
Unidad 2: Arquitecturas para computación paralela#
Contenido de la unidad#
Arquitectura de memoria en computación paralela#
Taxonomía de Flynn#
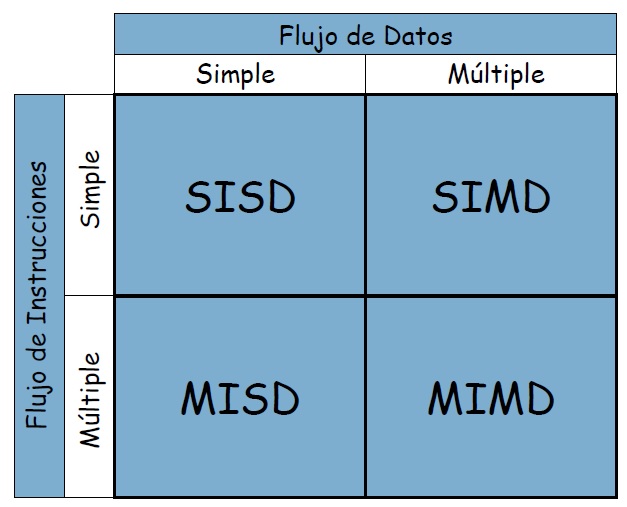
SISD: El procesador ejecuta una única instrucción en una única pieza de datos en cada ciclo de reloj. - Ordenador.
MISD: Múltiples procesadores ejecutan diferentes instrucciones en el mismo conjunto de datos. Un ejemplo de un sistema MISD es un sistema de detección de fallas de seguridad en tiempo real, en el que varias instrucciones de verificación se ejecutan simultáneamente en la misma pieza de datos para detectar cualquier falla.
SIMD: En este caso, el procesador ejecuta la misma instrucción en varios datos diferentes en cada ciclo de reloj - GPU
MIMD: Múltiples procesadores ejecutan diferentes instrucciones en diferentes conjuntos de datos al mismo tiempo. clúster de servidores que ejecutan aplicaciones separadas en cada servidor, pero se comunican entre sí para realizar una tarea común.
SISD
En un ciclo del reloj:

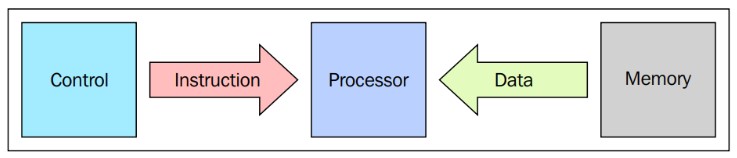
Ejemplo

MISD
Poco práctico comercialmente
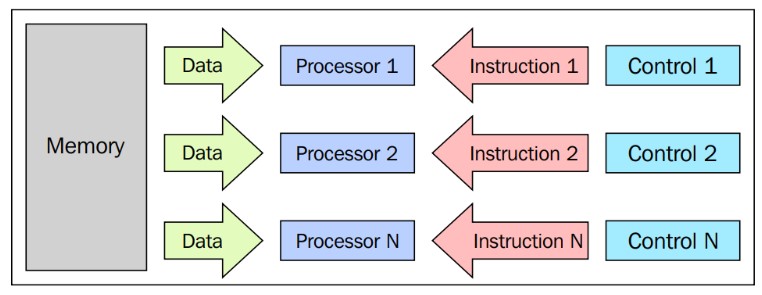
SIMD
En este se basa la arquitectura de la GPU
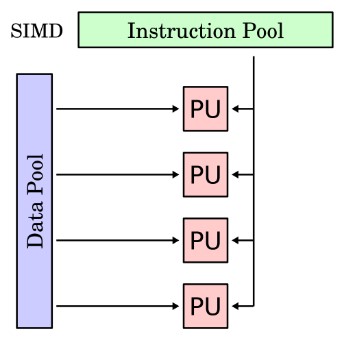
Ejemplo

El procesamiento de imágenes y video se utiliza en una variedad de aplicaciones, como la televisión digital, la realidad aumentada y la vigilancia de seguridad. Para procesar grandes cantidades de datos de imagen y video, se utilizan procesadores SIMD que pueden procesar múltiples datos simultáneamente.
MIMD
Arquitectura aplicada en supercomputadores.
Async algorithms
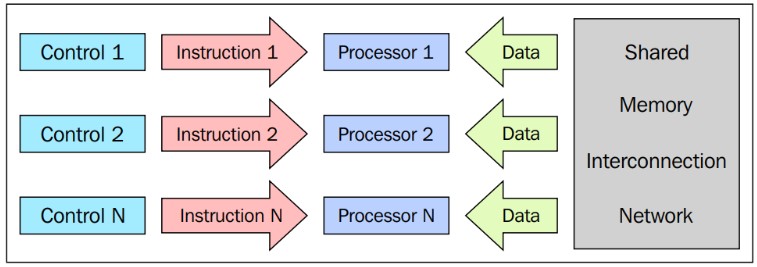
Ejemplo

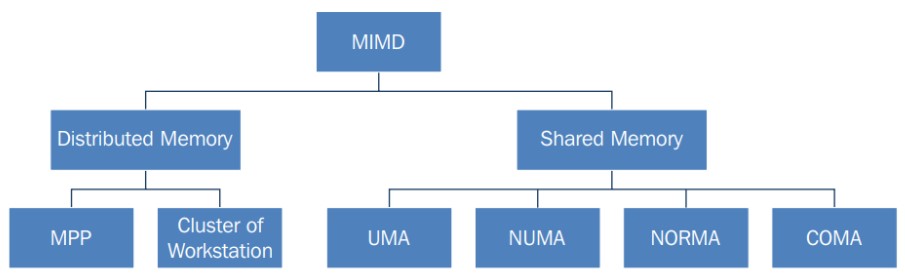
Organización de la memoria#
En la arquitectura MIMD
Memoria Compartida#
Misma memoria para todos los procesadores.
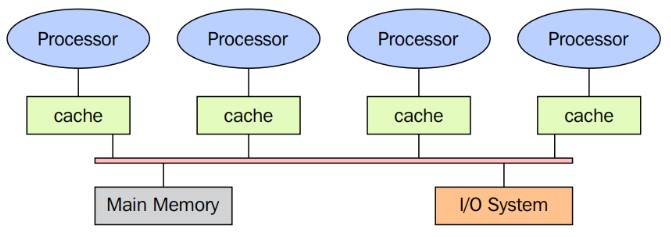
La memoria es la misma para todos los procesadores.
Solo un procesador puede tener acceso a la memoria a la vez.
La ubicación de una memoria compartida no puede ser cambiada por otro proceso mientras una tarea lo accede.
Compartir los datos es rápido, el tiempo requerido para computar dos tareas es el mismo al tiempo de leer una sola ubicación de memoria.
Tipos de acceso a memoria en memoria compartida#
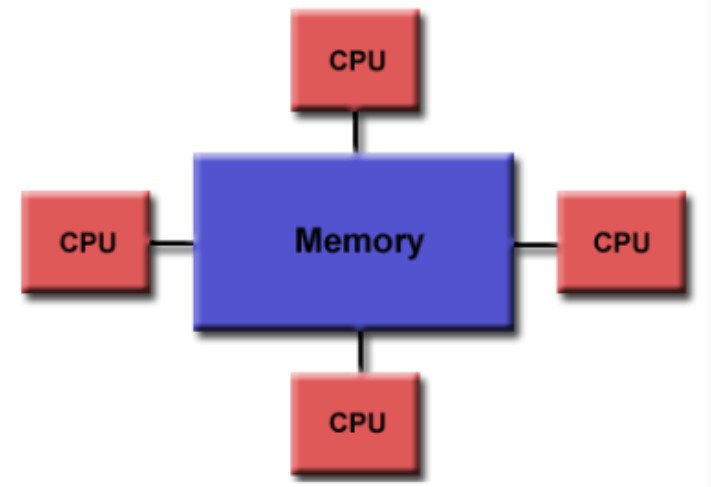
Acceso uniforme a la memoria (UMA - Uniform Memory Access) Es una arquitectura de computadora en la que todos los procesadores comparten un acceso igualitario y directo a la memoria principal del sistema. Esto implica que cada procesador puede acceder a cualquier ubicación en la memoria con la misma velocidad y latencia. A medida que se incrementa el número de procesadores, puede surgir un cuello de botella en el ancho de banda de la memoria, lo que limita el rendimiento del sistema.
UMA
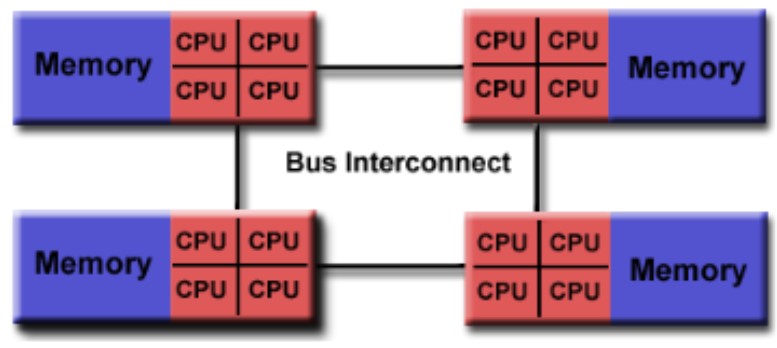
Acceso no-uniforme a la memoria (NUMA - Non-Uniform Memory Access) En una arquitectura NUMA, cada procesador dispone de su memoria local, y el acceso a la memoria remota (es decir, la memoria de otros procesadores) puede ser más lento en comparación con el acceso a la memoria local. Esta variabilidad en el acceso a la memoria depende de la ubicación de la memoria en relación con el procesador que la solicita. Esta arquitectura ofrece una escalabilidad superior para sistemas de alto rendimiento.
En una configuración NUMA, los procesadores se agrupan, y cada grupo posee su propia memoria física compartida. Los procesadores pueden acceder a su memoria local de manera más eficiente que a la memoria de otros grupos, lo que implica un acceso no uniforme a la memoria. Esta característica puede mejorar el rendimiento del sistema en aplicaciones que presentan patrones de acceso a la memoria enfocados en una región específica de esta última.
NUMA
Sin acceso remoto a la memoria (NORMA - No-Remote Memory Access) La arquitectura NORMA se distingue al combinar los elementos característicos de las arquitecturas UMA y NUMA. En NORMA, cada procesador disfruta de un acceso directo y uniforme a una región específica de la memoria, al tiempo que mantiene la capacidad de acceder a regiones remotas de la memoria mediante una red de interconexión de alta velocidad. Esta flexibilidad en el acceso a la memoria puede mejorar el rendimiento, especialmente en aplicaciones con patrones de acceso a la memoria más complejos.
Es importante aclarar que NORMA no representa una arquitectura en sí misma, sino más bien un concepto teórico. En este marco, cada procesador conservaría su propia memoria local y no tendría acceso a la memoria de otros procesadores, lo que excluye cualquier posibilidad de compartir memoria entre ellos.
Acceso solo a la memoria caché (COMA - Cache Only Memory Architecture) En una arquitectura COMA, cada procesador dispone de su propia memoria caché local, pero los datos compartidos se almacenan en una caché común. El acceso a esta memoria caché compartida puede ser más lento. Cuando un procesador necesita acceder a datos ubicados en la caché compartida de otro procesador, primero debe buscarlos en esta caché compartida y luego copiarlos a su propia caché local para su procesamiento.
La arquitectura COMA se caracteriza por que cada procesador tiene su propia memoria caché local, sin que exista una memoria física compartida entre ellos. La comunicación entre los procesadores se lleva a cabo mediante una red de interconexión de alta velocidad para compartir datos. Cuando un procesador necesita acceder a datos que no se encuentran en su caché local, los solicita a otros procesadores en la red. Los datos se almacenan en caché en los procesadores que los necesitan, lo que reduce la latencia de acceso a la memoria. Esta característica puede mejorar el rendimiento del sistema en aplicaciones que presentan patrones de acceso a la memoria centrados en un subconjunto específico de datos.
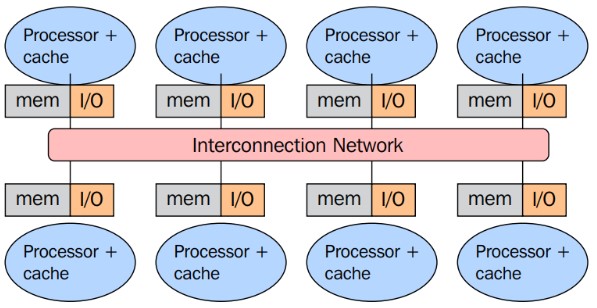
Memoria Distribuida: Sistemas Multicomputadores#
Small complete systems
Small complete systems
Protocolo de paso de mensajes
Protocolo de paso de mensajes
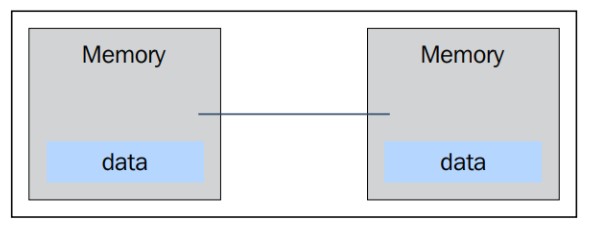
La memoria es físicamente distribuida entre los procesadores, cada memoria local es directamente accesible solo por su procesador.
Se logra la sincronización moviendo la data.
Subdividir los datos en la memoria local afecta el rendimiento, se debe hacer cuidadosamente.
Se usa el protocolo para que cada cpu pueda comunicarse con otra a través del intercambio de paquetes.
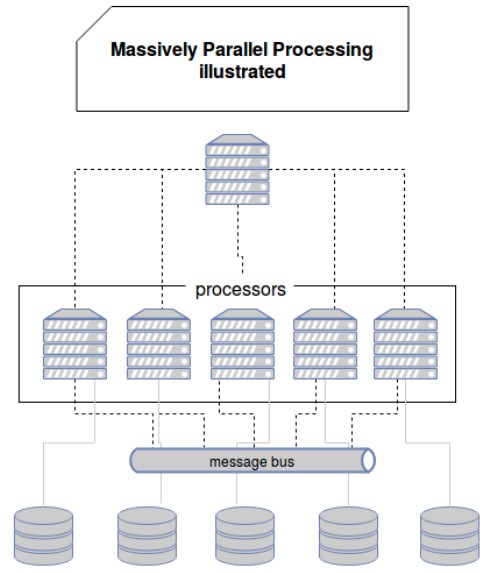
Procesamiento masivo paralelo
Muchos procesadores, conectados por una red de comunicación.
Procesamiento masivo paralelo
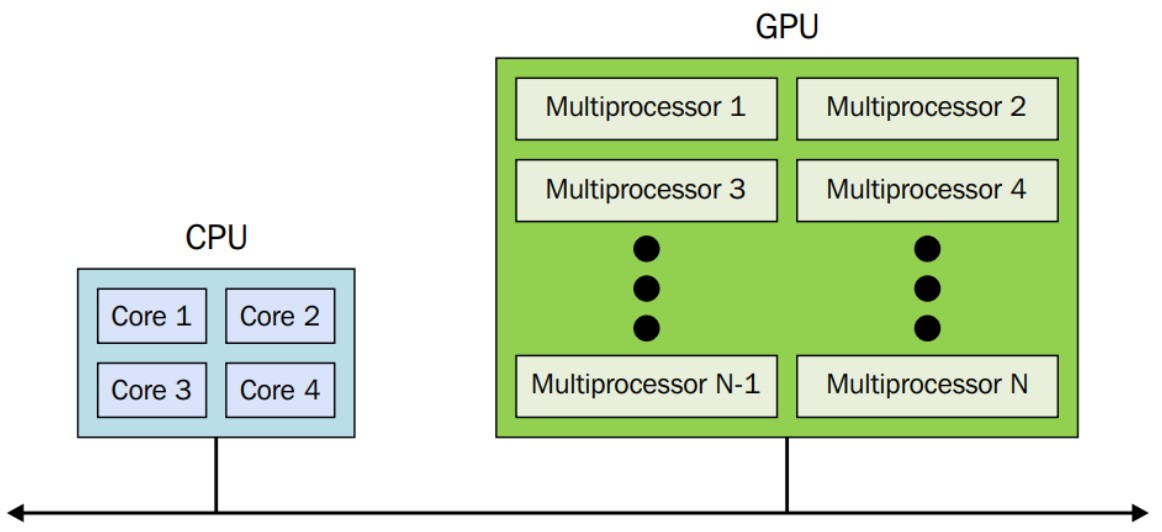
La arquitectura heterogénea
CUDA y OpenCL
La arquitectura heterogénea
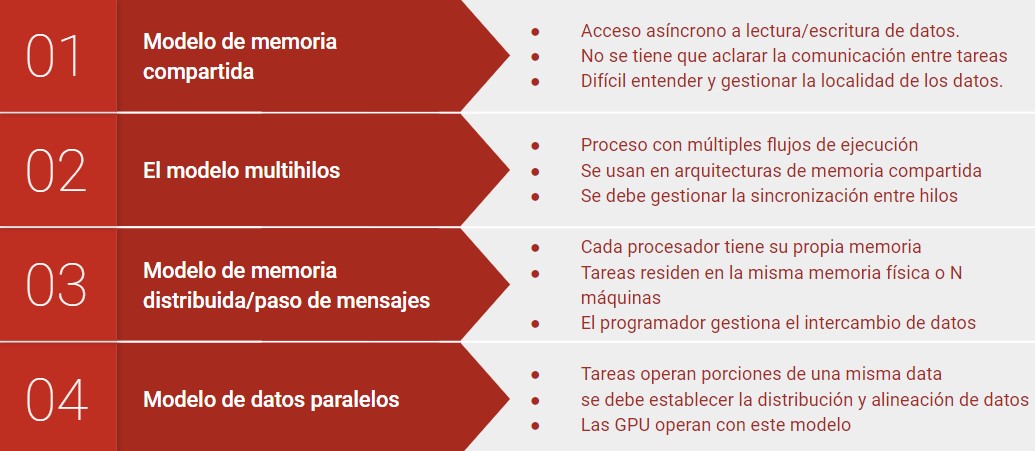
Modelos de programación paralela#
Existen como una abstracción de las arquitecturas de hardware
No existe un modelo mejor que otro, depende del problema
Paradigma del modelo de paso de mensajes#
El modelo MPI está diseñado con memoria distribuida, pero al ser modelos de programación paralela, también puede utilizarse en una máquina de memoria compartida.
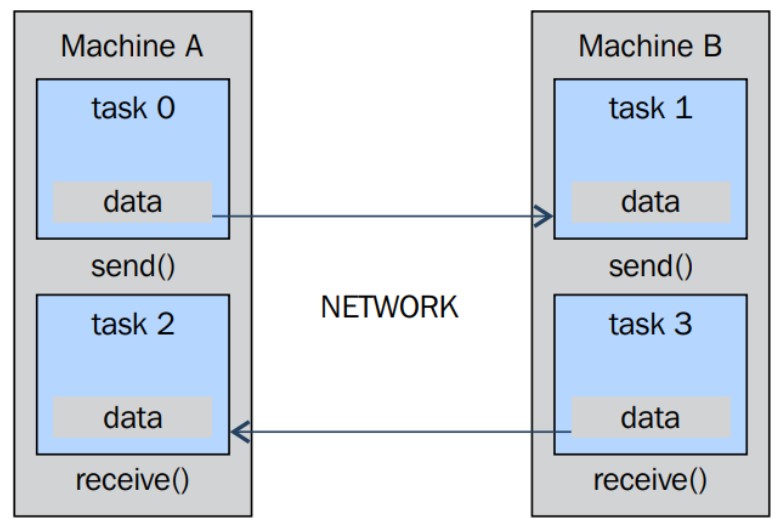
La grafica muestra que la comunicación entre máquinas puede ser de un procesador a otro desde una tarea a la otra y que cada máquina tiene la capacidad tanto de enviar como de recibir datos mediante el protocolo de pasos mensajes que se comunican a través de la red.
Modelo de datos paralelos#
Las GPU de la generación actual operan con alta eficiencia con los datos alineados
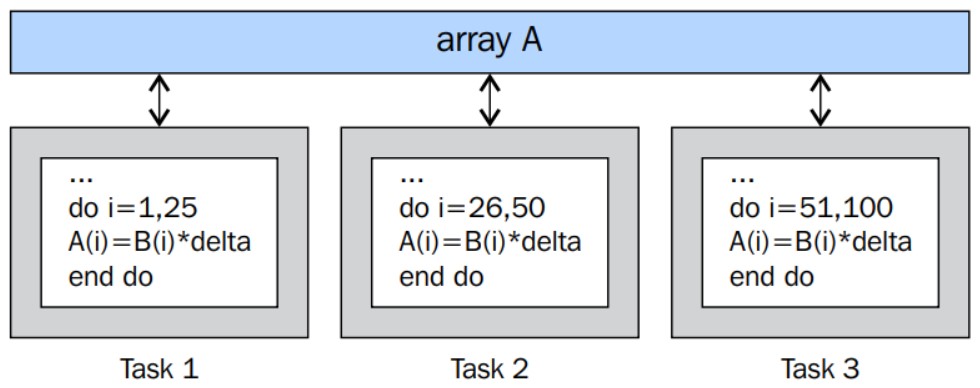
¿Cómo diseñar un programa paralelo ?#
Cuando se diseña un algoritmo es necesario tener en cuenta:
Los tiempos de las comunicaciones
Maximizar el procesamiento en cada nodo o unidad de procesamiento.
Los costes de implementar el algoritmo
Tiempos de planificación
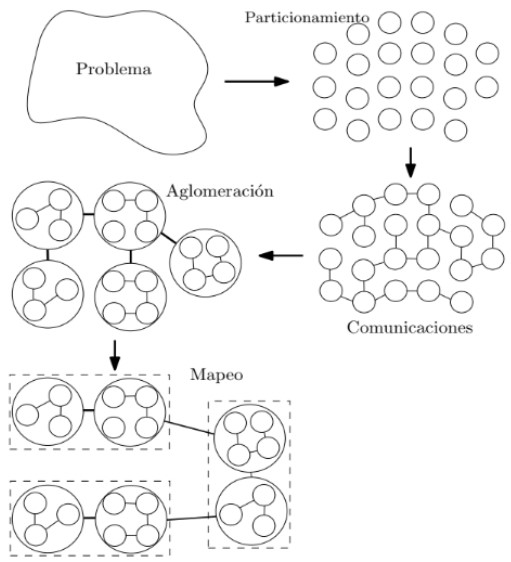
Metodología foster para diseño#
Consiste en cuatro etapas:
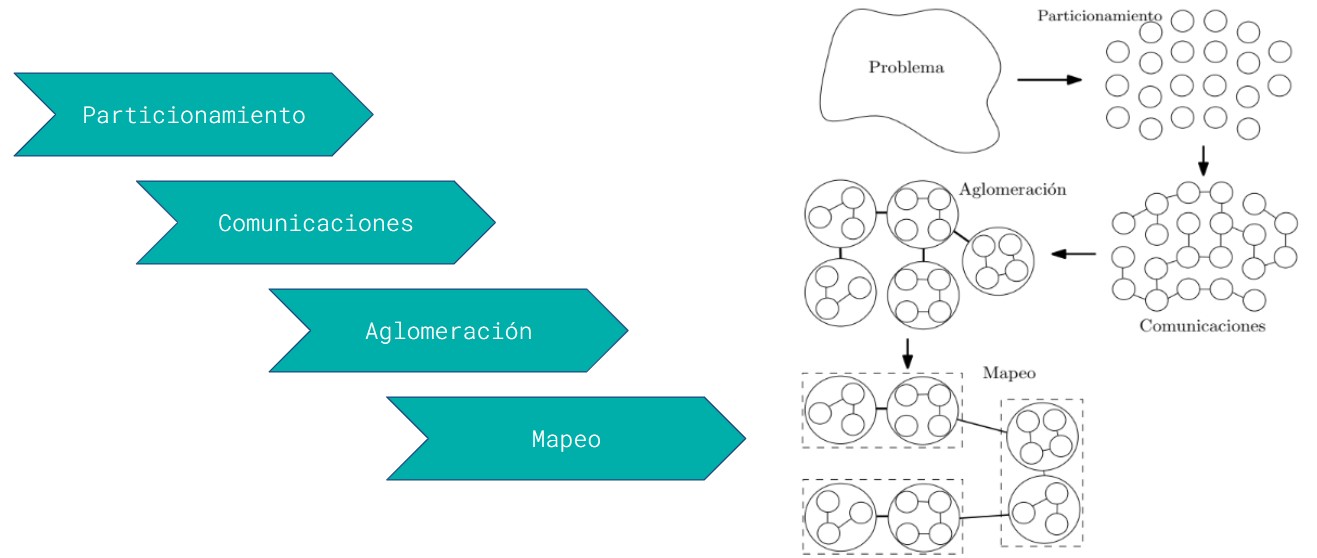
Particionamiento: En el dominio de los datos o de funciones.
Comunicaciones: Se hace por medio de distintos paradigmas tales como la memoria o paso de mensajes
Aglomeración: Las tareas o datos son agrupados teniendo en cuenta posibles dependencias
Mapeo: Los grupos son asignados a una unidad de procesamiento.