': 4.74}, {'Series': 'III', 'X': 10.0, 'Y': 7.46}, {'Series': 'III', 'X': 8.0, 'Y': 6.77}, {'Series': 'III', 'X': 13.0, 'Y': 12.74}, {'Series': 'III', 'X': 9.0, 'Y': 7.11}, {'Series': 'III', 'X': 11.0, 'Y': 7.81}, {'Series': 'III', 'X': 14.0, 'Y': 8.84}, {'Series': 'III', 'X': 6.0, 'Y': 6.08}, {'Series': 'III', 'X': 4.0, 'Y': 5.39}, {'Series': 'III', 'X': 12.0, 'Y': 8.15}, {'Series': 'III', 'X': 7.0, 'Y': 6.42}, {'Series': 'III', 'X': 5.0, 'Y': 5.73}, {'Series': 'IV', 'X': 8.0, 'Y': 6.58}, {'Series': 'IV', 'X': 8.0, 'Y': 5.76}, {'Series': 'IV', 'X': 8.0, 'Y': 7.71}, {'Series': 'IV', 'X': 8.0, 'Y': 8.84}, {'Series': 'IV', 'X': 8.0, 'Y': 8.47}, {'Series': 'IV', 'X': 8.0, 'Y': 7.04}, {'Series': 'IV', 'X': 8.0, 'Y': 5.25}, {'Series': 'IV', 'X': 19.0, 'Y': 12.5}, {'Series': 'IV', 'X': 8.0, 'Y': 5.56}, {'Series': 'IV', 'X': 8.0, 'Y': 7.91}, {'Series': 'IV', 'X': 8.0, 'Y': 6.89}]
# Con pandas
# Establecer la ruta del archivo
filepath = 'sample_data/anscombe.json'
# Leer el archivo JSON
data = pd.read_json(filepath)
# Verificar los datos
print(data.iloc[:3])
Series X Y
0 I 10 8.04
1 I 8 6.95
2 I 13 7.58
Observe que ocurre si ejecuta las siguientes líneas:
Escribir un archivo JSON a partir de un dataframe:
data.to_json(‘mi_archivojson.json’)
data.to_json('mi_archivojson.json')
Lectura de bases de datos SQL#
Para importar datos de SQL es necesario importar una librería adicional denominada sqlite3
import sqlite3 as sq
# definimos la ruta
filepath = 'Data/Ejemplobasedatos.db'
# se genera una conexión con la base de datos
connection = sq.Connection(filepath)
# se escribe una consulta
query = '''SELECT * FROM alumnos;'''
# se ejecuta la consulta
data = pd.read_sql(query, connection)
print(data.iloc[:3])
dni nombre Primer_parcial Segundo_parcial
0 11111111A juan 7.9 8.9
1 22222222B ana 5.7 8.9
2 33333333L alma 6.9 7.8
Lectura datos a través de API’s#
Algunos sitios web permiten obtener datos a través de sus API’s (Application Programming Interfaces), este tipo de acceso permite obtener y manipular fácilmente la información mediante Python.
Veamos un ejemplo:
# UCI IRIS Data Base
dataURL = 'https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data'
# Leer datos con Pandas
database = pd.read_csv(dataURL, header=0)
print(database.iloc[:3])
5.1 3.5 1.4 0.2 Iris-setosa
0 4.9 3.0 1.4 0.2 Iris-setosa
1 4.7 3.2 1.3 0.2 Iris-setosa
2 4.6 3.1 1.5 0.2 Iris-setosa